本案例源码是如何使用Spring Boot 和Kafka Streams实现基于SAGA 模式的分布式事务。
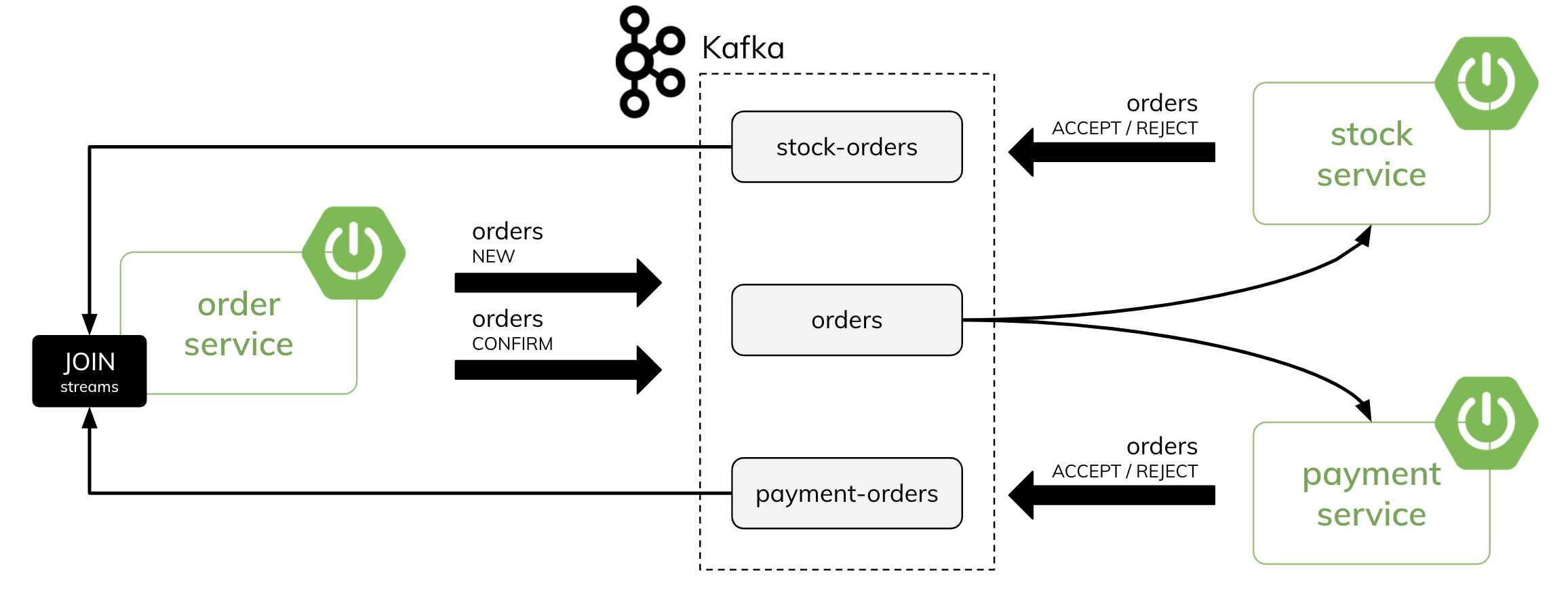
有三个微服务:
- 订单服务--它向Kafka主题发送订单事件,并协调分布式事务的过程
- 支付服务--它根据订单价格在客户账户上执行本地事务
- 库存服务--它根据订单中的产品数量在商店上执行本地事务
这是我们的架构图:
为了完全理解本示例中发生的情况,您还应该熟悉 Kafka Streams 线程模型。值得阅读以下文章,它以简洁的方式解释了它。首先,每个流分区是一个完全有序的数据记录序列,并映射到一个 Kafka 主题分区。这意味着,即使我们同时有多个订单与相同的产品相关,它们也会被顺序处理,因为它们具有相同的消息键(productId在这种情况下)。
此外,默认情况下,只有一个流线程处理所有分区。您可以在下面的日志中看到这一点。但是,有一些流任务充当最低级别的并行单元。因此,流任务可以独立并行处理,无需人工干预。
这是完全基于Kafka流的。我们不会使用任何SQL数据库:
当订单服务发送一个新的订单时,它的id是消息键。通过Kafka流,我们可以改变流中的一个消息键。它的结果是创建新的主题和重新分区。有了新的消息键,我们可以只对特定的customerId或productId进行计算。这种计算的结果可以保存在持久性存储中。
例如,当你在调用count()或aggregate()等有状态的操作时,Kafka会自动创建和管理这样的状态存储。我们将聚合与特定客户或产品相关的订单。
现在,让我们详细考虑一下支付服务的场景。在传入的订单流中,支付服务调用selectKey()操作。它将键从订单的id改为订单的customerId。然后它通过新的键对所有的订单进行分组,并调用aggregate()操作。在aggregate()方法中,它根据订单的价格和状态(无论是新订单还是确认订单)计算出可用金额和保留金额。如果客户账户上有足够的资金,它将发送ACCEPT订单到payment-order主题。否则,它将发送REJECT订单。然后,订单服务流程通过订单的ID加入来自payment-order和inventory-order的流进行响应。作为结果,它发送一个确认或回滚订单。

用Kafka流进行聚合
让我们从支付服务开始。KStream的实现在这里并不复杂。
@Bean
public KStream<Long, Order> stream(StreamsBuilder builder) {
JsonSerde<Order> orderSerde = new JsonSerde<>(Order.class);
JsonSerde<Reservation> rsvSerde = new JsonSerde<>(Reservation.class);
KStream<Long, Order> stream = builder
.stream("orders", Consumed.with(Serdes.Long(), orderSerde))
.peek((k, order) -> LOG.info("New: {}", order));
KeyValueBytesStoreSupplier customerOrderStoreSupplier =
Stores.persistentKeyValueStore("customer-orders");
stream.selectKey((k, v) -> v.getCustomerId()) // (1)
.groupByKey(Grouped.with(Serdes.Long(), orderSerde)) // (2)
.aggregate(
() -> new Reservation(random.nextInt(1000)),
aggregatorService,
Materialized.<Long, Reservation>as(customerOrderStoreSupplier)
.withKeySerde(Serdes.Long())
.withValueSerde(rsvSerde)) // (3)
.toStream()
.peek((k, trx) -> LOG.info("Commit: {}", trx));
return stream;
}
|
第一步(1),我们调用selectKey()方法,获得订单对象的customerId值作为一个新的键。然后我们调用groupByKey()方法(2)来接收KGroupedStream作为结果。当我们拥有KGroupedStream时,我们可以调用其中的一个计算方法。在这种情况下,我们需要使用aggregate(),因为我们有一个比简单计数更高级的计算方法(3)。
最后两步只是为了打印计算后的值。
然而,上面可见的代码片段中最重要的一步是在aggregate()方法中调用的类。aggregate()方法需要三个输入参数。其中第一个参数表示我们的计算对象的起始值。该对象代表客户账户的当前状态。它有两个字段: amountAvailable 和 amountReserved。为了说明问题,我们使用该对象而不是在客户账户上存储可用和保留金额的实体。每个客户由Kafka KTable中的customerId(键)和Reservation对象(值)表示。只是为了测试的目的,我们要生成一个介于0和1000之间的随机数,作为 amountAvailable 的起始值。
public class Reservation {
private int amountAvailable;
private int amountReserved;
public Reservation() {
}
public Reservation(int amountAvailable) {
this.amountAvailable = amountAvailable;
}
// GETTERS AND SETTERS ...
}
|
好吧,让我们来看看我们的聚合方法。它需要实现Kafka Aggregate接口及其方法apply()。它可以处理三种类型的订单。其中一种是订单的确认(1)。它确认的是分布式交易,所以我们只需要通过从amountReserved字段中减去订单的价格来取消一个预订。另一方面,在回滚的情况下,我们需要用订单的价格来增加可用金额的值,并相应减少保留金额的值(2)。最后,如果我们收到一个新的订单,如果客户账户上有足够的资金,我们需要执行保留,否则,拒绝一个订单。
Aggregator<Long, Order, Reservation> aggregatorService = (id, order, rsv) -> {
switch (order.getStatus()) {
case "CONFIRMED" -> // (1)
rsv.setAmountReserved(rsv.getAmountReserved()
- order.getPrice());
case "ROLLBACK" -> { // (2)
if (!order.getSource().equals("PAYMENT")) {
rsv.setAmountAvailable(rsv.getAmountAvailable()
+ order.getPrice());
rsv.setAmountReserved(rsv.getAmountReserved()
- order.getPrice());
}
}
case "NEW" -> { // (3)
if (order.getPrice() <= rsv.getAmountAvailable()) {
rsv.setAmountAvailable(rsv.getAmountAvailable()
- order.getPrice());
rsv.setAmountReserved(rsv.getAmountReserved()
+ order.getPrice());
order.setStatus("ACCEPT");
} else {
order.setStatus("REJECT");
}
template.send("payment-orders", order.getId(), order);
}
}
LOG.info("{}", rsv);
return rsv;
};
|
使用Kafka流表的状态存储
库存服务的实现与支付服务非常相似。不同的是,我们计算的是库存产品的数量而不是客户账户上的可用资金。
Aggregator<Long, Order, Reservation> aggrSrv = (id, order, rsv) -> {
switch (order.getStatus()) {
case "CONFIRMED" -> rsv.setItemsReserved(rsv.getItemsReserved()
- order.getProductCount());
case "ROLLBACK" -> {
if (!order.getSource().equals("STOCK")) {
rsv.setItemsAvailable(rsv.getItemsAvailable()
+ order.getProductCount());
rsv.setItemsReserved(rsv.getItemsReserved()
- order.getProductCount());
}
}
case "NEW" -> {
if (order.getProductCount() <= rsv.getItemsAvailable()) {
rsv.setItemsAvailable(rsv.getItemsAvailable()
- order.getProductCount());
rsv.setItemsReserved(rsv.getItemsReserved()
+ order.getProductCount());
order.setStatus("ACCEPT");
} else {
order.setStatus("REJECT");
}
// (1)
template.send("stock-orders", order.getId(), order)
.addCallback(r -> LOG.info("Sent: {}",
result != null ? result.getProducerRecord().value() : null),
ex -> {});
}
}
LOG.info("{}", rsv); // (2)
return rsv;
};
|
聚合方法的实现也与支付服务非常相似。然而,这一次,让我们专注于另一件事。一旦我们处理了一个新的订单,我们就需要向stock-orders主题发送一个响应。我们使用KafkaTemplate来做这个。在支付服务的情况下,我们也会发送一个响应,但要发送到支付-订单主题。KafkaTemplate的发送方法并没有阻塞线程。它返回ListenableFuture对象。我们可以给发送方法添加一个回调,使用它和发送消息后的结果(1)。最后,让我们记录一下预订对象的当前状态(2)。
之后,我们也在记录保留对象的值(1)如下。为了做到这一点,我们需要将KTable转换为KStream,然后调用peek方法。这个日志是在Kafka Streams提交源主题中的偏移量后才打印的。
@Bean
public KStream<Long, Order> stream(StreamsBuilder builder) {
JsonSerde<Order> orderSerde = new JsonSerde<>(Order.class);
JsonSerde<Reservation> rsvSerde = new JsonSerde<>(Reservation.class);
KStream<Long, Order> stream = builder
.stream("orders", Consumed.with(Serdes.Long(), orderSerde))
.peek((k, order) -> LOG.info("New: {}", order));
KeyValueBytesStoreSupplier stockOrderStoreSupplier =
Stores.persistentKeyValueStore("stock-orders");
stream.selectKey((k, v) -> v.getProductId())
.groupByKey(Grouped.with(Serdes.Long(), orderSerde))
.aggregate(() -> new Reservation(random.nextInt(100)), aggrSrv,
Materialized.<Long, Reservation>as(stockOrderStoreSupplier)
.withKeySerde(Serdes.Long())
.withValueSerde(rsvSerde))
.toStream()
.peek((k, trx) -> LOG.info("Commit: {}", trx)); // (1)
return stream;
}
|
运行代码
如果你发送测试订单会发生什么?让我们看看日志。你可以看到处理消息和偏移提交之间的时间差。在你的应用程序正在运行或被优雅地停止之前,你不会有任何问题。但如果你,比如说,用kill -9命令杀死这个进程?重新启动后,我们的应用程序将再次收到相同的消息。由于我们使用KafkaTemplate来向stock-orders主题发送响应,我们需要尽快提交偏移。
我们可以做什么来避免这样的问题呢?我们可以覆盖commit.interval.ms Kafka Streams属性的默认值(30000)。如果你把它设置为0,在处理完成后立即提交。spring.kafka:
streams:
properties:
commit.interval.ms: 0
|
另一方面,我们也可以将processing.guarantee属性设置为exact_once。它还将commit.interval.ms的默认值改为100ms,并启用生产者的idempotence。你可以在Kafka文档中阅读更多关于它的内容。
spring.kafka:
streams:
properties:
processing.guarantee: exactly_once
|