系统设计对话可能非常具有挑战性。可能有很多模棱两可的地方、选项和想法——加上有限的时间和难以解决的问题。根据经验,我发现了一种通用方法,可以帮助使这些对话更有条理、更有趣、更有成效。
1. 要求和目标
系统设计讨论通常从要解决的开放式问题开始。
假设需求是:“让我们设计 Twitter”。
从一开始,每个人都需要保持在同一页面上。你可以通过澄清问题然后制定讨论议程来实现这一点。
该议程的第一步将讨论需求和目标,它们基本上可以分为两部分:功能性需求和非功能性需求。
功能需求:
功能需求是关于全局的,例如:
- 我们在建造什么?
- 主要用例是什么(发布推文、关注用户等)?
- 目标平台是什么(桌面、移动?)。
- 这方面的工程团队是什么样的?
非功能性需求是关于技术细节的:
- 我们应该如何考虑可用性、延迟和一致性示例:也许我们希望应用程序具有高可用性、低延迟、一致性可能会受到影响。在分布式系统中扩展时,CAP 定理(一致性、可用性、分区容限)成为一个问题。
- 我们希望尽最大努力在数据库中遵循 ACID 模型:原子性(在事务方面全有或全无)、一致性(仅将有效数据写入数据库)、隔离性(同时多个事务不会相互干扰)其他),耐久性(即使节点发生故障也不会丢失数据)。
- 存储和网络容量是多少?也许我们首先想考虑要关注的关键指标,可能是注册用户数以及每日或每月活跃用户数。从这些用户数中,我们可以假设用户总数中的一部分实际上是活跃在平台上的,并且会执行诸如发布推文之类的操作。此时,您可以使用单位 TB、GB、MB、KB 和 B 来估计数字,然后是相应的时间框架。例如,您可以说每日存储为“每天 1 GB”,大约为 10 亿字节。也许您希望这个数字是“每秒”而不是“每天”。为此,一天有 86400 秒,您可以将该天数除以 86400 以获得每秒存储量(10 亿字节除以 86400 秒大约是 10,每秒 000 字节,与 10 KB 相同)。在您继续讨论时,无论从中得出什么数字,都将作为有用的参考。
知道根据讨论的性质,有时在这一点上讨论非功能性需求并不是优先事项,这很有帮助。无论如何,讨论功能需求是必不可少的。
一旦您就需求和目标达成共识,现在是概述用户流程并深入研究系统 API 的好时机。
2. 用户流程和系统 API
这是您考虑用户使用产品的所有方式的部分,以及您希望用户最终采取的路径。
这是一个用户流程示例:用户登录、进入搜索、获取结果页面、可以联系业务、填写表单、发送消息、在消息框中查看消息……
通过这个用户流程大纲,您可以开始想象需要在幕后发生的不同请求。这直接导致概述 API 调用。
API 调用具有以下元素:
- 采取的行动(例如,编辑用户资料的 POST 请求,获取用户资料信息的 GET 请求)
- 请求所需的参数(例如,您需要提供用户 ID 来编辑用户的个人资料)
- 返回的结果(例如,用户配置文件的用户数据)
您可以开始编写 API 调用来涵盖流程中的每个步骤,这些调用如下所示:
- POST tweet (unique_key, tweet_data, location) => 返回新推文的 URL
- GET tweet (unique_key, tweet_id) => 以 JSON 格式返回关于 tweet 的信息
- …
我们有用户流程和系统 API 来帮助指导我们的系统设计。现在我们可以开始思考一个图表,了解一切在幕后是如何运作的。
3. 高级系统设计
以下是一些典型的设计注意事项:
- 客户端访问域,向 DNS 请求获取 IP 地址。
- 客户端请求转到 Web 服务器,但首先进行负载平衡。
- 负载均衡器可以通过服务器数量来修改来选择服务器,或者获取来自服务器的流量来确定选择哪一个(典型的方法包括轮询、按数量修改、轮询)。
- Web 服务器连接到数据库或文件存储,但缓存介于两者之间。
- Web 服务器还连接到微服务,如身份验证服务等。
- 缓存保存静态资源和 API 请求返回的数据,可以使用 write-through / write-back / 等以及最近最少使用或最不常用的驱逐策略。想想 Redis 和 Memcached。
- 数据库可以是 SQL(关系型,PostgreSQL)或 NoSQL(非关系型,Amazon DynamoDB)。SQL 数据库非常适合连接等数据库操作,但在跨多台机器拆分时不能很好地扩展。NoSQL 非常适合分布式系统,但不能执行连接等数据库操作——例如键值存储、宽列表存储、图形结构等几种类型。
- 文件存储就像 Amazon S3,非常适合照片、视频、资产。
- CDN 非常适合缓存静态资源,并且可以在地理上位于特定位置并保存在该位置特别重要的数据。
当拥有多个数据库时,有几种方法可以处理规模。以下是垂直缩放的方法:
- 给机器更多的功率、内存等。
- 在数据库中,可以使用索引,它基本上是将行分组在一起,这有助于搜索行。
并水平缩放:
- 可以使用姓氏、位置、哈希函数等对数据库进行分片。
- 使用多个分片主表,可以在主/从表关系中创建每个只读的复制(我没有编造这个术语)。写入到主表,读取到从表。处理哪些记录到哪个服务器也可以使用一致的散列来处理。一致的哈希有助于解决一个节点可能会变得超级不平衡的问题,但是当然,这会带来更多的复杂性。
- 使用负载平衡器或更改负载平衡策略(按数量、循环、最少连接)。
这是一个简单的图表示例:
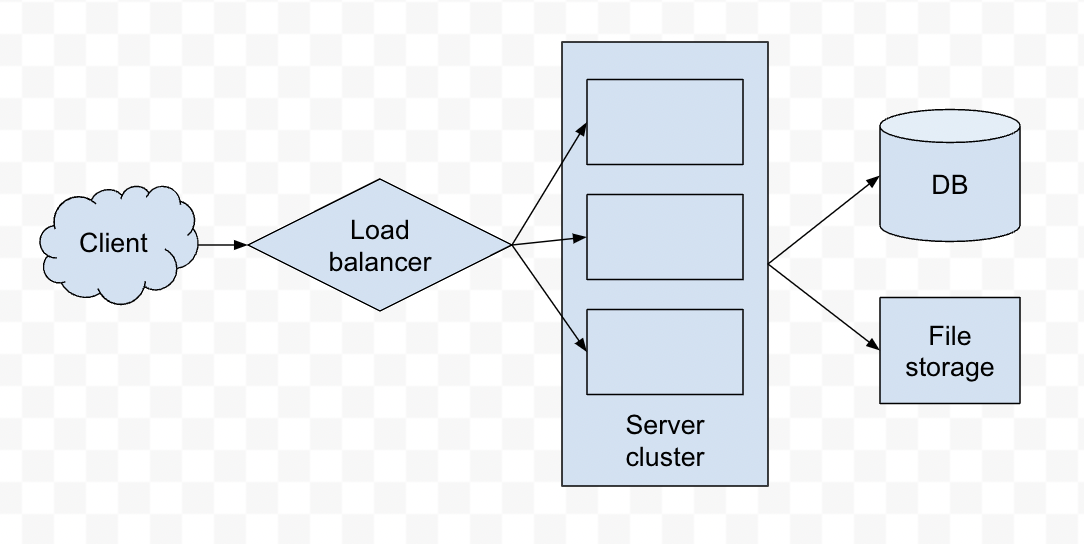
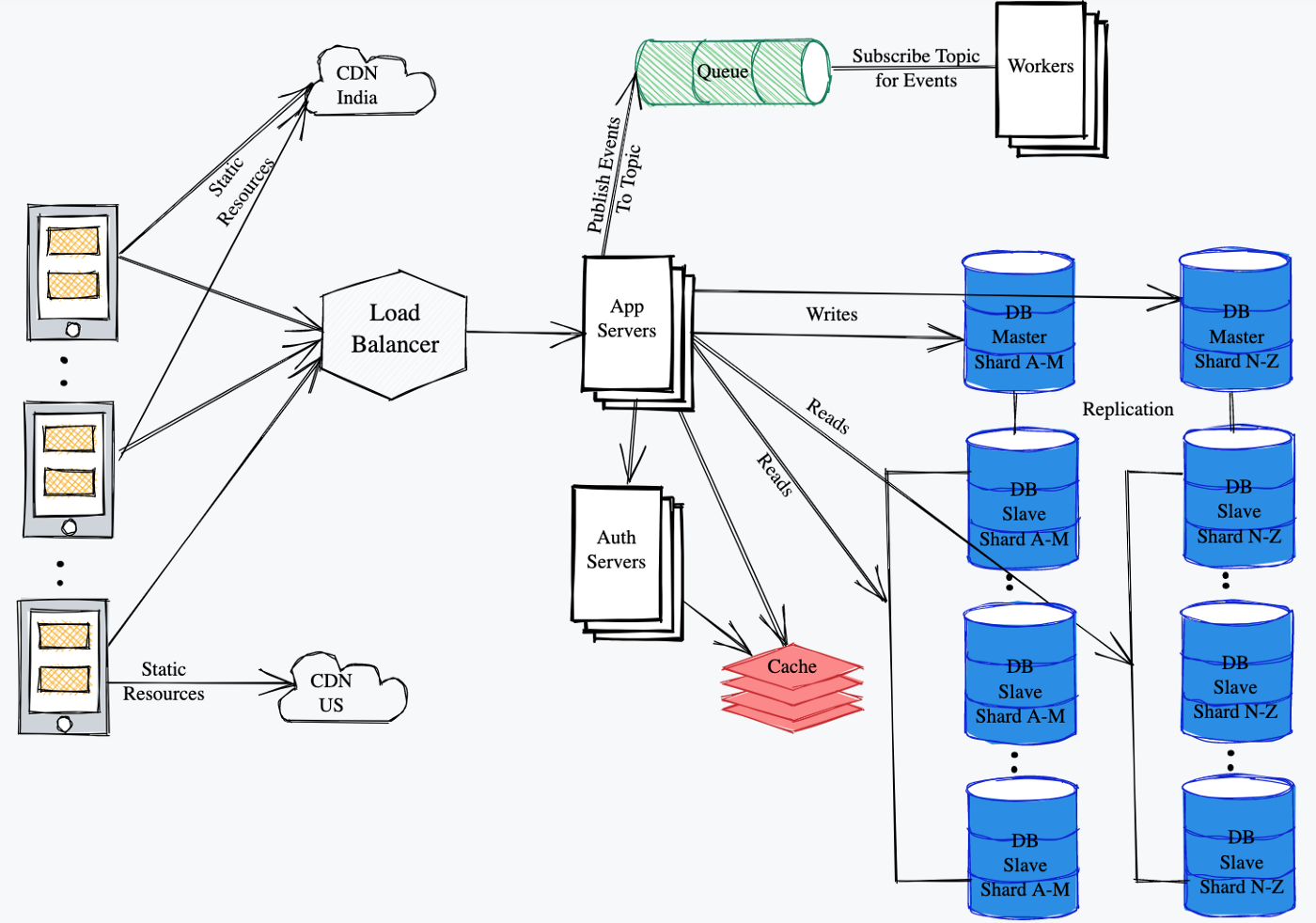
这是一个更复杂的图表示例,与上面的项目符号更加一致:
有了一个漂亮的图表,您现在可以更深入地了解数据库方面并写出数据库模式。
4. 数据库模式
要编写表结构模式,您应该考虑数据库表,然后考虑每个表中的内容。例如,对于 Twitter,我们可能需要 Tweet、User 等表,每个表都有自己的主键(粗体)和具有自己数据类型的列:
- 推文:tweetID:字符串,用户 ID:字符串,纬度:字符串,经度:字符串,createDateTime:字符串,numOfLikes:整数
- 用户:用户 ID:字符串,名称:字符串,电子邮件:字符串,dateOfBirth:字符串,lastLoginDateTime:字符串
- 用户关注:用户关注:用户ID,用户关注:用户ID
- 喜欢:tweetID:字符串,用户 ID:字符串
- …
系统设计对话可以以多种方式进行,不仅在最后,而且在整个过程中。这就是高级主题可以发挥作用的地方。
5.进阶话题
您最终可能会更深入地研究分片、缓存、队列、安全等。以下是一些可能进入讨论的示例:
- 安全性:我们如何为此添加安全性?我们可以加密、净化用户输入以防止 SQL 注入攻击,使用参数化查询,并使用最小权限原则。
- 队列:我们如何使用队列来帮助处理大量请求?Web 服务器将一些事件/消息添加到队列中,某些工作人员会监听队列中的事件(RabbitMQ 是一个流行的工具)。Web 服务器 => 交换 => 带有主题的队列 => 工作人员从队列中消费。您可以扩展队列数量和工作人员数量。
- …
总的来说,我希望这是一个对系统设计讨论有用的指南!这无论如何都不全面,因为系统设计可能会变得非常复杂和具体。相反,这涉及关键对话点和基本设计概念。