训练/研究微小的GPT很有趣,因为它变得很容易可视化,并对整个动态系统有一个直观的感觉。
这是一个带有两个标记0/1和上下文长度为3的小型GPT,将其视为有限状态马尔可夫链。它在序列“111101111011110”上训练了50次迭代。
Transformer的参数和架构修改箭头上的概率。
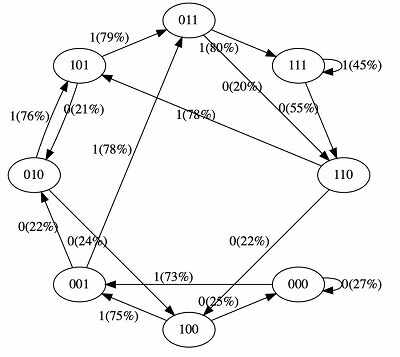
例如,我们可以看到,:
- 在训练数据中,状态101确定地过渡到011,所以该过渡的概率变得更高(79%)。不是接近100%,因为我们只做了50步的优化。
- 状态111转为111和110的概率各为50%,模型几乎学会了(45%,55%)。
- 像000这样的状态在训练过程中从未遇到过,但有相对尖锐的过渡概率,例如,73%的概率会转到001。这是转化器中归纳偏见的结果。我们可以想象,希望这个概率是50%,但在实际部署中,几乎每个输入序列都是独一无二的,不存在于训练数据中。
详细点击标题