如果您在 Kubernetes 集群上部署 Airflow,并且正在寻找将 DBT 集成到 Airflow 中的方法,那么本文可能会给您一些启发。
需要对 Airflow、DBT(数据构建工具)和 Kubernetes 有一些基本的了解。
第 1 部分 — RPC 服务器设置
Astronomer 的人给了我们一些很好的想法,告诉我们如何建立 DBT 和 Airflow 之间的集成。我们最初的设计深受他们这篇文章的启发。
就像文章中推荐的一样,我们设置了一个 CI/CD 流程,该流程manifest.json会在主分支上的每次新提交时生成一个新文件。
然后,Airflow 实例随后读取该manifest.json文件,为每个模型创建一个 DAG,该 DAG 还负责运行上游模型。
但是,我们认为有几点可以改进:
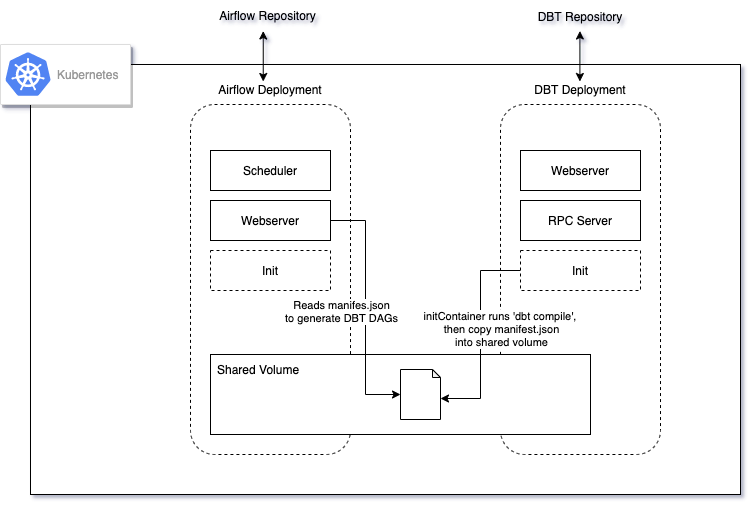
- DBT 模型可能必须与 Airflow 实例放在一起,以便 Airflow 访问它们并dbt run在它们上执行。假设 Airflow 存储库已经存在,DBT 相关文件可能必须位于同一个存储库中。这可能会使存储库变得臃肿,分析工程师可能会发现很难维护 DBT 相关组件。
- 从技术上讲,可以创建一个不同的存储库来存储 DBT 模型,并让 Airflow 实例简单地从存储 DBT 模型的目录中读取。在 Kubernetes 设置中,这可能意味着设置共享卷形式的额外复杂性,并为每次新更新复制所有 DBT 模型。
- 此外,随着我们在 Airflow 上部署的各种工作负载,在同一个 Airflow 实例中安装了越来越多的库。我们希望保持库的精简以避免冲突和混乱的依赖问题。
根据 DBT,“该服务器在 dbt 项目的上下文中编译和运行查询。此外,RPC 服务器提供的方法使您能够列出和终止正在运行的进程。”。
本质上,这意味着一旦我们设置了服务器,而不是将 DBT 模型放在 Airflow 存储库中,我们可以:
- 向 RPC 服务器(已经拥有项目的上下文)提交请求以运行 DBT 命令
- 轮询提交作业的状态
- 工作完成后,解析响应并根据最终状态决定做什么
随着 DBT 存储库与 Airflow 存储库的分离,现在整体部署如下所示:
对于每个 DBT 任务,PythonOperator 运行以下函数:
使用 PythonOperator 创建 DBT 任务
下图进一步细分了 Airflow 为特定模型运行 DBT 任务时发生的情况: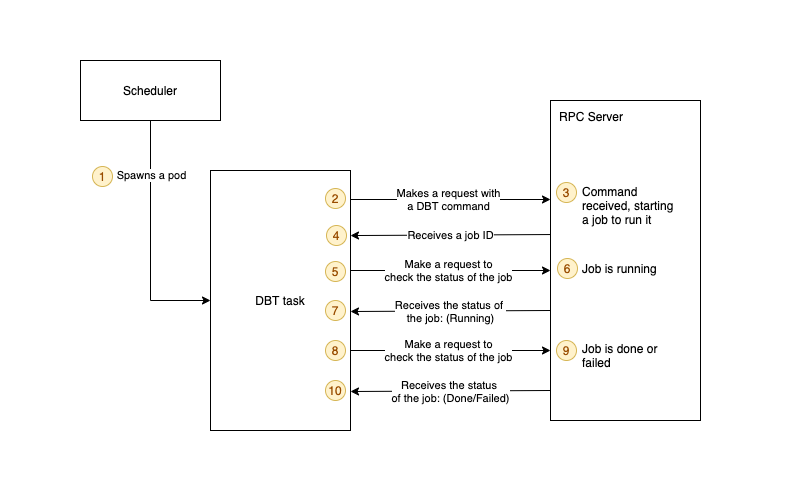
- 气流调度器生成一个 pod 来运行 DBT 任务
- pod 向 RPC 服务器发出请求,指定它要运行的命令
- RPC 服务器接收到请求,然后启动一个作业来运行命令
- pod 收到带有作业 ID 的响应
- Pod 使用作业 ID 不断向 RPC Server 发出请求以检查作业的状态
- 作业仍在运行
- RPC 服务器响应作业仍在运行
- pod 发出另一个请求以检查作业的状态
- 最终,工作完成或失败
- pod 将收到一个响应,说明工作已完成或失败。Airflow 任务将被标记为成功或失败。
第 2 部分 — KubernetesPodOperator 设置
RPC 服务器能够在一段时间内发挥其作用。但是,当我们添加更多模型并更频繁地运行它们时,这种设置的弱点开始显现。由于 RPC 服务器是使用固定资源部署的,当有更多请求进入时,它无法自行扩展。
更糟糕的是,RPC 服务器没有内置队列系统来处理传入的请求负载。任务需要更长的时间才能完成。响应时间过长的任务被标记为“失败”,并且 Airflow 触发了重试,这会堆积到现有的作业上。该转换系统的整体性能显着下降。
正如我们所见,RPC 服务器设置实际上是Kubernetes 集群中构建的系统其余部分的反模式。
当 Airflow 运行越来越多的任务时,会产生更多的 pod,并且集群能够扩展资源以满足这些 pod 的需求。相反,RPC 服务器必须使用其固定资源并尝试运行所有被请求的模型。
我们试图通过为 RPC 服务器提供更多资源来解决此问题,但它不可扩展。增加的资源往往跟不上加班增加的 DBT 模型数量的增加。在停机期间,RPC 服务器只是囤积资源而不运行任何作业,这会转化为更高的服务器成本。
在高需求期间尝试扩大 RPC 服务器的实例数量在技术上是可行的。但是,由于触发 RPC 服务器中的作业的 pod 必须从具有给定 'request_token' 的同一 RPC 服务器实例轮询,因此必须实现将请求路由回同一 RPC 服务器的机制。
由于这种增加的复杂性,我们的团队认为不值得进一步追求这种设计。
此时,该团队一直在尝试使用 KubernetesPodOperator 来处理无法使用默认操作符轻松构建的管道。我们发现使用 KubernetesPodOperator 的一个优势是特定于工作负载的库仅包含在映像中,而 Airflow 只是触发作业的编排器,进而生成 Pod 以在集群上运行工作负载。
我们可以为该 Pod 指定我们想要的资源,以及任何变量和配置。这是一个优雅的抽象,允许我们运行我们想要的任何工作。
因此,我们认为我们可以使用 KubernetesPodOperator 来运行 DBT 任务。对于解析manifest.json文件的每个模型节点,而不是向 RPC 服务器发出请求并等待响应的 PythonOperator,它可能是拉取 DBT 存储库映像的 KubernetesPodOperator,并指定自定义命令来运行该特定模型。
下面的代码片段说明了通过解析manifest.json文件在每个节点上创建的任务:
使用 KuberenetesPodOperator 创建 DBT 任务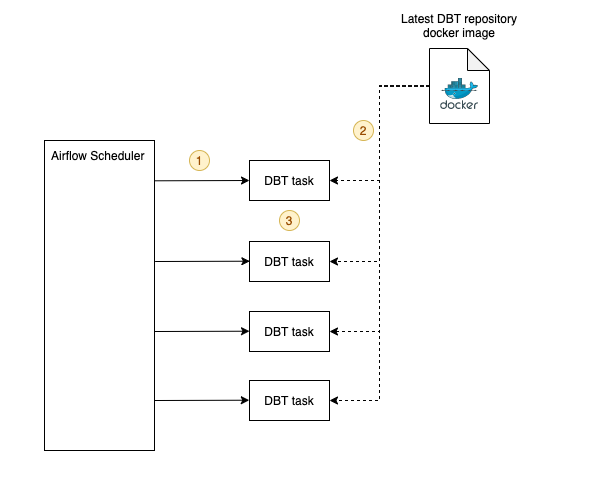
使用 KubernetesPodOperator 运行 DBT 任务
- 调度程序生成一个 pod 来运行 DBT 任务(简化)
- 任务拉取最新的 DBT 仓库镜像
- 然后该任务运行特定于模型的自定义命令
结论
当前的设置满足了我们为转换层设计的所有要求。它具有高度可扩展性和稳定性。团队可以在较小的代码库上工作,并且更容易维护。从那以后,我们的工作量增加了几倍,系统可以毫不费力地处理它们。