微服务架构促进了去中心化的数据管理实践,其中每个服务都将其数据保密并仅通过定义良好的 API 接口将其公开。尽管这是为了更大的利益,但开发人员发现实现跨越多个服务边界的查询具有挑战性。 一个微服务经常联系几个依赖服务来完成一个读取请求。例如, ShippingService 查询 CustomerService 以检索客户的地址。这些同步调用增加了整个架构的延迟和脆弱性。 或者,微服务可以在自身内部维护经常需要回答查询的依赖数据。物化视图是实现这一目标的一种方法,我们可以随着依赖服务中的数据变化而使它们保持增量更新。 增量更新的物化视图对于微服务来说似乎是有利可图的,因为:
- 它们可以在满足读取请求(查询)的同时消除服务间通信。
- 当与正确的流处理器技术配合使用时,它们可以使物化视图保持同步。
这个由两部分组成的文章系列将引导您构建流式 ETL 管道以维护读取优化的 CQRS 视图,从而更快地回答查询。我们将使用Debezium将相关数据摄取到Kafka中,使用Materialize来构建和维护物化视图,并使用Apache Pinot来大规模提供丰富的数据。 这篇文章 探讨了问题空间,设计了一个实用的解决方案来解决这个问题,并向您介绍我们在第 2 部分中用于构建解决方案的工具堆栈。
用例:构建在线披萨订单跟踪器
在从当地的比萨店订购比萨饼并焦急地等待订单到达后,我受到启发写这篇文章,因为我饿了:) 我当地的披萨店有一个类似于以下的 Web 界面,可以实时跟踪披萨订单的状态。
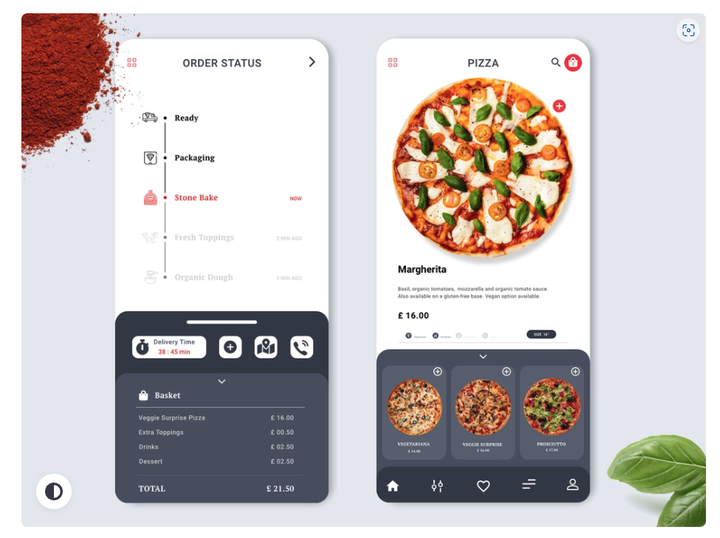
在等待我的披萨时,我拿了一张纸开始画我如何设计和构建这样一个订单跟踪系统来服务成千上万像我一样饥饿的顾客。 UI 应显示以下信息。
- 订单详情,包括订单号、时间戳和总金额。
- 订购的物品及其数量。
- 订单的当前状态,以及订单状态更改的历史记录。
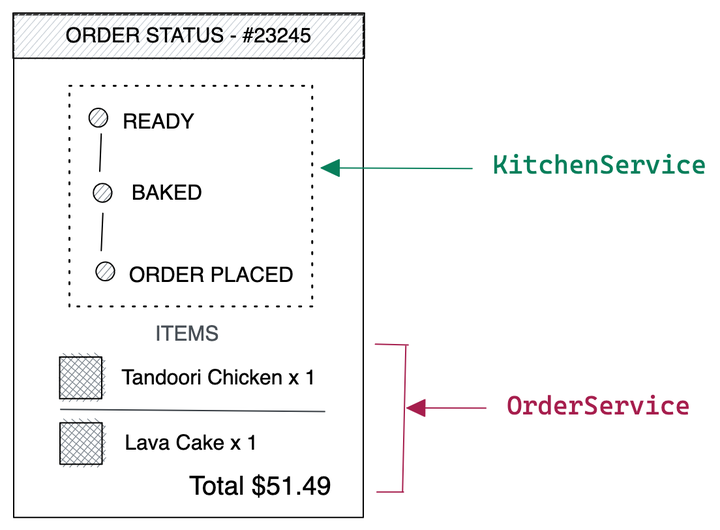
假设我们使用基于微服务的架构来实现(呵呵!),我们至少需要三个微服务来填充 UI。
- OrderService — 提供与订单及其商品相关的信息。
- KitchenService — 提供订单状态更改。
- Delivery Service — 提供订单交付更新。
考虑到这一点,让我们考虑不同的架构风格来构建状态跟踪 UI。
选项 1 — 使用服务编排
最简单的解决方案是让服务一起通信以制定订单状态信息。当 UI 联系 OrderService 时,它将调用 KitchenService 和 DeliveryService 以提取必要的信息。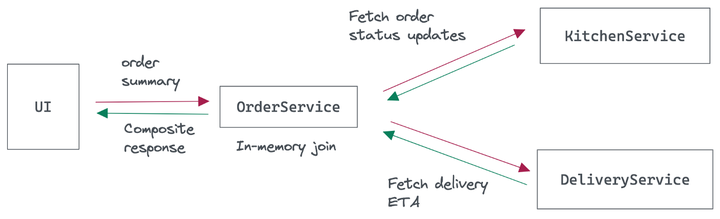
这种服务编排通常会导致 OrderService 等待、解组和加入来自依赖服务的响应,这会增加架构的延迟和脆弱性。解决方案的可扩展性和可靠性以性能最低的相关服务为上限。
该解决方案将面向 Internet,并且随着流量的增长需要更高的可扩展性和性能。因此,我们将消除此选项。
选项 2 — 使用批处理数据管道
如果我们预先计算 UI 的结果,而不是动态提取信息,该怎么办?
好吧,这也可能是一种选择。我们可以编写一个批处理 ETL 作业来从所有服务中提取信息并将它们连接起来以形成一个非规范化的表,以订单 ID 为键。这使 OrderService 能够通过一次调用快速查找订单摘要,仅使用订单 ID。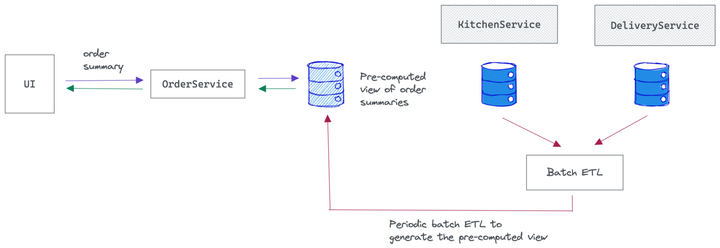
缺乏数据新鲜度是这里的主要问题。增加批处理作业的频率将在 UI 上产生更新的结果。但这又会产生额外的计算成本。
选项 3 - 使用增量更新的物化视图。
尽管延迟是一个问题,但选项 2提出了一个不错的想法,即为每个订单预先计算订单状态 UI。
如果 OrderService 维护属于其下游服务 KitchenService 和 DeliveryService 的数据怎么办?这允许 OrderService 仅通过查找本地数据来更快地为查询提供服务。此外,它可以通过订阅下游服务的状态变化并相应地更新数据来保持数据的一致性。
这就是我们在选项 3中要做的事情。我们将在 OrderService 中创建一个读取优化的物化视图,为每个订单预先计算 UI。该视图包括来自所有相关服务的属性,并以订单 ID 为键,从而能够通过基于主键的快速查找来服务 UI 查询。
我们如何使物化视图保持最新?我们将让 OrderService 监听下游服务的状态变化并相应地更新物化视图。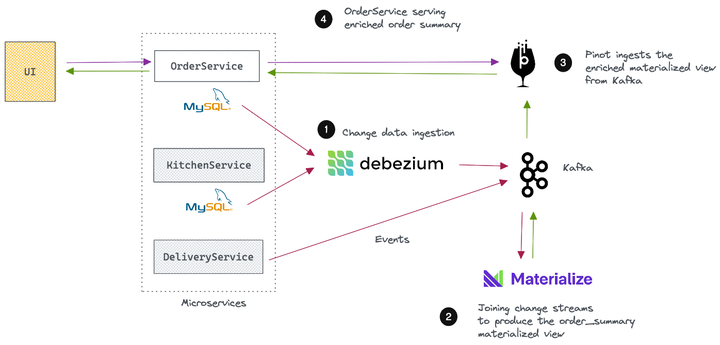
我们将使用Debezium和 Kafka 将来自所有微服务的状态更改作为事件流捕获,并使用Materialize通过将这些流连接在一起来构建物化视图。随着新事件的到来,Materialize 将使视图保持最新。我们会将视图中的更改流式传输回 Kafka,并让 Apache Pinot 摄取它们以服务于 UI 查询。
教程——构建一个增量更新的物化视图
现在让我们看看如何实现选项 3中讨论的读取优化视图。好消息是您已经可以找到完整的解决方案。您需要做的就是克隆解决方案、运行它并应用必要的配置以使其正常工作。
您可以从位于cqrs-views目录内的以下 Git 存储库中找到完整的解决方案。
https://github.com/dunithd/edu-samples
该解决方案作为Docker Compose项目提供。因此,请确保您已安装Docker Desktop并分配至少 8GB 的 RAM 和 6 个 CPU 内核,以便 Docker 守护程序正常工作。
如下克隆 Git 存储库或下载存档。
[email]git@github.com[/email] :dunithd/edu-samples.git
在终端中键入以下内容以创建并启动所有应用程序容器。
cd edu-samples/cqrs-views docker compose up -d
上面的命令将调出以下容器。
- mysql — 包含订单和订单项
- zookeeper — Kafka 和 Pinot 需要
- kafka - 阿帕奇卡夫卡
- schema-registry — Debezium 和 Materialize 的 Confluent Schema Registry
- debezium — 预先安装了 Debezium MySQL 连接器的 Kafka Connect 映像
- 物化——物化
- pinot-* — Pinot 控制器、代理和服务器
之后,通过键入以下内容来验证 Docker 堆栈的整体运行状况:
docker compose ps
使用此解决方案,我们需要完成三个基本步骤。
- 支持事件的微服务数据:让微服务使用 Debezium 将其数据流式传输到 Kafka。
- 构建和维护物化视图:将数据流与 Materialize 结合起来,构建一个增量更新的物化视图。
- 服务物化视图:将视图中的更改捕获到 Apache Pinot 表中,并使用它来服务 UI 查询。
下面本博客的第 2 部分详细解释了这些步骤,同时引导您完成获得预期结果所需的必要配置。
第 1 步:支持事件的微服务数据
我们的第一步是在生成上述微服务时捕获数据,并将它们移动到我们可以构建物化视图的地方。我在项目中省略了 DeliveryService 以减少移动部件并使其易于理解。
我们在 OrderService 中有订单和订单商品,在 KitchenService 中有订单状态更新。让我们先将这些数据移出。
使用 Debezium 从 OrderService 流式传输订单
假设 OrderService 有一个名为Pizzashop的 MySQL 数据库,其中包含两个表;订单和order_items 。它们 代表披萨订单与其订单商品之间的一对多关系。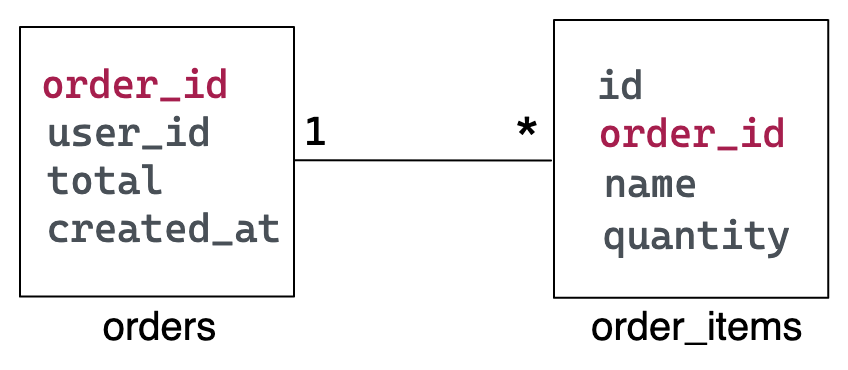
当您启动 Docker 堆栈时,MySQL 容器会自动创建上述数据库,其中包含一些模拟订单记录。<project_root>/mysql您可以在文件夹中找到种子脚本。
当 OrderService 在这些表中创建或更新订单时,我们可以使用 Debezium 将它们作为更改事件流式传输到 Kafka。所以,让我们注册一个 Debezium MySQL 连接器来启用它。
在终端中键入以下内容。
curl -H 'Content-Type: application/json' localhost:8083/connectors --data ' |
命令返回后,您应该会看到创建的两个 Kafka 主题mysql.pizzashop.orders和mysql.pizzashop.order_itemsorders ,分别包含来自和order_items表的更改事件流。最初,Debezium 将从两个表中获取快照并将它们流式传输到这些主题。
从 KitchenService 捕获订单状态更改
假设当订单状态跨不同状态转换时,KitchenService 直接将类似于此的事件生成到 Kafka 主题中。
{ "id":"1", "order_id":1, "status":"CREATED", "updated_at":1453535342 } |
通过运行将一些示例事件发布到order_updatesKafka 主题:
kcat -b localhost:29092 -t order_updates -T -P -l data/updates.txt |
我在kcat这里用过这个工具。但请随意使用任何其他工具。这些order_id事件与来自 MySQL 的订单相匹配,允许我们稍后加入它们。
第 2 步:构建 order_summary 物化视图。
完成第 1 步后,您应该会看到在 Kafka 中创建的三个主题。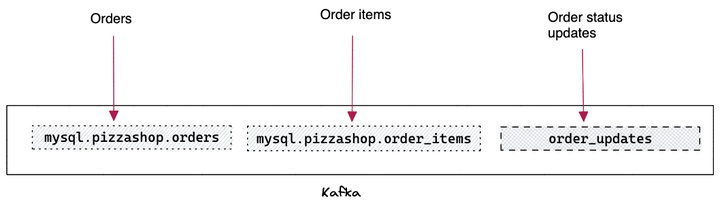
此步骤旨在通过将来自这些主题的事件流连接在一起并在新事件到达时保持增量更新来构建物化视图。我们将为此使用Materialise。
Materialize 是一个流式数据库,旨在用 SQL 构建数据密集型应用程序和服务——无需管道或缓存。Materialise 的工作基于Timely Dataflow 论文,该论文有助于维护增量更新的物化视图。
定义源和视图
我们将创建三个源来表示 Materialize 中的上述事件流。
我们的 Docker 堆栈已经包含一个正在运行的 Materialize 容器。您可以使用 Materialize CLI 或psql连接到它(是的,Materialize 与 Postgres 兼容)
psql -U materialize -h localhost -p 6875 materialize |
现在您在 Materialize CLI 中,将Pizzashop数据库中的所有表定义为 Kafka 源:
CREATE SOURCE orders |
Debezium 编写的 CDC 流默认为 Avro 格式,它使用Docker 堆栈中包含的Confluent Schema Registry容器。上述来源从注册表中提取消息模式数据并具体化每个属性的列类型。
我们还想创建一个 JSON 格式的源来表示 order_updates 主题。
对于 JSON 格式的消息,我们不知道架构,因此JSON 被作为原始字节拉入,我们仍然需要将数据 CAST 到正确的列和类型中。为此,我们将创建以下视图。
CREATE MATERIALIZED VIEW updates AS |
这个视图没有具体化并且不存储查询结果,但是为嵌入的 SELECT 语句提供了一个别名,并允许我们将状态更新数据塑造成我们需要的格式。
键入show sources和show views以验证到目前为止创建的源和视图。
materialize=> show sources; |
定义 order_summary 物化视图
接下来,我们将根据order_id加入上述流以创建order_summary物化视图。此视图包含填充 UI 所需的所有信息。
CREATE MATERIALIZED VIEW order_summary AS |
订单、订单项目和状态更新具有不同的基数。例如,一个事件可以有许多订单项目和状态更新。因此,我们可以使用array_agg() Postgres 函数将项目和更新建模为数组。这样,我们可以将订单的所有相关信息放入视图中的一行。
运行以下查询将显示视图的内容。它已经填充了现有数据。
materialize=> select * from order_summary; |
结果是:

上图order_summary 物化视图填充了现有数据
定义 Kafka 接收器
随着新事件的到来,order_summary物化视图会不断更新。应用于视图中每一行的更改将发出一个包含该行最新版本的更改日志事件。我们可以将这些事件捕获为 CDC 流,并使用sink将它们移动到 Kafka 。
CREATE SINK results |
当您创建 Sink 时,Materialize 会从创建 Sink 开始将所有更改流式传输到视图。
请记住,物化视图保存在内存中。如果您重新启动 Materialise 并使用基本接收器,您将在 Materialise 重新摄取上游数据并重新计算视图时流式传输重复的更改事件。为了确保用户不会在不知不觉中推送重复的事件,Materialize 在每次重启后为接收器创建新的、不同的主题。
我们可以使用reuse_topic选项避免这些潜在问题。
要启用现有主题的重用,您必须使用reuse_topic选项。此外,您可以指定一致性主题的名称来存储 Materialise 将用来识别最后完成的写入的信息。一致性主题的名称由CONSISTENCY TOPIC参数提供。
由于这是 JSON 格式的接收器,因此您必须指定一致性主题格式为 AVRO。这是通过CONSISTENCY FORMAT参数和指向模式注册表 URL 的指针来完成的。
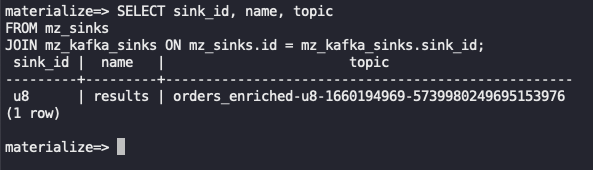
运行以下查询以查看接收器创建的 Kafka 主题。记下它的名称,因为我们将在下一步中需要它。
SELECT sink_id, name, topic |
第 3 步:提供丰富的物化视图
我们的工作还没有完成。但我们刚刚完成了棘手的部分。剩下的是将物化视图的 CDC 流摄取到 Apache Pinot 中,允许 UI 以更高的吞吐量快速查询它。
为什么选择Apache Pinot?
我们可以直接将丰富的物化视图提供给 UI。但是这个用例是不同的。披萨订单跟踪器是面向 Internet 的,允许数百万并发用户访问它,结果必须在几毫秒内显示在 UI 中。
为了满足这一需求,我们将使用Apache Pinot,这是一个实时 OLAP 数据库,能够摄取流数据并使它们可用于快速和可扩展的查询。
摄取嵌套的 JSON 对象和多值字段
从 Materialized 进入 Kafka 的 CDC 流由 JSON 格式的事件组成。以下表示单个事件,其中包括深度嵌套的结构和 JSON 数组。
{ |
我们可以将 Pinot 配置为在摄取期间取消嵌套 JSON 结构。此外,我们可以使用多值列来存储单个订单的订单项目和状态更新。
在 order_id 上启用 upserts
CDC 流可以有多个具有相同order_id的事件。例如,如果订单状态从 PREPARING 变为 READY,它将发出两个具有相同order_id的事件。
在 Pinot 中,我们可以通过在order_id上启用 upsert 来捕获所有更改事件并将它们合并到一行中。插入的行始终具有最新状态并启用基于主键的快速查找。
定义订单模式和表
最后,键入以下命令为订单Pinot 表定义模式和表。您可以在<project_folder>/config文件夹中找到相关文件。
docker exec -it pinot-controller /opt/pinot/bin/pinot-admin.sh AddTable \ -tableConfigFile /config/orders_table.json \ -schemaFile /config/orders_schema.json -exec |
请注意,在orders_table.json中,您必须更改stream.kafka.topic.name以匹配之前由 Materialize sink 创建的主题。
测试端到端解决方案
如果您在此之前遵循了所有内容,您应该会在订单 Pinot 表中看到两个订单。
访问Pinot 查询控制台并执行以下查询以将系统中的所有订单及其项目和状态历史记录为多值字段。
SELECT |
结果是:

items 和 status 是多值列,将值存储为字符串数组
向 Kafka 生成以下事件以模拟order_id=1.让我们准备好发货吧!!!
{"id":"5","order_id":1,"status":"READY","updated_at":1453535345} |
接下来,在 Pinot 中运行这个查询,看看它的状态变化有多快。
SELECT order_id, total, items, status FROM orders WHERE order_id=1 |
结果是:

外卖——我们还能做些什么?
现在我们已经在 Pinot 中存储和维护了读取优化的视图。OrderService 可以通过对 Pinot 表进行基于主键的查找来完成来自 UI 的订单汇总查询。
由于该表具有填充 UI 所需的所有信息,因此它是读取优化的,并且避免了额外的按需连接和过滤。这可以更快地呈现订单摘要 UI,从而增强整体用户体验。
Materialize 确保order_summary视图随着新订单的进入及其状态的变化而增量更新。
如何扩展解决方案?
如果以后想在 UI 上显示更多信息怎么办?例如,我们可能还需要显示交货 ETA 和地址。您可以通过向解决方案添加更多数据源(DeliveryService 和 CustomerService)、配置 Materialize 以加入它们以及更新 Pinot 的服务表以包含其他列来促进这一点。