本文将帮助您以您可以配置的标准方式自动化您的工作。它还可以通过各种方式触发您的作业并执行您的业务代码。调度作业的方法有很多,包括cron 作业和Windows 任务调度程序,但这些解决方案对用户不友好并且依赖于平台。
如果你在云环境(AWS、GCP、Azure 等)上运行,那么你可以使用云调度器产品,但如果你在本地开发,你可以在不同的框架上开发一个带有调度器服务的自定义解决方案,例如,Quartz或Hangfire。我们有很多理由设计一个新的调度系统;高可用性、与分布式环境兼容、可扩展、可重试和可监控,我们开发了一个基于事件驱动架构的调度系统。
大图
调度程序服务是一个管理作业执行的系统,通常基于调度或其他一些触发器。它由三个组件组成:作业触发器、调度程序作业数据收集器/消费者和作业执行器。作业触发器确定何时运行作业,数据收集器/消费者收集有关作业的信息并将其传递给执行程序,执行程序根据它们的定义运行作业。调度程序服务确保作业及时有效地运行。
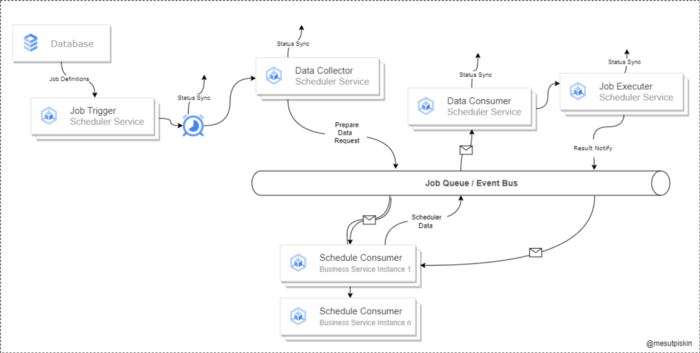
作业触发模块是更大软件系统的一部分。它的主要功能是从数据库中检索有关计划作业的必要信息,并根据 cron 计划启动作业的执行。
数据收集器/消费者模块是系统的另一个组件,负责从调度程序接收有关计划作业的数据,并使用 Kafka 消息系统将其发送到适当的业务服务。该模块还为进一步处理准备数据。
作业执行器模块是系统的最后一个组件,负责执行预定作业的业务逻辑,并在完成后发送有关其状态的通知。
在此实现中,系统是使用 Java Spring 框架构建的,这是一种流行的 Java 应用程序开发框架。数据存储在 PostgreSQL 数据库中,使用 Kafka 作为消息系统,方便系统不同组件之间的通信。虽然 Kafka 是事件总线的不错选择,但在这种情况下,也可以使用其他事件总线产品,例如 RabbitMQ。
模块 1:工作触发器
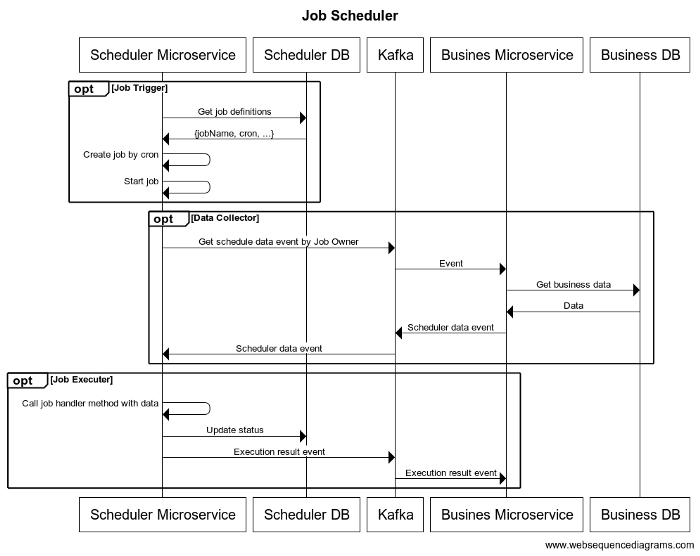
该模块是作业计划微服务的一部分,负责从数据库中获取作业定义并使用 cron 参数触发作业。作业定义具有不同的属性:id、作业名称、描述、状态、cron定义、处理程序方法和所有者服务。handler方法是你在scheduler service中的业务代码,owner service是数据检索业务服务。
作业触发器从数据库中获取作业描述数据,并在时间到来时执行作业,如 cron 所定义。
{ |
对于 Job Trigger 模块的基本实现:
import org.springframework.beans.factory.annotation.Autowired; |
模块 2:数据收集器
数据收集器/消费者模块负责通过 Kafka 将调度程序作业数据与业务服务进行通信,并为作业执行器准备数据。该模块侦听业务服务发布数据的 Kafka 主题,处理数据并将其发送给作业执行器。数据收集器/消费者还维护作业的状态,例如“待定”、“进行中”和“已完成”,并相应地更新数据库。该模块对于确保作业执行器在正确的时间拥有正确的数据来执行作业至关重要。
这是数据收集器/消费者模块可以处理并发送给作业执行器的示例事件数据:
{ |
此事件数据包含“第一份工作”工作的用户信息。数据收集器/消费者模块将接收此数据,对其进行处理,并在作业完成后将其发送给作业执行器。这确保可以使用最新数据执行作业。
对于 Data Collector 模块的基本实现,使用 Java Spring Framework 和 Kafka:
import org.springframework.beans.factory.annotation.Autowired; |
此代码侦听名为“data-collection-service”的 Kafka 主题并尝试处理传入的数据。它更新作业的状态并将数据发送到工作模块。这只是一个示例,您可以修改代码以满足您的需要。
模块 3:作业执行器
作业执行器模块负责执行与作业关联的业务代码,并在作业完成后发送通知。该模块接收来自数据收集器/消费者的数据,并使用作业定义中指定的“处理程序”方法来执行业务代码。作业完成后,作业执行器向所有者服务发送通知并更新数据库中的作业状态。该模块对于确保正确执行业务代码以及通知所有者服务作业完成至关重要。
示例基本实现
public class JobExecutorService { @Autowired |
总之,我们的调度程序服务是一个强大的工具,可以帮助我们以用户友好且独立于平台的方式自动化您的工作。通过使用具有事件驱动架构的调度程序服务,您可以使您的作业高度可用、与分布式环境兼容、可扩展、可重试和可监控。通过正确的技术堆栈和设计,您可以开发满足您特定需求的自定义调度程序服务。
我们的自定义调度系统优于 Quartz、Hangfire 等产品的主要原因之一是它与分布式环境的兼容性。我们的系统被设计为具有高可用性,可以优雅地处理故障,确保作业一致可靠地执行。此外,我们的系统是可扩展的,可以轻松定制以满足不同服务的特定需求。这使得它比 Quartz、Hangfire 等可能无法提供相同级别定制的产品更加灵活和通用。
我们定制解决方案的另一个优势是它能够重试失败的作业。这在微服务架构中尤其重要,在微服务架构中,服务可能相互依赖,并且一个服务的故障会影响其他服务。通过实现重试机制,即使出现暂时性的失败或错误,我们也可以确保作业成功执行。总的来说,我们的自定义调度系统提供了许多优于 Hangfire 等产品的优势。它具有高可用性、与分布式环境兼容、可扩展、可重试和可监控,使其成为微服务架构中自动化作业的卓越解决方案。