自从数据科学进入 IT 游戏并开始构建大量模型和项目以来,对工作编排的需求已经上升。由于 Jellysmack 的业务主要集中在帮助视频创作者在观众和质量方面增长,我们的许多团队都依赖从 YouTube(或其他社交平台,如 Facebook、Snapchat 等)提取的数据。这正是定义工作的方式,如 Jellysmack 中所见:需要数据作为输入并输出模型、关键指标或任何关于创作者频道和/或视频的分数的代码束,创建数据或运行预测。
一旦数据科学团队开发了这些工作,就必须对其进行编排。让我们想象一个非常简单的例子,其中一个工作在 YouTube 上收集数据,第二个工作处理这些数据以计算给定频道的新发布视频的分数。编排过程确定何时开始收集作业(定期计划、对特定事件的反应等)以及数据收集完成后如何触发数据处理作业。
现在,让我们想象一个巨大的工作图,所有这些都是相互关联的,这就是为什么工作编排是 Jellysmack 的首要需求。长期以来,许多工作的人工管理一直通过简单但有效的建议来解决,例如Cron(一个允许在 Unix 系统上在定义的时间运行脚本的实用程序)。虽然这样一个简单的逻辑对于独特和孤立的任务很有用,但相互依赖性迫使 Jellysmack 获得更好的作业调度策略,因为每天运行 100 多个作业来收集和处理来自社交媒体的数据。
Apache Airflow,管弦乐队指挥
Airflow是一个开源平台,由 Airbnb 从 2014 年到 2016 年开发,自 2019 年起成为Apache 软件基金会的一部分。Airflow 是用 Python 编写的,供 Python 开发人员使用,可以更轻松地使用代码编写完整的工作流程。用户只需指定将要执行的阶段(例如,存储数据、传输数据和处理数据)以及这些进程之间的关系(要处理数据,您需要先存储它,然后再传输它)。
在 Airflow 中,这样的工作流程称为有向无环图 (DAG)。顾名思义,定义的步骤可以是分支的、有条件的等,但一定不能创建循环依赖。它允许设计复杂的工作流程,高度并行处理成批数据。
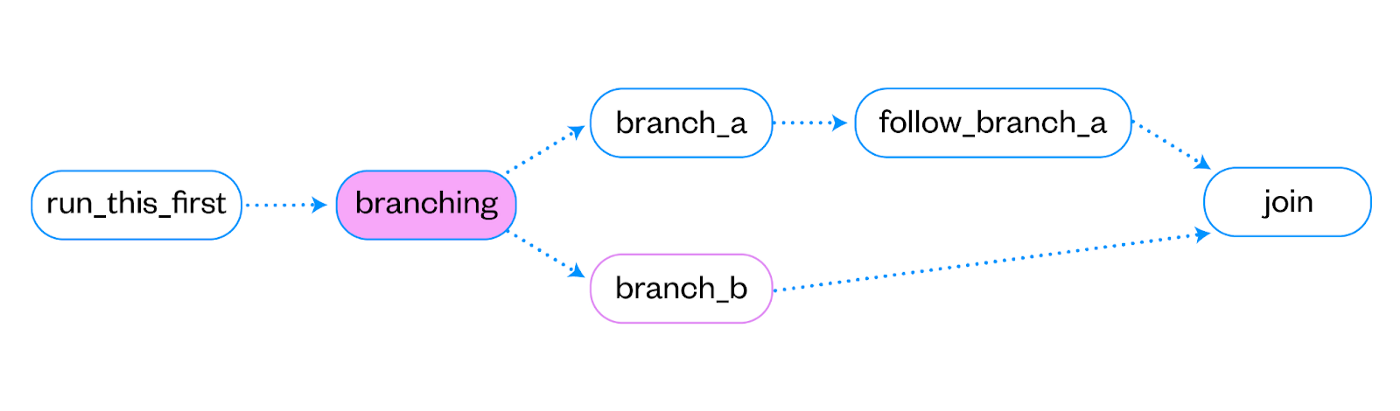
在这些 DAG 中,每个节点代表一个给定的任务,每个任务都使用 Airflow 所称的操作符。运算符是一个 Python 类,定义在Airflow Python 框架中,允许您调用不同类型的代码(PythonOperator 调用 Python 方法,BashOperator 调用 bash 脚本等)并对不同的源(S3Operator、MysqlOperator、 PostgresOperator 等)。
Jellysmack 的Airflow
最初,启动和运行 Airflow 的最简单、最快捷的方法是在 AWS 上启动一个EC2 实例(完全托管的机器),然后使用可用的Docker 映像启动 Airflow 。它运行了一段时间,Airflow软件很棒,但突然出现了一系列问题。
- 用户管理是完全手工制作的。Airflow 未链接到我们的 AWS Identity and Access Management (IAM)。因此,用户必须由数据工程师手动创建。
- DAG 部署是本地文件夹和 EC2 机器上的 SSH 目标文件夹之间的同步 (rsync)(一个不方便的过程)。
- 当匆忙修复某些东西时,可以通过 SSH 连接 EC2 并简单地在远程机器上使用像 Vim 这样的文本编辑器来应用修复。因此,没有执行修改的跟踪。
- 基础架构团队负责更新和保护该系统,这两项任务都很耗时。
扩大基础设施
在 Jellysmack,数据科学工作作为 Docker 镜像投入生产。典型的工作流程可能涉及从Postgres数据库 (PostgresOperator) 检索数据,对数据执行并行处理(KubernetesPodOperator 在Kubernetes集群上运行作业 Docker 映像),并将结果存储在服务数据库 (MysqlOperator) 中。对于复杂的场景,每个步骤都可以是一个完整的 DAG(预处理、作业和后处理 DAG),每一步都需要触发前一个。
虽然 Jellysmack 的工作数量每周都在增加,但我们运营的本地 Airflow 开始达到其极限:
- 托管 Airflow 流程的机器非常昂贵。由于此 EC2 实例在特定时间的高消耗,因此需要全时请求此 EC2 实例的硬件要求。因此,我们按未使用的 CPU 小时数付费。
- 由于机器缺少 RAM,某些作业因内存不足问题而无法启动。
- Jellysmack 数据和云工程师在这个工作站上花费了太多时间来执行维护和系统管理活动。
为了克服这些问题,对可扩展性的需求促使我们使用由 Amazon Web Services (AWS) 提出的完全托管版本的 Apache Airflow:MWAA。像每个完全托管的解决方案一样,它带来了优点和缺点。
- 作为专业人士,它为我们带来了一个完全可扩展的解决方案(托管 EC2 机器运行 Airflow 调度程序,其他机器为工作人员准备并按需配置等),非常容易与其他 AWS 组件一起操作(用于 Kubernetes pod 的 EKS 、Lambda 函数、SQS 队列等)。
- 但它也存在所有托管解决方案的缺点:它对运行这些 Airflow 组件的 EC2 机器隐藏了指标,并阻止访问 DAG 元数据数据库(Airflow 存储 DAG 状态、成功和失败以及其他元数据的数据库) .
桶中的 DAG
为了将 DAG 添加到托管 Airflow,必须将它们定义为 Python 脚本并存储在 S3 存储桶(允许您存储任何类型数据的 AWS 云存储)中。Airflow 进程每隔几秒扫描一次这个存储桶并导入这些 DAG,然后可以在 Web 界面上看到这些 DAG。因此,典型的数据工程工作流程是:
- 在本地修改 DAG(托管在 Gitlab 存储库上)。
- 通过 AWS 图形界面手动将其导入 S3 存储桶。
- 提交和合并必须在 Git 存储库上完成,该存储库仅用于存储 DAG 文件和审查合并请求。
虽然这个基本的工作流程对于一个小型数据工程团队来说已经足够了,但 Jellysmack 技术团队的成长带来了许多关于 DAG 的合作(数据工程师之间以及非 Airflow 专家,如数据科学家或后端工程师之间)。在这种情况下,每个人都可以简单地修改 S3 存储桶中的 DAG,而无需将修改发送到 Git 存储库(代码存储库和生产环境之间的非 ISO 情况)。它还缺乏一个质量保险系统,如果他们不遵守数据工程团队决定的标准,它将扫描所有修改并拒绝将 DAG 投入生产。
确保 DAG 质量
持续集成和持续交付 (CICD) 是软件工程中使用的一组实践,可缩小开发和运营之间的差距。它们可以被看作是在对代码进行修改并推送到 Git 存储库后启动的管道。这些管道负责构建、测试和部署新修改的代码。例如,让我们想象一个托管 Python 库的存储库。如果添加了新功能,CICD 将自动构建、测试和部署 Python 库的新版本,使开发人员可以专注于为该库带来价值和新功能,而不是花时间寻找重大更改或部署其工作。
为了将这些功能引入我们的 DAG 开发/部署工作流程,在 Jellysmack 设计的 CICD 中定义了四个不同的阶段来分析 Airflow DAG。
详细点击标题