Alex Petrov 是 Apple 的一名软件工程师。他写了一本关于 Database Internals 的精彩书籍,深入探讨了分布式数据系统的工作原理。
我们将总结他关于数据库管理系统 (DBMS) 背后架构的书中的一小段内容。
概括
您可能使用过像 Postgres、MySQL 等这样的 DBMS。
它们提供了一个非常有用的抽象,您可以在应用程序中使用它来存储和(以后)检索数据。
所有 DBMS 都提供了一个 API,您可以通过某种类型的查询语言使用该 API 来存储和检索数据。
它们还围绕如何存储/检索这些数据提供了一组保证。这种保证的几个例子是
- 耐用性- 保证在 DBMS 崩溃时您不会丢失任何数据
- 一致性- 写入数据后,所有后续读取是否总是给出数据的最新值?(这对于分布式数据库很重要)
- 读/写速度- IOPS是存储设备上每秒输入和输出操作的标准度量。
各种数据库管理系统的体系结构根据它们的保证和设计目标而有很大差异。为OLTP使用而设计的数据库的设计方式与为OLAP设计的数据库不同。
内存 DBMS(主要将数据存储在内存中并使用磁盘进行恢复和日志记录)的设计也将不同于基于磁盘的 DBMS(主要将数据存储在磁盘上并使用内存进行缓存)。
但是,数据库在其各种架构中都有一些共同的主题,了解这些主题可以为它们的工作方式提供有用的模型。
下图可以描述一般架构。
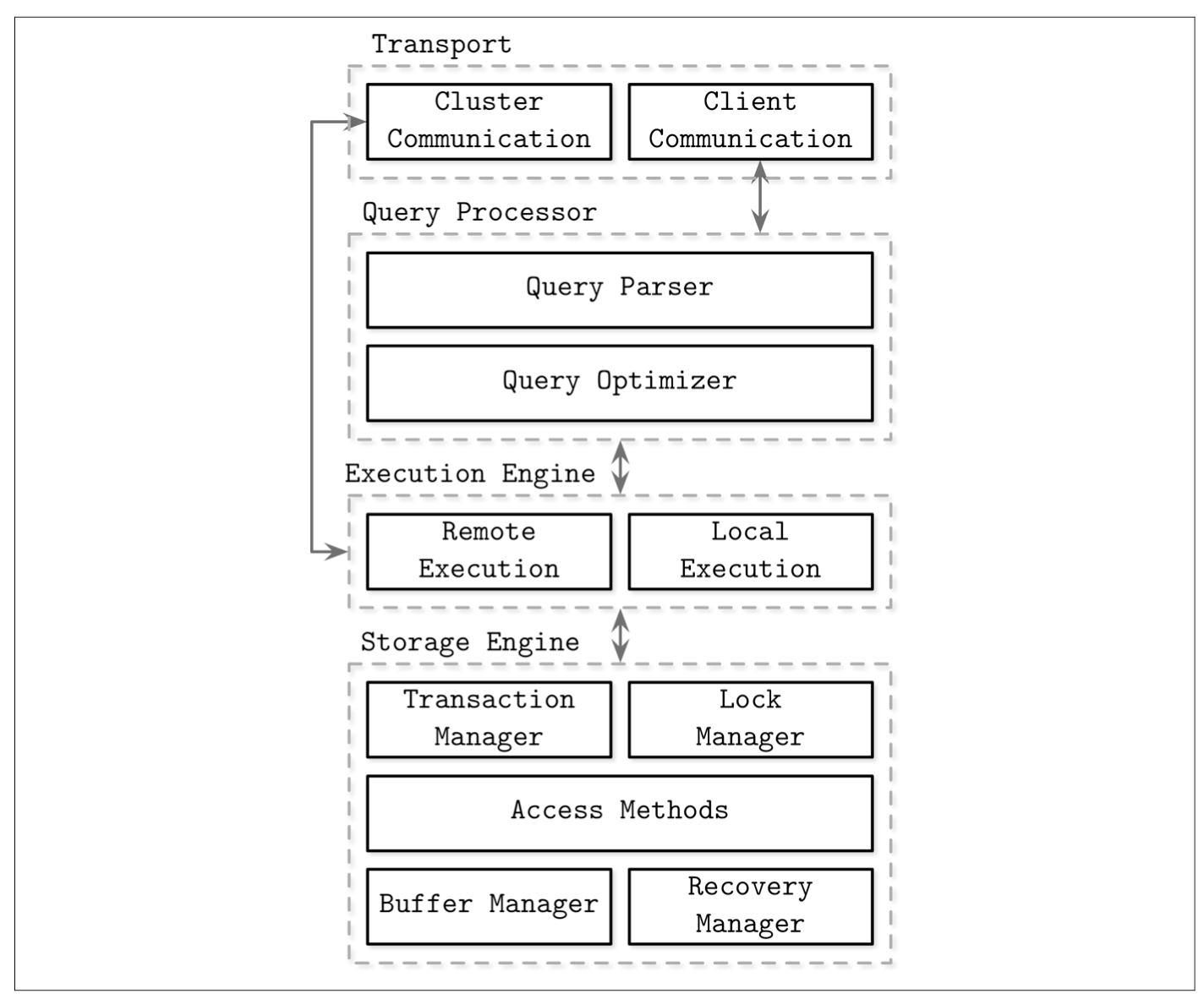
数据库管理系统使用客户端/服务器模型。您的应用程序是客户端,DBMS 是服务器(托管在同一台机器上或不同的机器上)。
传输系统Transport是 DBMS 接受客户端请求的方式。
客户端请求以数据库查询的形式出现,通常以某种类型的查询语言(例如 SQL)表示。
收到查询后,传输系统会将查询传递给查询处理器。
查询处理器将首先解析查询(例如使用抽象语法树)并确保它是有效的。
检查有效性意味着确保查询有意义(所有命令都被识别,访问的数据是有效的,等等),并且客户端被正确地允许访问/修改他们请求的数据。
如果查询无效,则数据库将向客户端返回错误。
否则,解析后的查询将传递给查询优化器。
优化器将首先消除查询的冗余部分,然后使用内部数据库统计信息(索引基数、近似交集大小等)来找到执行查询的最有效方式。
对于分布式数据库,优化器还将考虑数据放置,例如集群中的哪个节点保存数据以及与传输相关的成本。
优化器的输出是描述执行查询的最佳方法的执行计划。该计划也称为查询计划或查询执行计划。
该执行计划被传递给执行该计划的执行引擎。
当您使用分布式数据库时,执行计划可能涉及远程执行(对存储在不同机器上的数据发出网络请求)。
否则,它只是本地执行(对本地存储的数据执行查询)。
远程执行涉及集群通信,其中 DBMS 与数据库集群中的其他机器通信并向它们发送数据请求。如上图所示,这是传输层的一部分。
本地执行涉及与存储引擎对话以获取数据。
存储引擎是数据库中直接负责在内存和磁盘中存储、检索和管理数据的组件。
存储引擎通常提供一个简单的数据操作 API(允许 CRUD 功能)并包含有关如何操作数据的实际细节的所有逻辑。
存储引擎的示例包括BerkeleyDB、LevelDB、RocksDB等。
数据库通常允许您选择正在使用的存储引擎。
例如,MySQL 有多种存储引擎可供选择,包括 RocksDB 和 InnoDB。
存储引擎由几个组件组成
事务管理器- 负责创建事务对象并管理它们的原子性(整个事务成功或回滚)。
锁管理器- 事务将同时执行,因此锁管理器管理每个事务正在访问的数据库对象上的锁(并在事务提交或回滚时释放这些锁)。
访问方法- 这些管理访问、压缩和组织磁盘上的数据。访问方法包括堆文件和存储结构,例如 B 树。
缓冲区管理器- 此管理器将数据页缓存在 RAM 中,以减少对磁盘的访问次数。
恢复管理器- 维护操作日志并在发生故障时恢复系统状态。
不同的存储引擎在这些组件之间做出不同的权衡,从而导致压缩、缩放、分区、速度等方面的性能不同。