分区和分桶用于最大化收益,同时最小化不利影响。它可以减少洗牌的开销、序列化的需要和网络流量。最后,它提高了性能、集群利用率和成本效益。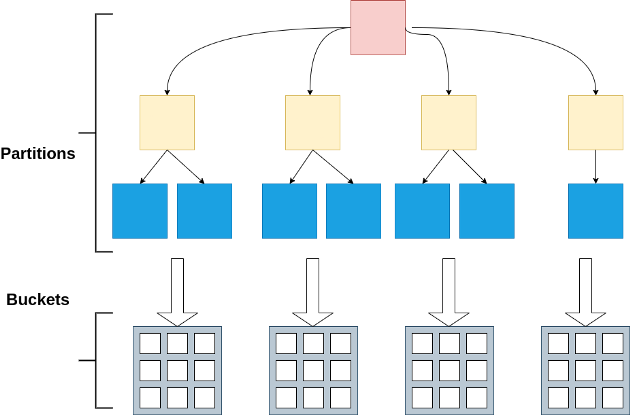
Spark 中的分区
分区的主要思想是优化作业性能。作业性能可以通过确保每个工作负载平均分配给每个 Spark 执行器来获得。不幸的是,没有单一的经验法则,但有几件事我们需要注意。
为什么要分区数据?
分区有助于本地化数据并减少跨网络节点的数据混洗,减少网络延迟,这是转换操作的主要组成部分,从而减少完成时间。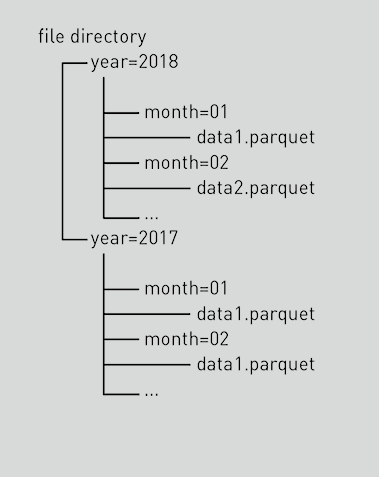
首先,我们需要确保没有没有工作的执行者,并且没有一个执行者由于工作分配不平衡而成为瓶颈。
- 避免使用大文件,因为每个 Spark 执行器一次只能处理一个分区,如果我们的分区比 Spark 执行器少,剩余的执行器将保持空闲状态,我们无法充分利用现有资源。
- 避免拥有大量小文件,因为这需要更多的网络通信来访问位于数据湖(例如 AWS S3、Google Cloud Storage 等)上的每个小文件,并且计算可能需要在磁盘空间上进行大量数据混洗。
一个好的分区策略了解数据及其结构和集群配置。糟糕的分区会导致糟糕的性能,主要是在 3 个领域:
- 关于您的集群大小的分区太多,您将无法有效地使用您的集群。例如,它会产生密集的任务调度。
- 关于集群大小的分区不足,您将不得不处理内存和 CPU 问题:内存是因为您的执行程序节点必须将大量数据放入内存(可能导致 OOM 异常),而 CPU 因为跨集群的计算将不平等。
- 分区中的数据可能会出现偏差。当在这些分区中执行 Spark 任务时,它们将分布在执行器插槽和 CPU 上。如果您的分区在数据量方面不平衡,则某些任务与其他任务相比运行时间更长,并且会减慢任务的全局执行时间(并且一个节点可能会比其他节点消耗更多的 CPU)。
如何确定分区键?
- 选择低基数列作为分区列(因为将为每个分区值组合创建一个 HDFS 目录)。一般来说,分区组合的总数应该小于50K。(例如,不要使用 roll_no、employee_ID 等分区键,而是使用 state code、country code、geo_code 等)
- 选择过滤条件中经常使用的列。
- 最多使用 2 个分区列,因为每个分区列都会创建一个新的目录层。
如何选择分区数:
- 下限— 2 X 集群中可供应用程序使用的核心数
- 上限— 任务需要 100+ 毫秒才能执行。如果花费的时间更少,那么您的分区数据太小,您的应用程序可能会花费更多时间来安排任务。
让我们从了解 PySpark 中存在的不同方法开始
- 重新分区管理分区的第一种方法是repartition操作。重新分区是减少或增加集群中数据将被拆分的分区数量的操作。此过程涉及完全洗牌。因此,很明显重新分区是一个昂贵的过程。在典型的场景中,大部分数据应该被序列化、移动和反序列化。
重新分区 = df.repartition(8)
除了直接指定分区数之外,您还可以传入要对数据进行分区的列的名称。
重新分区 = df.repartition('国家')
- 合并管理分区的第二种方法是coalesce. 此操作减少了分区的数量并避免了 full shuffle。执行器可以安全地将数据保留在最少数量的分区上,仅从冗余节点移动数据。因此,如果您需要减少分区的数量,最好使用合并而不是重新分区。
合并 = df.coalesce(2)
- PartitionBypartitionBy(cols)用于定义数据的文件夹结构。但是,对于要创建的分区数量没有具体控制。与coalesce和repartition函数不同,partitionBy影响文件夹结构,对将要创建的分区文件的数量和分区大小没有直接影响。
green_df \ .write \ .partitionBy("pickup_year", "pickup_month") \ .mode ("overwrite") \ .csv("data/partitions/partitionBy.csv", header=True)
持有和传播分区器的 RDD 操作是 -
- 加入
- 左外连接
- 右外连接
- GroupByKey
- ReduceByKey
- 按键折叠
- 种类
- 分区依据
- 按键折叠
笔记:
1. 不要按基数高的列进行分区。2. 按特定列进行分区,主要用于 filter 和 groupBy 操作。3. 即使没有最佳数字,建议每个分区文件大小保持在 256MB 到 1GB 之间。4. 如果要增加分区数,请使用repartition()(执行完全随机播放)。5. 如果要减少分区数,请使用coalesce()(最小化随机播放)。6. 默认分区数等于机器的CPU核数。7. GroupByKey ,ReduceByKey — 默认情况下,此操作使用带有默认参数的哈希分区。
什么是分区器?
分区器是一个对象,它定义了键值对 RDD 中的元素如何按键分区,将每个键映射到从 0 到 numPartitions - 1 的分区 ID。
它在输出端捕获数据分布。在分区器的帮助下,调度器可以优化未来的操作。分区器合约确保给定键的记录必须驻留在单个分区上。我们应该选择一个分区器用于类似 cogroup 的操作。如果任何一个 RDD 已经有一个分区器,我们应该选择那个。否则,我们使用默认的 HashPartitioner。
Spark 中有不同类型的分区器:
a) Hash Partitioner :- 以这样的方式分割我们的数据,使得具有相同散列的元素(可以是键、键或函数)将在同一个分区中。我们还可以传递想要的分区数,以便最终确定的分区为 hash % numPartitions。请注意,如果 numPartitions 大于具有相同散列的组数,则会有空分区。使用示例:df.repartiton(10, 'class_id')
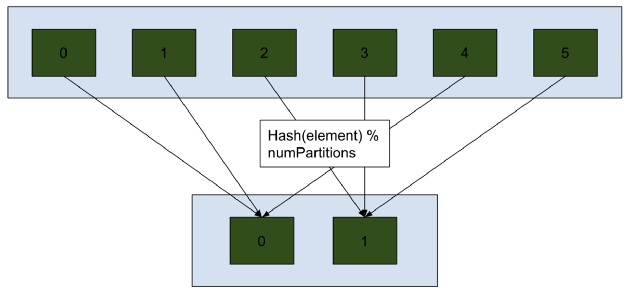
哈希分区可以使分布式数据倾斜。
b) Range Partitioner : - 与哈希分区非常相似,只是它基于一系列值。由于性能原因,此方法使用抽样来估计范围。因此,输出可能不一致,因为采样可以返回不同的值。样本大小可以通过配置值来控制spark.sql.execution.rangeExchange.sampleSizePerPartition。使用示例:df.repartitionByRange(10, 'grade')
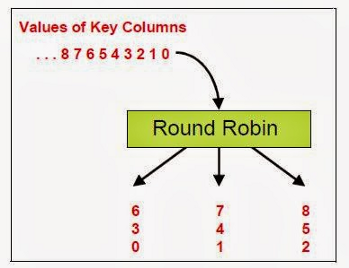
c) 循环分区:将数据从源分区数以循环方式分配到目标分区数,以保持结果分区之间的均匀分布。由于重新分区是一个shuffle操作,如果我们不传递任何值,它将使用上面提到的配置值来设置最终的分区数。使用示例:df.repartition(10).
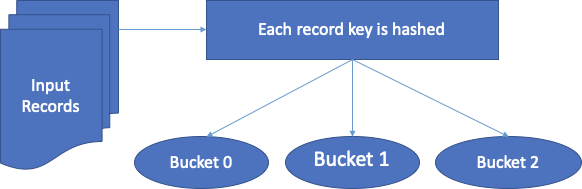
Spark 中的分桶
Bucketing是 Spark 和 Hive 中用于优化任务性能的一种技术。在分桶桶(集群列)中确定数据分区并防止数据混洗。根据一个或多个分桶列的值,将数据分配给预定义数量的桶。
分桶有两个主要好处:
- 改进的查询性能:在连接时,我们可以在相同的分桶列上明确指定桶的数量。由于每个存储桶包含相同大小的数据,因此映射端连接的性能优于存储桶表上的非存储桶表。在 map-side join 中,左侧表存储桶将准确知道右侧存储桶包含的数据集,以便以结构良好的格式执行表联接。
- 改进的采样:数据已经被分成更小的块,因此采样得到了改进。
何时使用桶列
- 表大小很大(> 200G)。
- 该表具有高基数列,这些列经常用作过滤和/或连接键。
- 中等大小的表,但主要用于连接一个巨大的桶化表,桶化它仍然是有益的
- 排序合并连接(没有存储桶)由于随机播放而不是由于数据倾斜而变慢
如何配置存储桶列
- 选择高基数列作为桶列。
- 尽量避免数据倾斜。
- 至少 500 个桶(因为小桶数会导致并行执行不佳)。
- 排序桶是可选的,但强烈推荐。
如何在 Spark 中创建数据桶
- 下面是在 SparkAPI 中创建存储桶的示例。bucketBy是在 spark 中创建存储桶的函数。我们需要将桶的信息保存在某处,所以这里需要使用saveAsTable来保存桶表的元数据信息。
# n 是要创建的桶数df.write.mode(“save_mode”).option(“path”, “s3 path/hdfs path”) \.bucketBy(n, 'col1', 'col2'..) \.sortBy('col1', ' col2') \.saveAsTable('table_name', format='parquet')df = spark.table('table_name')
- 在上面的示例中,我们使用了 bucketBy 和 sortBy,因为在某些情况下我们有多个连接键,并且希望将整数键放在 bucketBy 中,将字符串键放在 sortBy 中。当我们做数据桶时,sortBy 是可选的。
- 可以根据数据大小和我们对数据运行的查询来决定存储桶大小的数量。通常,每个存储桶可能更喜欢 100 MB 到 200 MB。
- 存储桶表将使用以下命名约定将表保存在路径中。
如何在 Spark 上启用分桶?
默认情况下启用分桶。或者,您可以在 Spark Shell 或属性文件中设置以下属性。
设置 spark.sql.sources.bucketing.enabled=true
Spark 中对表进行分桶的优点
- 优化表。
- 使用预洗牌分桶表时优化联接。
- 当您在分桶列上定义谓词时,启用更有效的查询。
- 优化了对表数据的访问。在桶列上使用 WHERE 条件时,您将最小化给定查询的表扫描。
- 将数据均匀分布在不同的存储桶中,从而实现对表数据的最佳访问。
转换列表
以下转换将受益于分桶:
- 加入
- 清楚的
- 通过...分组
- 减少
Spark Bucket 的限制
Spark Bucketing 有其自身的局限性,我们在创建分桶表以及将它们连接在一起时需要非常小心。
为了优化连接并在 Spark 中使用分桶,我们需要确保以下几点:
- 两个表都使用相同数量的存储桶进行存储。如果加入表中的桶号不同,则不会应用预洗牌。
- 两个表都存储在同一列上以进行连接。由于数据是根据给定的分桶列进行分区的,如果我们不使用同一列进行连接,那么您就没有使用分桶,它会影响性能。
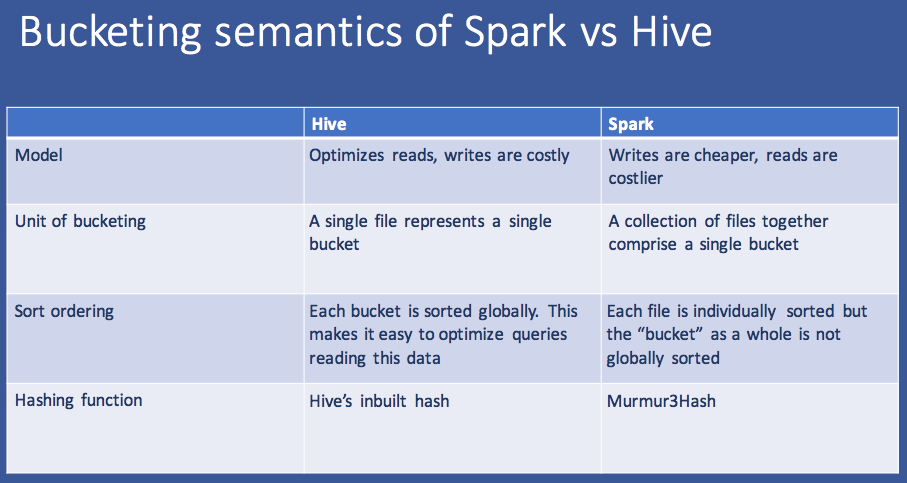
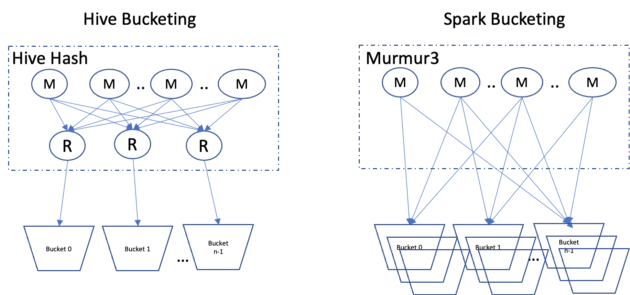
Spark 分桶与 Hive 分桶有何不同?
在 Hive 中,我们需要根据需要创建文件数量的 reducer。
而在 Spark 分桶中,我们没有减速器。因此,它最终会根据任务的数量创建 n 个文件。