Snowflake 和 Debezium 在现代数据堆栈中获得了当之无愧的地位,现在很容易找到有关使用这些技术的在线资源。在这篇博客中,我们更进一步,回顾了我们(在 Shippeo)使用 Debezium 近乎实时地将大规模数据复制到 Snowflake 中学到的经验教训。
数据是 Shippeo 业务的血液。作为供应链中的数据聚合器,新鲜可靠的数据对于提供准确的 ETA 预测和性能洞察至关重要。
这不是教程。我们不会解释使用 Debezium 和 Kafka 将数据复制到 Snowflake 的不同步骤。在线可用的资源以及官方文档已经足够了。我们想在这篇文章中与您分享的是蛋糕上的樱桃;如果您想超越这些技术的简单 PoC 到在生产中实际实施可靠系统,该做什么和不该做什么。
整体架构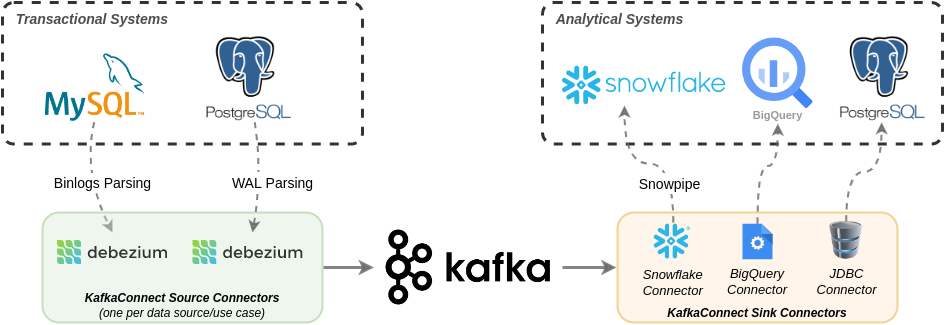
基于 KafkaConnect(Debezium)的数据复制管道概述
我们使用Debezium,一个优秀的开源工具来执行基于日志的变更数据捕获;这是使用 OLTP 数据库的日志来跟踪和流式传输数据库中的所有更改(作为事件)的过程。这些事件近乎实时地发送到 Kafka,供多个 Kafka Sink 连接器使用,并推送到下游的 OLAP 系统。
提前考虑优化Kafka使用
在开发周期开始时,您可以做出的决定很少会对您的 Kafka 使用产生巨大影响。例如,当在具有大型表的同一个 Kafka 集群中使用多个 Debezium 连接器时,给定的 Kafka 节点用尽磁盘空间或初始 Debezium 快照需要数天才能完成的情况并不少见。这里有一些建议:
- 使用正确的保留策略手动创建 Kafka 主题:如果 Kafka 主题不存在,Debezium 可以自动创建它们。最好避免这种情况。在初始化 Debezium 之前手动创建 Kafka 主题可以让您控制每个主题的配置。例如,使用保留策略“Compact+Delete”对于 Debezium 使用的主题特别有用,因为它允许 Kafka 仅保留给定 Kafka Key 的最新消息,从而减少存储使用量。如果您有托管的 Kafka 服务,您可以使用脚本或使用 Terraform 自动创建这些主题。这也将允许您根据相应表的大小微调每个主题的分区数(请参阅下一点)。
- 增加最大表对应的 Kafka 主题的分区数量:这将增加 Kafka 中写入操作的并行度,并大大加快大表的初始快照。
- 将 AVRO 序列化与 Schema 注册表一起使用:而不是默认的 JSON 序列化。这将减少消息大小并节省存储使用量。这里值得一提的是,一些 Kafka Sink 连接器仅支持带有 Schema 注册表的 AVRO,例如 BigQuery 接收器连接器。所以最好提前准备。
为每个下游系统创建一个独立的 Debezium 连接器
假设您的数据科学家(使用 Snowflake 训练模型)和数据分析师(使用 BigQuery 构建一些内部报告)都需要 MySQL 中的某些表。
由于将相同的源表复制到 2 个不同的目标,您可能想定义一个 Debezium 源连接器,其数据由 2 个不同的 Sink 连接器(在本例中为 Snowflake + BQ)使用。这会在数据消费者之间产生耦合,出于以下几个原因,这是一个坏主意,包括:
- 如果一个消费者需要重新初始化某个表的快照,另一个消费者也将被迫使用这个快照。
- 如果一个消费者只需要某个大表的几列,而另一个消费者需要所有列,那么第一个消费者将被迫消费包含所有列的有效负载。
小心在 PostgreSQL 中使用 Debezium
第一次在 PostgreSQL 上设置 Debezium 可能会很棘手。Debezium通过“出版物”和“复制槽”使用 PostgreSQL 的WAL (预写日志)。所有这些都需要正确配置才能使 Debezium 运行。虽然 Debezium 可以自动创建它们(如文档中所述),但它需要赋予 Debezium 的 DB 用户对复制表的所有权特权。这不仅是一种反模式,而且从组织的角度来看甚至可能是不可能的,因为这些表很可能归您公司的其他软件开发团队所有,而不是数据工程师。
更好的选择是由表所有者或超级用户手动创建这些复制槽。这篇文章很好地解释了这一点。另一个关于 Debezium with PostgreSQL 是Ashhar Hasan的文章。
对 WAL 大小失控的情况非常谨慎。这可能发生在此处解释的高流量/低流量情况下,或者在一些手动测试后未使用复制槽。例如,如果您的 PostgreSQL 在启用自动扩展的 GCP 的 Cloud SQL 上,那么不断增长的 WAL 将扩展数据库的存储(和成本),并且到目前为止,它不可能再次缩减。当您发现问题时,唯一的补救措施是删除数据库并重新创建它。
注意主要错误KAFKA-8713
长话短说,如果有一个定义了默认值的可空数据库列,那么 KafkaConnect 会在序列化过程中错误地用默认值替换该列的任何空值。此错误会影响 Debezium 下游,因为它依赖于 KafkaConnect 序列化。
尽管此错误会损害此类列的数据完整性,但它似乎仍然没有很快得到修复- 在撰写本文时 -因为它需要 KIP (Kafka 改进提案)。
对Snowflake 的思考
Snowflake 的好处在于它工作可靠。您需要担心的事情并不多(除了您的信用使用账单)。为了让这个账单不那么痛苦,您可以优化 Snowflake Kafka 连接器中的缓冲区配置,以便更明智地使用 Snowpipe。
具有默认值的Snowflake Kafka接收器连接器缓冲区配置
值得提出一个问题,即您需要多快将数据从 Kafka 中刷新(从而触发 Snowpipe)。每个数据管道都可以有不同的数据新鲜度要求。应该对缓冲区配置进行一些实验,以找到成本和数据新鲜度之间的正确权衡。
Snowflake Kafka Sink 连接器的一个不便之处在于它将数据推送到 Snowflake 半结构化(如 JSON),因此如果需要表模式,则需要对其进行转换。在这个博客中优雅地解释了这一点。
关于监控的思考
Debezium 和 KafkaConnect 共同公开了一份详尽的指标列表,这些指标可以为数据管道提供出色的可见性。但在所有这些指标中,有一个指标很突出:kafka_consumergroup_lag。
我不能强调这个单一指标可以告诉我们端到端数据复制管道的健康状况。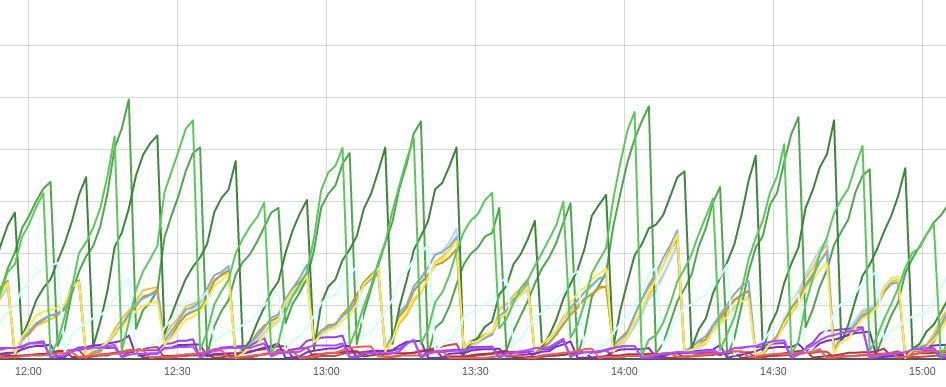
kafka_consumergroup_lag 的健康振荡趋势
Kafka Exporter指标反映了消费者未消费的 Kafka 主题分区中排队的消息数。理想情况下,它应该在零和给定阈值之间波动(基于您的数据管道 SLA)。
- 如果它停止上升: Debezium 已停止生成消息。
- 如果它停止下降:Snowflake已停止消费消息。
- 如果它太高:Snowflake消耗消息的速度太慢。缓冲区刷新配置应收紧。
- 如果它不够高: Snowflake 消耗消息的速度太快。通过增加缓冲区刷新限制可以节省 Snowpipe 成本。
- 如果不存在: Kafka 可能不稳定。