PayPal 撰写了关于采用数据网格原则的策略。该博客承认尚无标准实施,但建立了一个商业案例,说明 PayPal 在其数据策略中需要 DataMesh 原则。这是一个令人兴奋的从 PayPal 观察的空间。
随着企业变得更加敏捷,集中化越来越成为过去的世界,数据平台似乎也是如此。因此,我们正在构建一个数据网格,这是 PayPal Credit 的下一代数据平台。这篇文章详细介绍了数据平台的演变,突出了它们的问题,以及我们决定构建数据网格的原因。我将详细介绍 Data Mesh 的四个原则、如何开始、查看架构并描述一些挑战。
数据平台的演进
在深入了解 Data Mesh 的细节之前,让我们回顾一下信息行业是如何走到这种境地的。
六千五百万年前,恐龙……不,我不会及时走那么远。1971 年,Edgar Codd 发明了第三范式,即关系数据库的关键。此后不久,企业开始看到聚合数据的好处,这为创建数据仓库开辟了道路。
数据仓库带来了对数据管理更严格的需求:您正在为数据创建一个仓库,因此就像在物流仓库中一样,通道、货架和空间必须明确标识。您必须设计数据仓库以容纳传入的数据并构建 ETL(提取、转换和加载)流程来填充仓库。企业现在能够执行新维度的分析。不幸的是,仓库不是很灵活,而且随着数据源数量的增加,入职数据变得复杂。
让我们想象一家零售公司 Great Parts,从事 B2C 和 B2B 活动。他们在北美有几千家商店,有一个忠诚度计划,他们接受退货。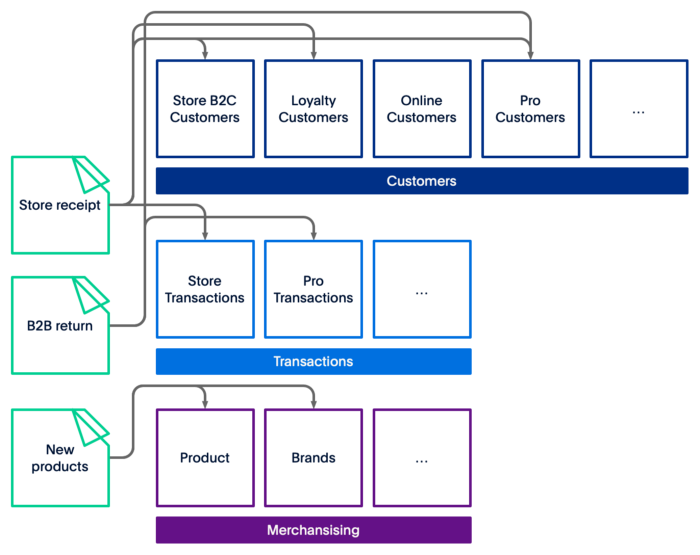
图 1 — 新收据、退货和新产品的数据流。
现在想象一下 Great Parts 决定将他们的忠诚度计划扩展到 B2B;您将不得不在 B2B 退货和您的客户空间之间建立一个 ETL 流程。如果您计划从您的移动应用程序、Web 应用程序和 B2B 站点添加新的数据源,例如点击流。它将变得越来越复杂,您将不得不管理 ETL 意大利面条。
在我们的行业中,Great Parts 决定完全从数据仓库转移到数据湖。钟摆剧烈地移动了。在数据湖中,您收集所需的所有数据并将其存储。无论在哪里。你可以看到这是怎么回事。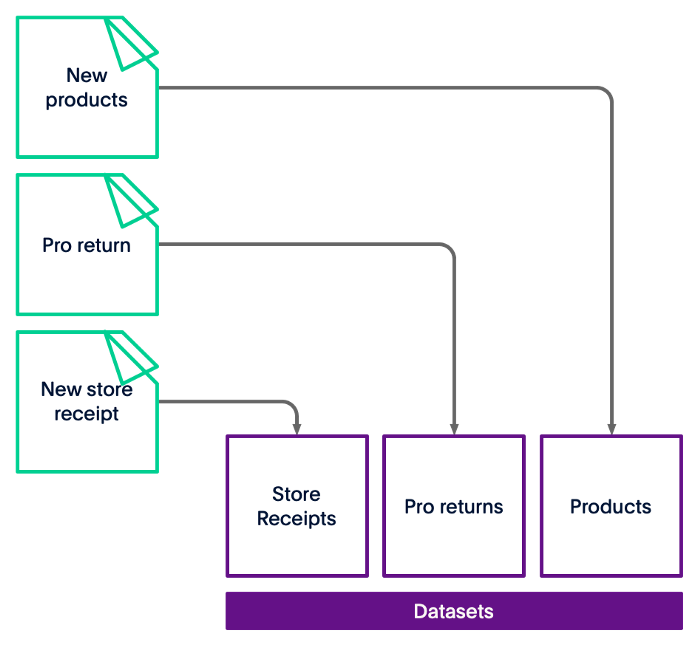
图 2 — 在数据湖中摄取数据比使用数据仓库要容易得多。
现在,当您再次尝试使用您的数据时,它变得有点棘手。储存容易,阅读却很复杂。
您可以通过为分析负载创建小型数据仓库(数据库或数据集市)来访问数据,但您又回到了 ETL 意大利面。
在通过微服务进行操作处理时,也是同样的困境。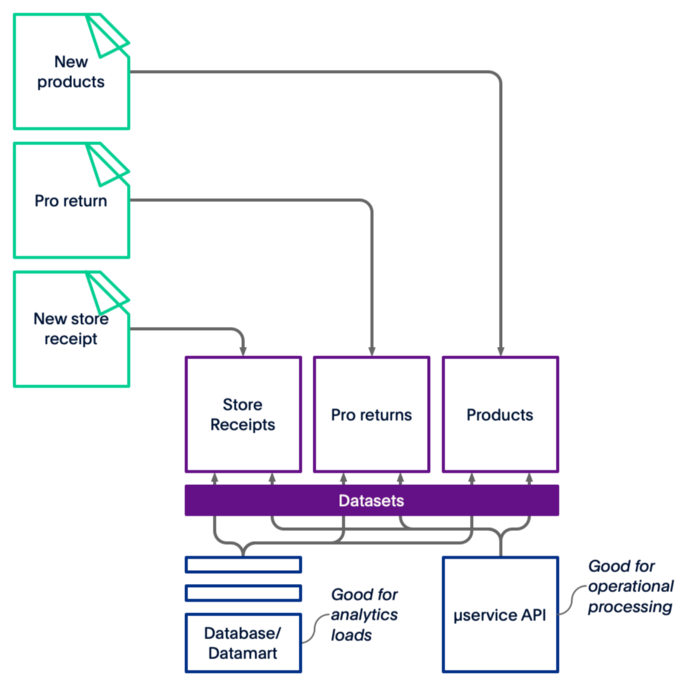
图 3 — 从数据湖中获取价值可能有点棘手。
最近的架构,如数据湖库,正试图结合最好的湖和仓库,但它们仍然缺乏数据质量、治理和自助服务功能,以确保符合企业和监管标准。
机会
不幸的是,对于一些技术人员来说,项目并不是为了技术而发生的。他们受到机遇和挑战的驱动。贝宝也不例外。让我们来看看 PayPal 的领导层被认为是一个新的数据平台所带来的机会。
PayPal 在自助分析领域处于领先地位,与许多公司相比,它为业务分析师和数据科学家提供了对我们数据仓库的访问权限。这一举措的成功,加上 PayPal 愿意迁移到云,推动了对不同类型数据平台的需求。
除了自助服务之外,数据科学家的需求也随着更多数据发现能力而发展。与许多公司一样,数据源有所增加,无论是在内部、通过收购,甚至来自数据提供商等外部来源。
随着业务变得越来越复杂,主要驱动力是合规性和可审计性的提高,挑战变成了将大数据、自助服务发现、实验、合规性和治理结合起来,同时提供从数据实验到生产的清晰路径.
我们在 PayPal、GCSC IA(全球信用风险、卖方风险和收款、智能自动化)的团队选择了数据网格范式,因为它最适合我们的客户需求。
数据网格的四个原则
2019 年 5 月,杰出的工程师 Zhamak Dehghani 发表了一篇强调数据网格基础的论文。在她的论文中,Dehghani 为四项原则奠定了基础,在过去几年中,这些原则被提炼为数据网格的四项核心原则。我喜欢将这些原则与敏捷宣言如何破坏软件工程中基于瀑布的生命周期进行比较。数据网格将您可能熟悉的敏捷软件工程的许多概念引入数据工程。
让我们一起发现这四个原则。
一、领域所有权原则
在过去的几十年中,“领域”一词被过度使用,其含义几乎是胡言乱语。尽管如此,让我们尝试在这种情况下驯服域和所有权。
域是您关注的特定业务领域。如果您从事医疗保健行业,则可以是医院或放射科等特定部门。识别领域设置边界并帮助您陷入范围蔓延的情况(例如,让我们在项目中也包括医院自助餐厅)。
如果你熟悉领域驱动开发,这个原则对你来说自然而然。
这是常识:不要试图煮沸海洋。
找到最了解某个领域的人,并将他们与数据架构师联系起来。去中心化团队拥有宝贵的领域专业知识:他们比从一个领域切换到另一个领域的中心化团队更了解数据源、数据生产者、规则、历史和系统的演变。在组合中添加数据架构师将带来安全性、规则和全球治理,以保持与企业策略的合规性。
二. 数据即产品原则
在软件工程中,敏捷用产品代替了项目。数据成为一体只是时间问题。让我们看看数据产品能带来什么。
专注于数据产品将使您能够从项目规划的角度转变为以客户为中心的方法。令人生畏?不,只是 DAUNTIVS,数据产品必须是:
- 可发现,
- 可寻址,
- 可以理解,
- 原生可访问,
- 诚实守信,
- 可互操作和可组合,
- 本身就有价值,并且
- 安全的。
在软件架构中,最小的可部署元素称为量子。当应用于数据架构时,数据量是最小的可部署元素带来的价值。数据量子与量子计算无关。
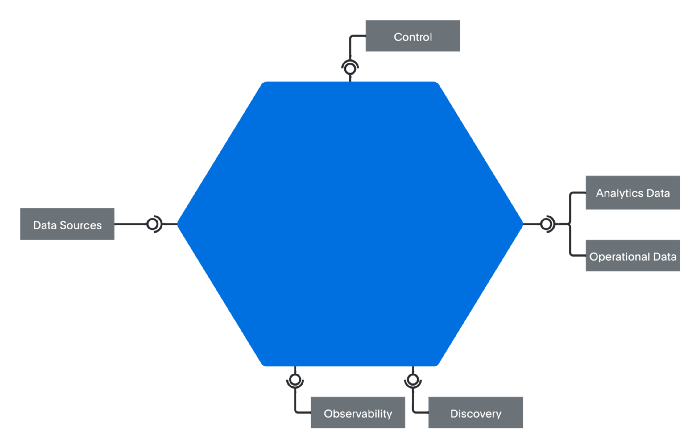
图 5 — 数据量呈六边形,突出显示其多个端点,允许访问数据、元数据、可观察性和控制。
您可能想知道,“嘿,这与我使用几个数据治理工具的数据湖有何不同?” 答案是规模很重要:您专注于单个域,而不是整个企业级湖。它绝对是更多的“字节大小”和可咀嚼的。
由于其规模和范围更小,实施速度更快,数据价值在公司中重新注入的速度也更快。
三、自助数据平台原理
当我还是个孩子的时候,在法国,我喜欢和父母一起去当地的超市,因为那里有一个自助餐厅,我可以把我想要的所有食物放在托盘上。自助服务使我能够做出(糟糕的)食物选择。但是,当涉及到数据平台时,这意味着什么?
自 2001 年成立以来,敏捷已被证明是一种有效的方法。敏捷软件工程赋予软件工程师权力。赋予数据科学家权力的方法是让他们访问数据。
数据科学家和分析师在数据发现阶段花费(太多)时间。在许多情况下,他们会在某个表的某个随机列中找到一条数据,并押注这就是他们需要的事实。有时它有效,有时你的 PB&J 吐司不会掉在果冻的一边。
赋予数据科学家权力意味着您不仅必须让他们访问基本的字段目录,还要让他们访问精确的定义、主动和被动元数据、反馈循环等等。他们是你的顾客,你想成为这个 5 星级 Yelp 自助餐厅,而不是这个糟糕的 1 星级小屋。
四. 联邦计算治理原则
这个原则的每一个字都有非常重要的意义。让我试着向你传达他们的重要解释。
信息技术在我们的日常生活中变得无处不在。各州和政府已制定法律来管理个人数据的处理和使用方式。著名的例子包括欧洲的 GDPR (2016)、加利福尼亚的 CCPA (2018) 和法国的国家信息与自由委员会 (1978)。当然,这些限制并不是企业治理的唯一推动力。像 PayPal 这样的公司通常有可能超出法律要求的数据治理规则和保护措施。
但是为什么要推动计算治理而不仅仅是数据治理呢?因为数据治理太局限了。即使您在治理中包含元数据(当然您也这样做了),您仍然缺少与您的系统相关联的整个计算资源生态系统。在基于云的现代世界中,您必须考虑更多资产。从数据扩展到计算治理是有意义的。
您的数据治理团队创建适用于整个组织的策略,域团队将遵循这些策略来实现企业级的一致性和合规性。然而,领域团队拥有量子级别的本地治理,最大限度地发挥团队的专业知识。
四大原则
就像大仲马的四个火枪手一样,数据网格的四个原则是相互交织的。
每个原则相互影响,在设计和构建数据网格时,不能孤立地看待一个原则:您需要同时在四个方面取得进展。这比看起来容易,因为您将看到 PayPal 如何构建这样的数据网格。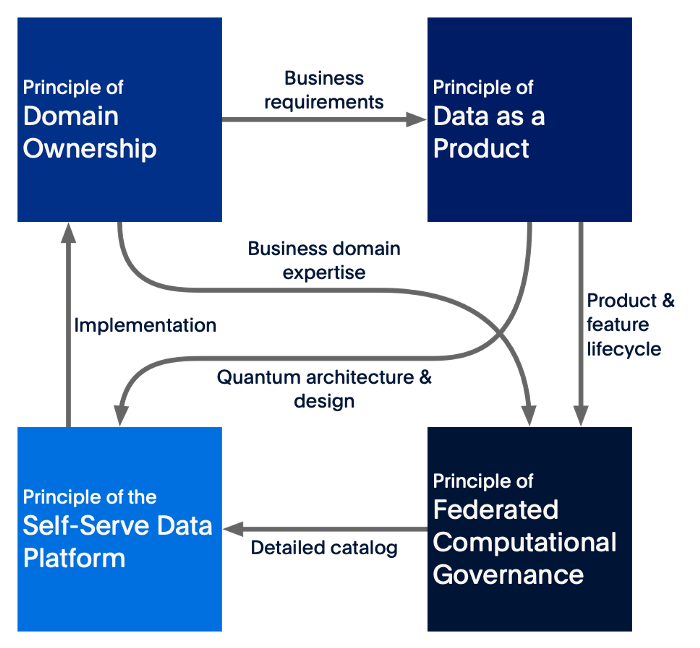
图 6 - 将一个原则的影响映射到其他原则的尝试。
构建我们的第一个数据量子
既然您已经阅读了有关动机、机会和管理原则的内容,似乎是时候构建您的第一个数据量子了,或者更准确地说,是在实施之前对其进行架构。
在构建整个数据网格之前,您需要关注每个数据量。数据网格是数据量子的组合。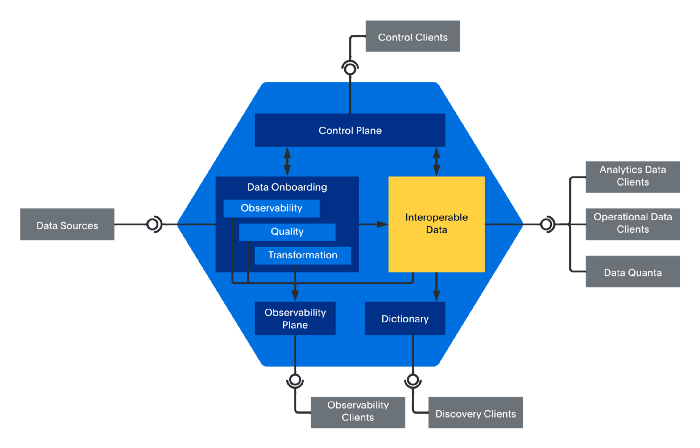
图 7 — 展开数据量子,里面是什么?
您可以将数据量子划分为五个子组件: • 字典, • 可观察性平面, • 控制平面, • 数据载入,以及 • 可互操作的数据。
字典接口是您被动元数据的宝贵芝麻。您的数据量子用户无需身份验证即可连接到字典。然后,他们的数据发现被极大地简化,因为他们可以以非常互动的方式浏览字典,而无需特定权限、额外描述和对数据沿袭的访问。当他们找到他们需要的东西时,他们可以轻松地检查他们是否有权访问或请求访问数据。
可观察性平面在数据量子的内置可观察性和 REST 客户端之间提供了一个接口。这允许数据科学家衡量数据量中的数据质量,并确定数据量是否符合他们的 SLO(服务水平目标)预期。
控制平面提供对 REST API 的访问,您可以在其中控制载入和数据存储。如果您想在数据量子中创建数据集的新版本,那么可以使用 API 调用。您是否需要控制应在数据载入中应用哪些数据质量规则?有一个 API 调用。该接口主要面向管理数据量的数据工程师。
可以想象,对于每个数据量子来说,这三组 API 都是相似的:不需要为每个数据量学习新的 API。为了简化您的使用,您可以将您的 REST API 包装在一个可通过笔记本访问的 Python API 中。
数据载入组件是您使用类固醇的旧数据管道。在许多(如果不是全部)数据网格之前的数据工程项目中,重点是数据管道。数据网格将管道放回原处。管道很重要,但它是数据载入的一个元素,例如可观察性或应用程序数据质量规则。在这个组件中添加所有这些功能可以保护经典的、经常失败的、脆弱的 ETL 过程。是的,管道是球队四分卫的日子已经过去了。
最后但并非最不重要的一点是,可互操作模型是以可消费的方式为您提供关键数据。我可以将此组件表示为您可以在旧架构图中看到的经典圆柱体,但请记住,数据量子公开的数据并不总是相关的。
数据量子的承诺是将应用程序与数据分离。这会对数据量子内部的数据建模产生影响。
欢迎来到数据网格
到目前为止,您已经了解了很多关于数据量子(复数:data quanta)的知识。希望您能看到数据量子的价值,但是数据网格会给大量数据量子带来什么额外价值呢?
一组数据合约管理每个数据量:主数据合约定义了数据量与其用户之间的关系。它还描述了可互操作模型和 SLA(服务级别协议)的详细信息。这种面向消费者的数据合约也可以称为输出或用户数据合约。
图 8 说明了数据契约的作用。一个数据量子可能有多个数据合约作为输入,并为其消费者提供一个数据合约。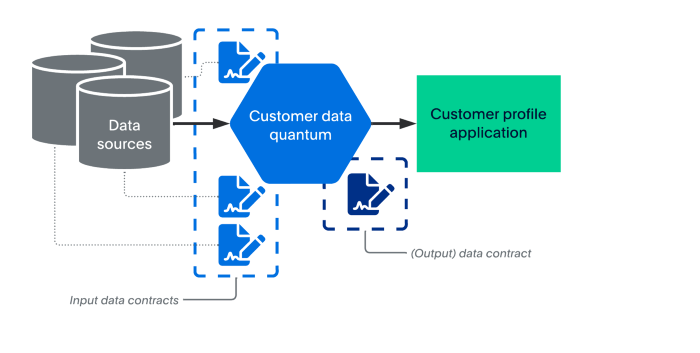
图 8——数据契约的重要性:它定义了生产者和消费者的关系。
当数据量已网格化时,如图 9 所示,生成的数据量会从源数据量继承数据契约。这种机制简化了互操作性、提高了数据质量并缩短了上市时间。
当您阅读本文时,我们的团队正在应对这一挑战。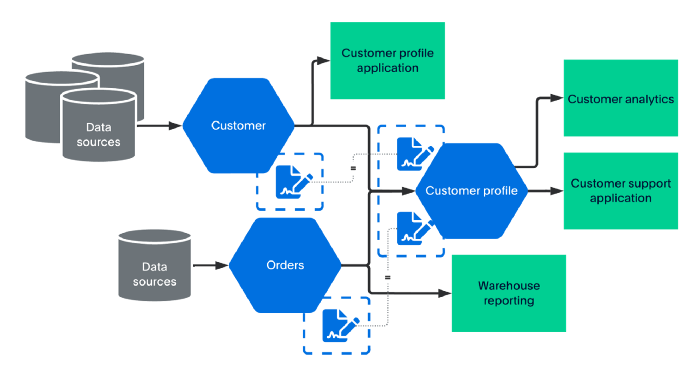
图 9 - 网格化数据量增加了数据网格的交付值,而不会影响数据新鲜度。
挑战
构建数据量子的道路充满了好主意,但魔鬼显然在实施中。
不过,这里有一些建议可以帮助您入门。
与任何颠覆性技术和方法一样,准备好引导您的用户完成这一过渡。许多数据工程师生活在神圣不可侵犯的数据管道中,将他们的偶像简化为网格中的一个组件可能会令人痛苦。
让你的领导层为建立新平台做好准备:他们不应该在你开始两周(甚至三周……)后期待结果。
与所有产品开发一样,清楚地确定您的用户是谁以及他们当前使用的工具。您可能需要转换或扩展他们的工具,这可能会产生摩擦和阻力。
事实是那里没有“数据网格产品”。可能有可以组装的砖块、元素或组件来帮助您构建网格(Spark 仍然是一个出色的引擎,可以大规模执行您的数据转换——等等)。然而,没有什么能比得上 OTS(现成的)平台,无论是商业的还是开源的。
该领域缺乏软件供应商促进了创新,但同样混乱。接下来的几个月将告诉我们,我们是否在用户体验、技术选择和实施方面做出了正确的选择。
Jean-Georges “jgp” Perrin 是 PayPal 专注于构建创新和现代数据平台的技术领导者,AIDAUG 总裁,Spark in Action, 2nd edition (Manning) 的作者。