在这篇博客中,将讨论在行业中看到的一些设计模式。
数据传输
1、零拷贝数据传输
系统级——零拷贝是指将数据直接从磁盘文件拷贝到网卡设备,无需应用程序。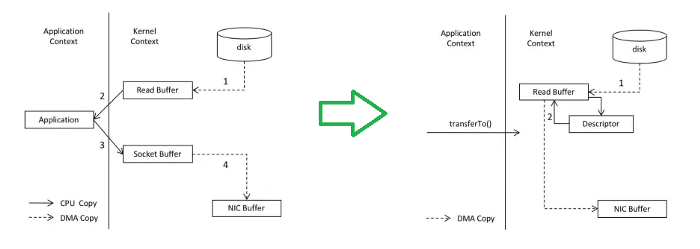
在新方法中,避免了多次上下文切换。transferTo在 Java 中使用sendfile()Linux 系统。这种方法现在已被广泛用作 NGINX 和KAFKA中支持的数据传输技术。
2、元数据级别
这个零副本是指数据元数据的副本,而不是在需要克隆或替换的情况下的实际数据。这是基于存储和计算解耦的基础。计算是指通过元数据而不是直接通过数据进行存储。为微分区保留元数据,以便在更新场景中仅更新某些特定的元数据。
3、排队 n 路数据传输
多个应用程序使用相同的数据。不是源将数据发送到多个系统,而是源将数据发送到队列/主题,然后消费者单独消费数据。
数据建模
随着多样化数据源和多样化消费模式的增加,良好的数据建模策略对成功至关重要。
1、规范化
- 模拟数据源
- 消除冗余
- 基于存储效率的设计
- 通常与数据集市一起使用
- 涉及很多连接
2、非规范化
- 也称为维度建模
- 基于消费/业务需求的设计
- Star vs Snowflake 模式schema
- 维度——代表可能性
- Facts Tables - 表示可能性的实现
- 缓慢变化的维度
3、数据保险库vault
- Hubs——代表核心业务概念及其元数据
- 链接Links - 表示集线器之间的关系
- Satellites - 上下文/描述性值,变化类似于 II 型 SCD
- 原始、业务和表示层
- 适合 Lakehouse 范式
4、宽表
- 宽非规范化表
- 也称为一个大表
- Matrelialize 将事实表和维度表连接到 OBT
- 示例 - BigQuery
5、自动化数据管道
- 使用 Liquibase 或 Flyway 作为数据库对象的 CD 方法。
- 使用 Airflow 和 DBT 等工具进行管道和转换即代码。
数据仓库
1、星型模式的并行加载
在能够加载任何事实表之前顺序加载维度表是星型模式的瓶颈之一。
- varchar(32) 维度表的代理键
- 禁用外键约束
- 计算暂存区维度表的键的MD5散列
- 并行加载维度表和事实表
- 重新启用外键约束
2、事实表子集
基于大型事实表的访问模式,我们可以创建第二个事实表,其中仅包含具有过滤数据的子集。我们可以在填充较大的事实表时在同一批次中填充较小的事实表。