使用 Apache Pinot、Kafka 和 Debezium 构建可扩展的分析基础架构以提供低延迟的面向用户的分析
这篇文章将是一篇很长的文章。所以让我总结一下重要的事情。
- 什么是面向用户的分析?
- 面向用户的分析的商业价值是什么
- 为什么很难实现面向用户的实时分析?
- 构建分析基础架构以提供面向用户的分析有哪些选择?
Airbeds——Airbnb 的克隆
让我举一个现实的例子来为我们的讨论做铺垫。
假设我们正在构建“ Airbeds ”,这是流行的度假租赁平台 Airbnb 的克隆版。Airbeds 是一个典型的双边市场,房东在 Airbeds(列表)上列出他们的财产,允许客人在到达之前搜索和预订。
Airbeds领域模型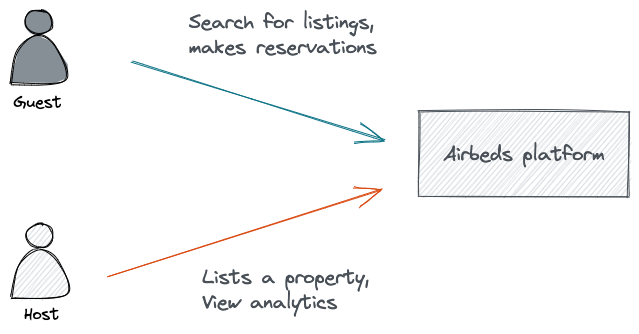
为了衡量他们的房源在 Airbeds 上的表现,我们需要为房东提供一个分析仪表板,显示特定时间范围内的以下指标。
- total_nightly_revenue:在该持续时间内进行的预订产生的总收入。
- total_nightly_revenue_by_listing:按单个列表列出的总预订收入。例如,哪个上市带来了最高和最低的收入?
- average_nightly_rate:每晚总收入除以预订房源的天数。
- average_length_of_stay:这是客人每次预订的平均入住晚数。
这些指标应该绘制在这样的 UI 上:
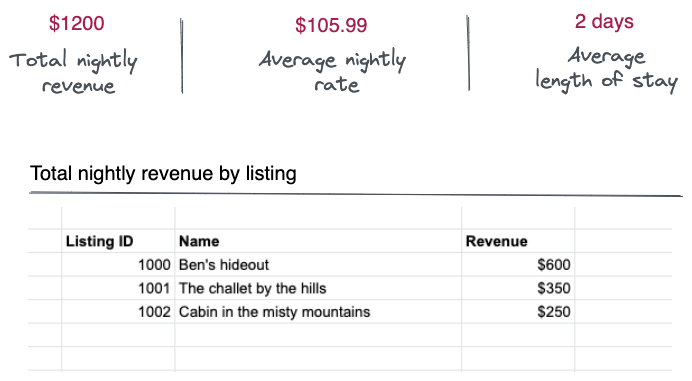
Airbeds 平台中的所有房东都可以查看此仪表板。那么我们如何构建它呢?
在进入技术之前,让我们看看“面向用户的分析”的重要性。
面向用户的分析的商业价值
“每个人都是数据人,但只有少数人可以访问洞察数据”——这即将改变! — Kishore Gopalakrishna,StarTree Inc
让我们进一步澄清术语“面向用户的分析”,以了解其在业务环境中的重要性。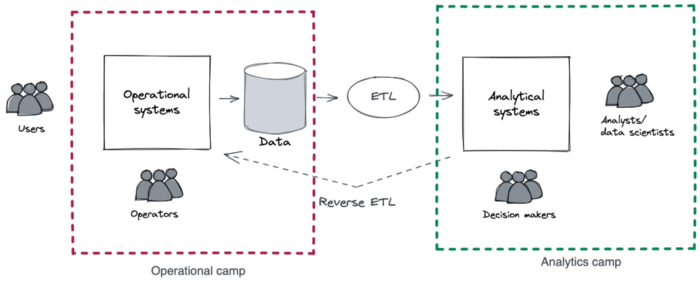
从历史上看,数据驱动型组织中存在两个阵营:运营阵营和分析阵营。
运营营地由与客户和最终用户互动的机器和操作员组成。这些交互产生的数据作为副产品,通过 ETL 工具将其提取并移动到分析系统中。
分析阵营由分析师、决策者和高级管理人员组成,他们利用分析工具从处理过的运营数据中获得洞察力。
到目前为止,分析阵营是唯一可以访问分析的实体。但不长久。
Google、Facebook 和 LinkedIn 等互联网规模的公司已经铺平了将分析作为数据产品向其客户和用户公开的道路。
例如:
- Google 将其搜索和网页排名公开为 Google Analytics。
- Facebook 向广告商公开了其用户参与度指标。
- LinkedIn 向其用户公开了“谁查看了我的个人资料”。
客户和最终用户,他们是一样的吗?
客户通过消费产品并最终为其交付的价值付费,从而直接从产品中受益。用户消费该价值,但可能会或可能不会为此付费。
有时,客户可以是用户——浏览 amazon.com 的消费者会购买星级最高的产品,同时扮演这两个角色。但是,请考虑比萨饼店的经理使用 ERP 系统进行库存补货的情况。在这种情况下,经理是 ERP 系统的最终用户,而不是直接客户。
从商业角度来看,双方都应该可以访问分析。
用户分析——它创造了什么价值?
为简单起见,从现在开始,我将使用术语用户来指代客户和最终用户。
现在让我们回到我们的 Airbeds 用例。
分析仪表板对于房东衡量房源性能并采取纠正措施以改善整体业务至关重要。
例如:
- 指标total_nightly_revenue有助于识别表现良好的列表和需要注意的列表。
- 指标average_nightly_rate有助于将当前汇率与市场中位数进行比较。如果市场繁荣,主办方可以提高利率。
- 指标average_length_of_stay有助于确定客人不喜欢特定房源的原因。
从本质上讲,获得洞察力可以帮助用户更好地开展业务,及时采取行动纠正路线,并提供更好的价值。
如果您仍然不相信,我建议您阅读以下文章。
为什么提供面向用户的分析很难?
当分析仅限于分析阵营时,分析师接受的培训是处理缓慢的查询和包含陈旧数据的仪表板。组织中只有少数决策者。这些痛点并不重要,因为它是内部的。
但是,在向运营营地提供分析时,它不应该遵循同样的做法。
例如,Airbeds 平台可以拥有数百万台主机,其中绝大多数将同时访问分析。此外,结果应在亚秒级延迟内显示,以获得更好的用户体验。底层分析基础架构必须具有可扩展性、高性能和可靠性,才能承受高查询吞吐量 (QPS) 并以超低延迟交付结果。
在本文中,我想列出几种构建分析基础架构以向用户提供分析的方法。这可能直接适用于您的组织,也可能不适用。但至少您可以将它们用作指导原则,以避免重新发明轮子。
选项 1:从 OLTP 数据库提供分析服务
让我们从最直接的选项开始,我们直接从运营数据库提供分析服务。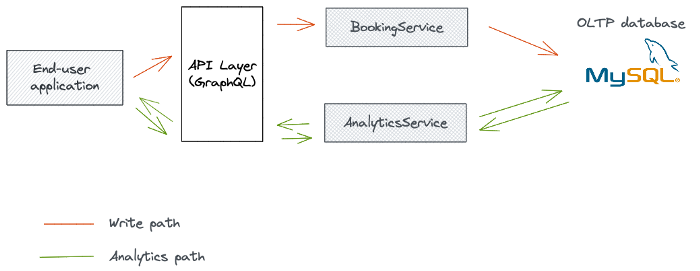
该架构由以下部分组成:
- 前端:分析仪表板通过网络和移动渠道提供给用户。
- API层:代理前端和微服务之间的请求。此外,它还处理 API 身份验证 (OAuth)、协议转换和速率限制。
- 微服务:查询数据库并使用分析数据响应 API 层。
- 操作数据库:此 OLTP 数据库将预订记录保存在预订表中。
假设数据库是 MySQL 并且保留表具有以下架构:
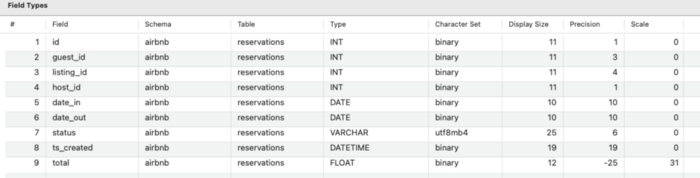
预订表的架构
以下查询生成total_nightly_revenue指标。
SELECT sum(total) as total_revenue FROM reservations where date_in > '2021-01-01' and date_in < '2021-01-31' and host_id=1; |
除了date_in和host_id(正在查看分析的主机)上的聚合和过滤器谓词之外,这似乎并不复杂。
下面计算average_length_of_stay。
select avg(datediff(date_out, date_in)) as length_of_stay FROM reservations where date_in > '2021-01-01' and date_in < '2021-01-31' and host_id=1; |
除了过滤子句之外,查询还有一个聚合函数 (avg) 和一个投影函数。
最后,此查询返回total_nightly_revenue_by_listing。
SELECT listing_id, sum(total) as revenue_per_listing FROM reservations where date_in > '2021-01-01' and date_in < '2021-01-31' and host_id=1 group by listing_id order by revenue_per_listing desc; |
这是迄今为止最复杂的查询,包含聚合、过滤子句、分组依据和排序。
挑战
当保留表随时间增长时,这些查询将变得越来越慢,从而导致数据库出现瓶颈。这导致前端性能低下。智能索引将带我们到一定程度。但很快,它也将达到一个极限。
OLTP 数据库旨在一次处理较少的记录,而不是通过大规模聚合、过滤、分组和排序来处理 OLAP 查询。
选项 2:从 NoSQL 数据库提供分析
前一个的主要限制是 OLTP 数据库的读取性能较差。选项 2 通过使用读取优化的数据库来提供分析微服务来解决这个问题。
新架构将有两个新元素,NoSQL 数据库和 ETL 管道。
受数据新鲜度限制
ETL 管道定期从保留表(在 MySQL 中)提取记录,应用转换,并将最终结果加载到 NoSQL 数据库中,如 MongoDB、Cassandra 或 AWS Dynamodb。
我们可以使用 Apache Spark、Beam、Hive 甚至 Hadoop 作业等技术来构建 ETL 管道。其目标是利用非规范化和预聚合技术将源数据转换为读取优化格式。例如,我们可以在管道执行期间为每个主机预先计算指标,以防止 NoSQL 数据库按需聚合它们。
挑战
选项 2 带来了两个挑战;第一个与数据新鲜度有关。ETL 管道以批处理模式运行,导致前端显示陈旧数据。随着数据的增长,管道执行时间也会增加,迫使我们在管道运行之间保持较长的间隔。
其次,我们将管理两个分布式系统,即 NoSQL 数据库和 ETL 管道。这增加了运营负担。
选项 3:从实时 OLAP 数据库提供分析
选项 2 几乎是完美的,除了数据新鲜度问题。第三个选项通过使用带有流式 CDC 管道的实时 OLAP 数据库来解决这个问题。
获得及时和一致的分析是该架构的目标
这些是添加到架构中的新组件。
- 变更数据捕获(CDC)机制(Debezium)
- 事件流平台(Kafka)
- 流式 ETL 流水线(Flink、Kafka Streams 等,可选)
- 实时 OLAP 数据库 (Apache Pinot)
使用 Debezium 实时捕获 OLTP 变化
与周期性的批处理 ETL 过程不同,像Debezium这样的 CDC 工具可以捕获对数据库所做的更改。Debezium 部署在 Kafka Connect 上。
在我们的例子中,我们可以使用 Debezium 的 MySQL 连接器来流式传输来自预订表的更改。数据库更改被编码为事件并写入 Kafka 中配置的主题。
将实时变化事件同步到 Apache Pinot
Apache Pinot 是一个实时分布式 OLAP 数据存储,用于提供可扩展的低延迟实时分析。它可以从 Kafka 等流式数据源和批处理数据源中摄取数据,并提供一层索引技术,可用于最大限度地提高查询性能。此外,流摄取是实时发生的,使数据可在几秒钟内进行查询,使我们能够以更高的幅度保持数据新鲜度。
Pinot 可以配置为从 Kafka 主题中摄取事件,其中 Debezium 流式传输来自预订表的更改事件。摄取的事件会立即建立索引,允许前端在保持数据新鲜度的同时进行查询。Pinot 还支持upserts,有助于读取变化流中的最新值。
例如,假设客人现在进行预订。这将在几秒钟内反映在分析仪表板中,让主持人看到及时的见解。
使用流处理器进行动态转换
有时,来自 Kafka 的更改事件需要经过处理步骤才能登陆 Pinot。这包括转换、连接和时间聚合。
我们可以通过在两者之间添加像 Apache Flink 这样的流处理器来实现这一点。然后 Flink 从更改事件主题中消费,应用转换,并写入 Pinot 从中摄取事件的最终主题。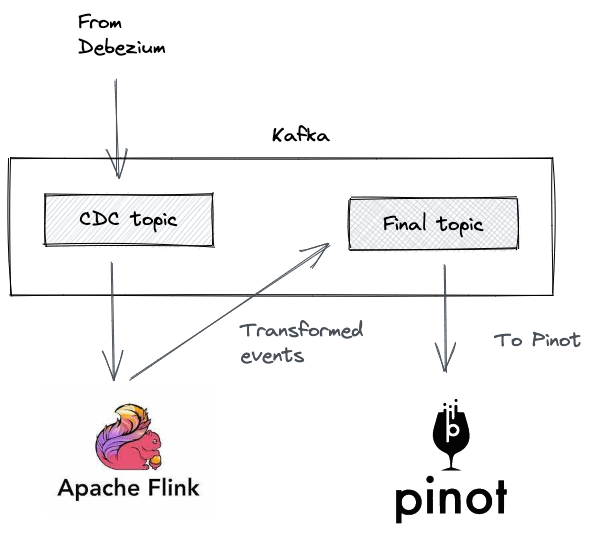
流式 ETL
但是,这对于大多数部署来说是可选的。一旦数据被摄取,Pinot 还可以使用 UDF 执行查找连接和转换。
挑战
这种架构中唯一的挑战是部署的复杂性,需要管理和监控的组件很多。但是当组织规模扩大时,及时和一致的分析的好处超过了操作的复杂性。
概括
数据即产品的概念将在这十年中发挥关键作用。组织中的每个人,包括员工和客户,都将使用数据进行决策。因此,民主化分析是当今组织的必备条件。
在实施面向用户的分析时,没有硬性规定。我建议从最便宜和最直接的选择开始,看看它失败的地方。如果您从小流量开始,即使是 OLTP 数据库也是一个很好的起点。您可以考虑根据您组织的预算、技能组合和对新分析的需求转向选项 2 和 3。