Supabase 现在提供了一个新的 PostgreSQL 扩展:pgvector一个开源向量相似性搜索。
什么是嵌入?
嵌入捕获文本、图像、视频或其他类型信息的“相关性”。这种相关性最常用于:
- 搜索:搜索词与文本正文的相似程度如何?
- 建议:两种产品有多相似?
- 分类:我们如何对文本进行分类?
- 聚类:我们如何识别趋势?
让我们探索一个文本嵌入的例子。假设我们有三个短语:
- “猫追老鼠”
- “小猫捕食啮齿动物”
- “我喜欢火腿三明治”
你的工作是将具有相似含义的短语分组。
短语 1 和 2 几乎相同,而短语 3 具有完全不同的含义。
尽管短语 1 和 2 相似,但它们没有共同的词汇。然而它们的含义几乎相同。我们如何教计算机这些是相同的?
人类语言
人类使用文字和符号来交流语言。但是孤立的话大多是没有意义的——我们需要从共享的知识和经验中汲取灵感才能理解它们。只有当你知道谷歌是一个搜索引擎并且人们一直将它用作动词时,“你应该谷歌它”这句话才有意义。
同样,我们需要训练一个神经网络模型来理解人类语言。一个有效的模型应该在数百万个不同的例子上进行训练,以理解每个单词、短语、句子或段落在不同上下文中的含义。
那么这与嵌入有什么关系呢?
嵌入如何工作?
嵌入将离散信息(单词和符号)压缩为分布式连续值数据(向量)。
如果我们把之前的短语画在图表上,2 个维度:X 轴和 Y 轴。
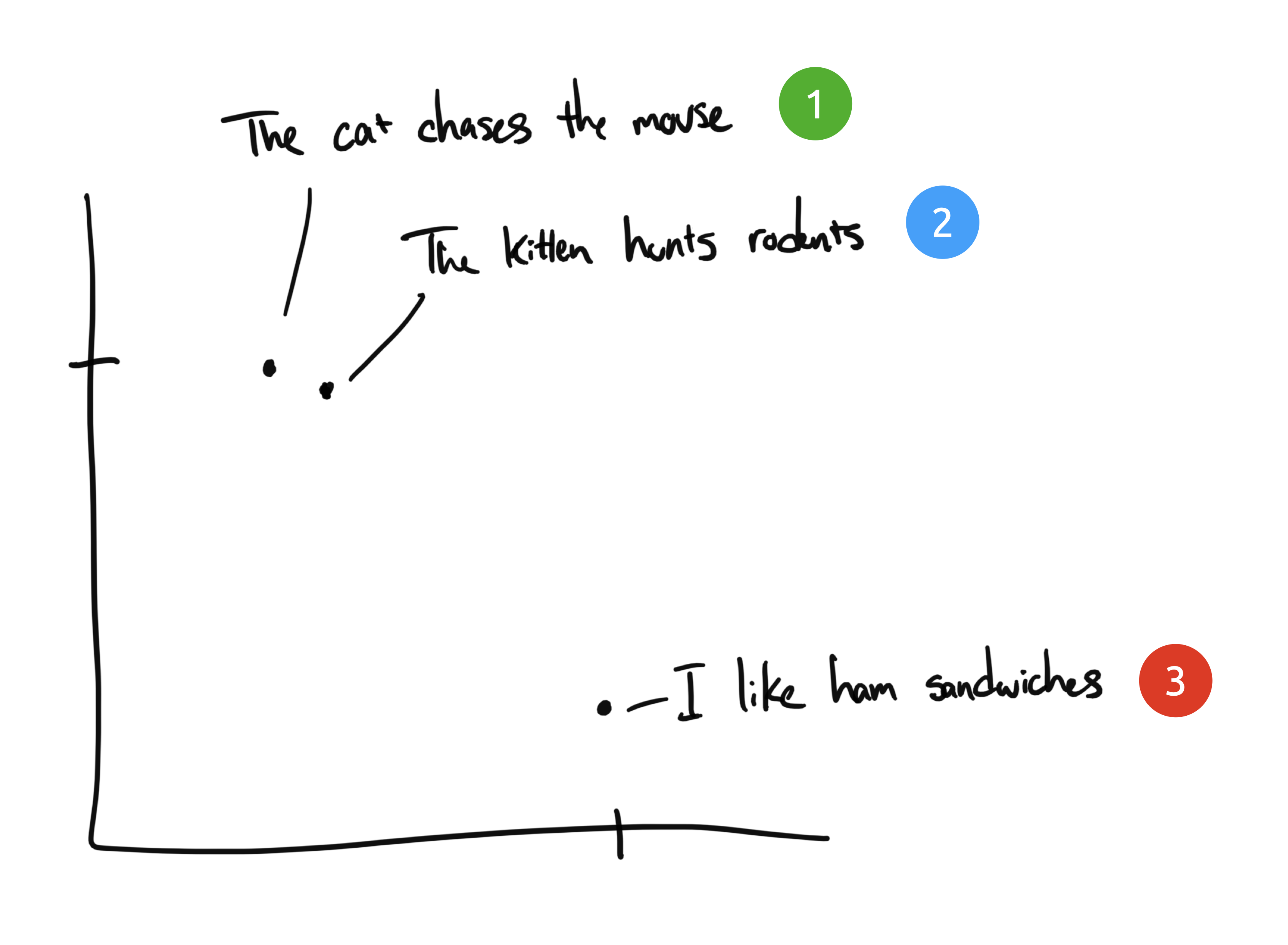
短语 1 和 2 将彼此靠近绘制,因为它们的含义相似。我们希望短语 3 存在于很远的地方,因为它不相关。如果我们有第四个短语,“萨利吃了瑞士奶酪”,它可能存在于短语 3(奶酪可以放在三明治上)和短语 1(老鼠喜欢瑞士奶酪)之间。
在此示例中,我们只有 2 个维度:X 轴和 Y 轴。实际上,我们需要更多的维度来有效地捕捉人类语言的复杂性。
OpenAI 嵌入
OpenAI 提供了一个API,可以使用其语言模型为文本字符串生成嵌入。您向它提供任何文本信息(博客文章、文档、您公司的知识库),它会输出一个表示该文本“含义”的浮点数向量。
与我们上面的二维示例相比,他们最新的嵌入模型text-embedding-ada-002将输出 1536 维。
为什么这有用?一旦我们在多个文本上生成了嵌入,使用余弦距离等向量数学运算来计算它们的相似程度就很简单了。一个完美的用例是搜索。您的过程可能看起来像这样:
- 预处理您的知识库并为每个页面生成嵌入
- 存储您的嵌入以供稍后引用(更多信息)
- 构建一个提示用户输入的搜索页面
- 获取用户输入,生成一次性嵌入,然后对预处理的嵌入执行相似性搜索。
- 将最相似的页面返回给用户
嵌入实践
在小范围内,你可以将你的嵌入存储在CSV文件中,将它们加载到Python中,并使用numPy这样的库来计算它们之间的相似性,比如余弦距离或点乘。OpenAI有一个实例,就是这样做的。不幸的是,这很可能不能很好地扩展。
- 如果我需要存储和搜索大量的文档和嵌入(比内存中能容纳的还要多),怎么办?
- 如果我想动态地创建/更新/删除嵌入物呢?
- 如果我不使用Python怎么办?
使用 PostgreSQL
pgvector是 PostgreSQL 的一个扩展,允许您在数据库中存储和查询向量嵌入。让我们试试看。
详细点击标题
构建更智能的搜索功能
ChatGPT 不只是返回现有文档。它能够将各种信息同化为一个单一的、有凝聚力的答案。为此,我们需要向 GPT 提供一些相关文档,以及可用于制定此答案的提示。
OpenAItext-davinci-003 补全模型最大的挑战之一是 4000 个代币的限制。您必须在 4000 个标记内同时满足您的提示和生成的完成。如果你想提示 GPT-3 回答有关你自己的自定义知识库的问题,而这些问题永远不会出现在单个提示中,这就会变得很有挑战性。
嵌入可以通过将您的提示分成两个阶段的过程来帮助解决这个问题:
- 在您的嵌入数据库中查询与问题相关的最相关文档
- 注入这些文档作为 GPT-3 在其答案中引用的上下文
总结
在 Postgres 中存储嵌入打开了一个充满可能性的世界。您可以将搜索功能与遥测功能结合起来,添加用户提供的反馈(竖起大拇指/竖起大拇指),让您的搜索感觉与您的产品更加融合。