由于我的新电动自行车在商店里而无法再次骑着它去上班(这次是因为电线问题导致自行车无法运行!),我开始考虑如何在我的自行车中创造一些冗余设置,这样我就不会因为简单的维护或供应链问题而一次被困在地铁上数周。如果我在修理当前自行车时要骑另一辆自行车怎么办?这肯定会有帮助,但电动自行车很贵,而且我在伦敦舒适的公寓里几乎没有空间存放备用自行车。
信不信由你,这个问题类似于我作为数据库开发人员在日常工作中遇到的问题。就像自行车一样,数据库也会崩溃!有时硬件会莫名其妙地发生故障,或者网络配置已更改并且您的数据库无法再访问。当然,万一发生故障,您始终可以将数据从备份恢复到新硬件上,但是这样您就会陷入停机和可能丢失数据的境地;并且假设您最近测试了还原过程以确保它甚至可以正常工作!即使您能够无缝地运行恢复,就像我需要等待商店修好我的自行车才能开始骑它再次上班一样,您也需要等待恢复完成和新的使用前要配置的数据库。
但幸运的是,与我的自行车情况不同,现代数据库能够在出现问题时保持在线并继续正常运行。这在时间序列数据库的世界中尤为重要,这些数据库被设计为不断写入数据,在许多情况下几乎是不间断的。没有时间从备份中恢复,因为在任何停机期间都可能丢失宝贵的数据。
这怎么会发生?答案是通过复制!通过同步多个数据库节点并构建一个解决方案,以便在节点发生故障时将执行转移到健康节点(写入故障转移),数据库可以确保没有数据丢失。这就像我在上下班途中轮胎漏气了,可以在路中间当场换上一辆备用自行车!看起来很酷,对吧?
当我们开始使 QuestDB 分布式的旅程时,我们花时间分析了几种流行的时间序列/OLAP 数据库如何实现高可用性,以突出每种方法的优缺点。除了对基础知识的回顾,我们还分享了 QuestDB 自己的方法和我们对未来的计划。
故障转移
我们来看一个场景,当应用程序写入数据库时,突然断网了。在这种情况下应该怎么办?
应用程序应切换到复制节点并继续插入数据。
例如,如果我有一个应用程序写到DB Node 1和副本DB Node 2,我可以把这个场景画成一个序列图:
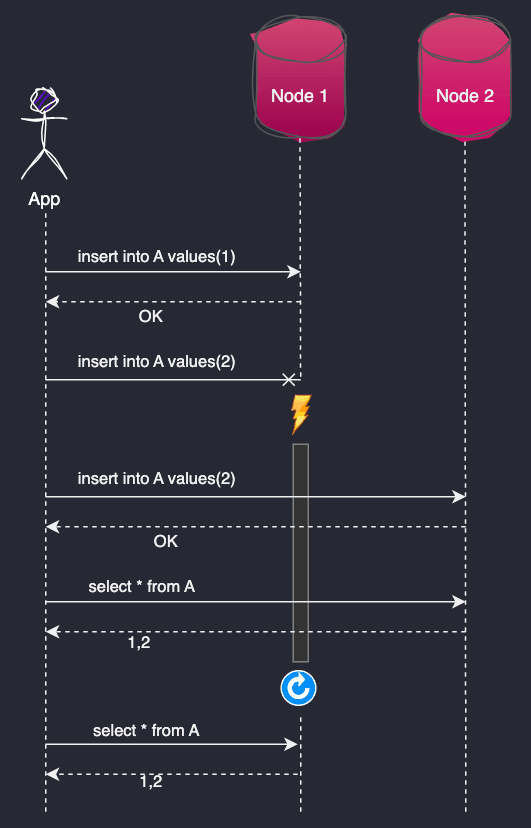
看上去很简单,但是让数据库在这种舞蹈中发挥其作用容易吗?我相信不是这样的。为了实现这一点,数据库必须能够通过多个节点向同一个表A写入数据。在一般情况下,数据库还必须发展模式,以支持从多个节点添加/删除列,并在所有副本上以完全相同的顺序应用事务。这是因为有些事务,如INSERT和UPDATE,在同一行上执行,如果以错误的顺序应用,会有不同的结果。
总而言之,数据库需要能够:
- 使用多个数据库节点(多主复制)将数据写入同一个表或将数据镜像到具有自动故障转移功能的只读复制节点
- 发展表模式,以便可以从多个连接同时添加相同的表列
- 维护跨副本节点的写入和模式更改的全局顺序
同步和异步复制
当发生故障时,数据库可能会出现不同的问题。例如,数据库Node 1可能不回复第二次插入insert into A values(2)的原因可能有两种:可能是节点无法接收和处理事务,或者数据已插入但 OK 回复未传回由于网络断开而导致的应用程序。
为了避免在断开连接后丢失第二个插入Node 1,应用程序必须重复事务insert into A values(2)到Node 2。
应用程序还必须以insert into A values(2)这样的方式进行重复尝试,即在相同的插入已被处理Node 1但 OK 回复未返回给应用程序的情况下,数据库不会创建重复的行。
为了实现这些目标,插入的所有数据都Node 1必须立即可读,Node 2以便应用程序在出现故障时执行重复数据删除。
或者,必须有另一种内置机制来删除数据库中插入的数据的重复数据。
由此得出结论,对于无间隙、无重复的写入故障转移,至少必须存在以下几点之一:
- 写入一个节点的数据可以立即通过所有其他副本进行选择,以便写入应用程序可以检查重复项
- 插入协议或表存储中内置了重复数据删除机制
上面的第一个要点也称为同步 (Sync) 复制,其中Node 1只有在插入数据已经复制到Node 2.之后才回复OK。
相比之下,异步(Async)复制允许Node 1在将插入的数据复制到Node 2.之前向应用程序回复OK。这样一来,如果此时宕机,Node 2.可能无法收到Node 1宕机前那次插入的数据,所以当Node1被启动或连接回来时,数据库将不得不重新尝试复制数据。
复制风味的选择#
回到我的自行车类比,在同步模式下配置为单一主数据库和只读副本的数据库类似于骑一辆自行车,同时试图让另一辆自行车一直跟在你身边。您可以想象,同时骑两辆自行车保持平衡是非常困难的,而且几乎不可能真正快速骑车!
另一方面,配置为单主数据库和只读异步副本的数据库类似于我购买一辆备用自行车,在工作时将其存储,并在自行车位于同一地点时同步我的行程数据。万一发生故障,我会丢失那次特定旅程的数据,但我仍然可以在同一天继续骑着备用自行车上下班。
我想多主复制就像和朋友一起骑两辆双人自行车,每个人都坐在第一个座位上。如果其中一个双人自行车坏了,骑手可以移到另一个双人自行车的后座上。多主同步复制是两个并排的串联,没有独立转动或停止的自由。异步复制将是独立的游乐设施,偶尔会追赶位置/行程数据。
异步复制是单车世界最合理的选择;我没有看到人们在街上同步骑自行车。它也是数据库世界中许多人的默认/唯一选择。同步复制可能很容易推理,并且可能看起来是整体上最好的解决方案,但它要付出高昂的性能代价,因为每个步骤都需要等到它在每个节点上完成。与直觉相反,即使同步复制使数据同时可供多个节点使用,它也会导致集群的可用性降低,因为它会显着降低事务率。
写入故障转移问题没有灵丹妙药,每个数据库都提供不同的复制风格供您选择。为了找到 QuestDB 的最佳选择,我们认真研究了其他时间序列数据库中的复制如何处理写故障转移,这里是一些结果。
TimescaleDB 数据库
每个人都喜欢经典的关系数据库,几乎每个开发人员都准备好回答有关 ACID 属性的面试问题,有时甚至是不同 RDMS 系统的事务隔离级别(以及每个系统可能出什么问题!)。使用 RDBMS 构建分布式读/写应用程序并不容易,但绝对可行。
PostgreSQL 是领先的开源 RDBMS 之一,许多人说它不仅仅是一个数据库。Postgres 也是一个可扩展的平台,例如,您可以在其中添加地理位置列类型、地理空间 SQL 查询语法和索引,从而有效地将其转变为 GIS 系统。同样,TimescaleDB 是一个 PostgreSQL 扩展,旨在优化时间序列工作负载的存储和查询性能。
开箱即用,TimescaleDB 从 Postgres 继承了它的复制功能。PostgreSQL 支持具有所有 ACID 和事务隔离属性的同步或异步复制的多个只读副本, Timescale 也是如此。
不幸的是,自动故障转移既不是 PostgreSQL 也不是 TimescaleDB 解决的,但是有像 Patroni这样的第 3 方解决方案增加了对该功能的支持。PostgreSQL 将故障转移过程描述 为 STONITH (Shoot The Other Node In The Head),这意味着一旦主节点开始出现异常,就必须将其击落。
运行同步复制可以解决故障切换后的数据缺口和重复问题。如果应用程序检测到故障切换,它可以将最后一个未确认的INSERT作为UPSERT重新运行。使用异步复制,在被提升为主节点的副本上可能会丢失一些最近的事务。这是因为旧的主节点必须被击落(STONISHed),而且没有简单的方法将丢失的数据从 "死亡 "节点转移到故障后的新主节点。
ClickHouse
ClickHouse 由俄罗斯搜索提供商 Yandex 开源开发多年。ClickHouse 在开源 (Apache 2.0) 中的功能非常全面,包括高可用性和水平扩展。还有很多支持 ClickHouse 的独立托管云产品:
在其开源产品的上下文中讨论 ClickHouse 的复制是有意义的,因为云功能可能因供应商而异。
ClickHouse开源的伟大之处在于,它支持多主机复制。
如果一个人创建一个有2个节点(节点1和节点2)的集群,并复制了表A(使用ReplicationMergeTree引擎):
当鲍勃向节点1发送了 |
这两条记录将被写入每个节点。当节点1收到INSERT INTO A VALUES(1)语句时,ClickHouse将其写到1_1部分。接下来,节点1将数据部分注册到Zookeeper(或ClickHouse Keeper)。Zookeeper通知每个节点关于新的部分,节点从源头下载数据并将其应用到本地表副本中。同样的过程同时发生在INSERT 2上。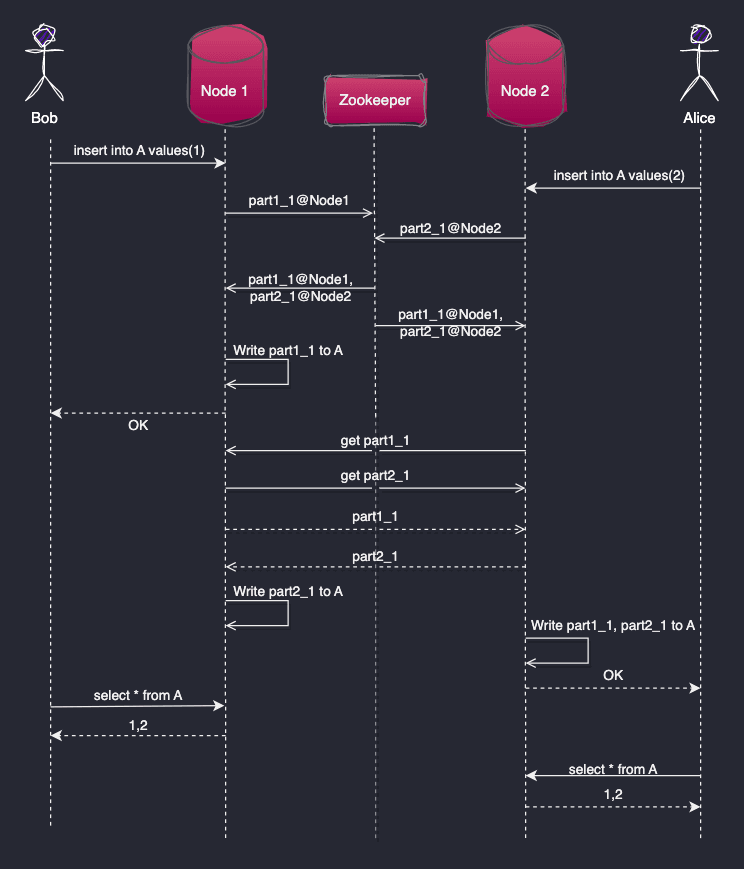
在这种架构中,插入可以并行写入每个节点。
那么读回数据呢?ClickHouse文档指出,复制过程是异步的,节点2可能需要一些时间来赶上节点1。然而,有一个选项,指定插入_quorum与每一个插入。如果insert_quorum设置为2,那么在节点1和节点2都插入数据后,应用程序会从数据库得到确认,有效地将其变成同步复制。还有一些设置需要考虑,比如insert_quorum_parallel、insert_quorum_timeout和select_sequential_consistency,以定义并发的并行插入如何工作。
也可以通过在复制的表上添加新的列来修改表的模式。一个ALTER TABLE语句可以被发送到集群中的任何一个节点,它将被复制到各个节点。ClickHouse不允许并发的表结构变化的执行,所以如果2个节点收到相同的不冲突的语句:
ALTER table A add column if not exists TIMESTAMP datatime64(6) |
其中一个节点可以回复故障:
副本上的元数据与Zookeeper中的通用元数据不是最新的。 |
在ClickHouse方言中,SQL更新语句也被写成ALTER TABLE,但幸运的是,它们可以并行执行而不会出现上述错误。
ClickHouse还有一个有用的方法来解决丢失的写入确认;在INSERT(或其他)查询确认因为网络断开或超时而丢失的情况下,客户端可以以完全相同的方式重新发送整个数据块到任何其他可用的节点。然后,接收节点计算数据的哈希代码,如果它能够识别出这个数据已经通过另一个节点应用过,就不会再应用它。
在ClickHouse中如何设置复制有更多的选择和味道,最流行的方法是ReplicatedMergeTree存储。
InfluxDB
InfluxDB 在撰写本文时拥有最高的 DB 引擎时间序列排名 ,尽管 InfluxData 在 2016 年将集群产品从开源版本中删除并 作为商业产品 InfluxDB Enterprise 出售,但我仍然认为它必须包含在这里。从那时起,他们的重点已经从企业版转移到近年来的云产品,他们在其中构建了 InfluxDB Cloud v2。虽然这是一个闭源系统,但其高级架构可以从 InfluxData 官方提供的营销图表中推导出来。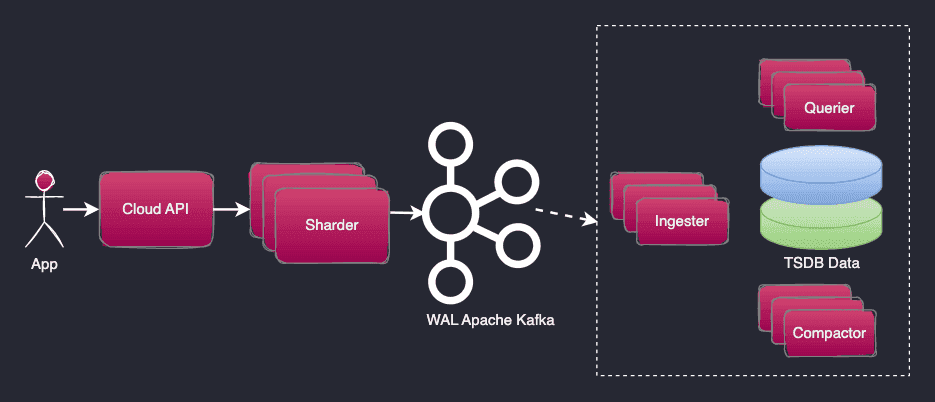
InfluxDB Cloud v2 将传入写入持久写入通过 Kafka 集群写入的预写日志 (WAL)。它是一个干净的解决方案,解决了 WAL 的持久性和分布,并确保当客户端收到写确认时数据已经被复制。
“可查询”表存储的 WAL 应用程序在 Ingester 组件中异步运行,使用来自 Kafka 的消息并将它们写入 2 个独立的 TSDB 副本。在读取确认写入的消息之间存在延迟,在 Influx 术语中,这称为 Time to Become Readable。
Influx 协议消息是幂等的,因为同一条消息可以被处理多次而不会产生重复。这是因为在 InfluxDB 中,同一组标签的每个时间戳值只能有一行。因此,如果发送一行:
measurement1 field=34.231562387656300000000
然后发送另一行具有相同的测量值和时间戳:
measurement1 new_fields=0.12341562387656300000000
新的字段值将被添加到同一行,就好像这些字段在同一条消息中一起发送一样:
measurement1 field=34.23,new_fields=0.12341562387656300000000
如果再次发送上述任何消息,Influx 将不会添加新行。这种方法解决了在超时或丢失回复时重新发送数据的问题。
因此,如果客户端没有收到来自 Influx 云的写入确认,它可以 一次又一次地重新发送相同的数据。当从不同连接发送具有相同时间戳和标记集的数据时:
measurement1 field1=1 1677851990000000000 |
查询存储节点可能会在一段时间内变得不一致,返回 3 行中的任何行:
1 2023-03-03T13:59:50.000Z |
甚至可以是第一个查询返回field1=1,第二个查询返回
field1=2,然后第三个查询尝试返回field1=1。最终,查询结果会变得稳定,并在每次运行时返回相同的数据。这是使用异步复制在 Round Robin 中查询节点的非常典型的结果。
Influx 数据模型还解决了动态演变模式的问题。由于没有传统的列(因为遇到的任何未知字段和标签都是由数据库引擎自动添加的),因此通过设计为相同的度量编写一组不同的字段是没有问题的。Influx 还检查模式冲突,如果有的话,将错误返回给写入应用程序。例如,如果同一字段作为数字发送,然后作为字符串发送:
m1 value=34.23 1562387656300000000 |
写入将失败,错误是列值是f64类型,但写入的是字符串类型,或者列值是字符串类型,但写入的是f64类型。
总结#
以下是与高可用性写入用例相关的时间序列数据库支持的复制功能的摘要:
PostgreSQL / TimescaleDB ClickHouse InfluxDB Cloud |
得出一些结论:
- 所有 3 个系统都通过写入预写日志并将其复制到节点之间进行复制。
- 异步复制,其中写入节点 1 的数据最终在节点 2 可见,是 InfluxDB Cloud 使用的最流行的方法,也是 ClickHouse 和 Postgres 中的默认方法。
- Postgres / Timescale 复制可以在同步和异步模式下使用,但它没有多主复制,也没有自动故障转移的选项。如果没有额外的软件系统或人工干预,就不可能解决写故障转移问题。
- ClickHouse 中提供了多主复制。也有足够的可用设置来在经历数据丢失(在极端情况下)和写入吞吐量之间取得适当的平衡。
- InfluxDB 在其开源产品中不提供复制支持。有一个闭源的云解决方案,利用 Kafka 来解决自动写入故障转移。Kafka 复制不是多主机,但借助自动故障转移,它解决了高可用性写入用例。
QuestDB 在 v7.0 中发布了 Write Ahead Log 表存储模式,作为我们复制之旅的第一步。它在内部使用多主写入架构,使并行连接对同一个表的非锁定写入成为可能。事务并行写入不同的 WAL 段,并且在 Sequencer 组件中维护全局提交顺序。最复杂的部分是自动模式冲突解决,以便表模式更改也可以并行执行。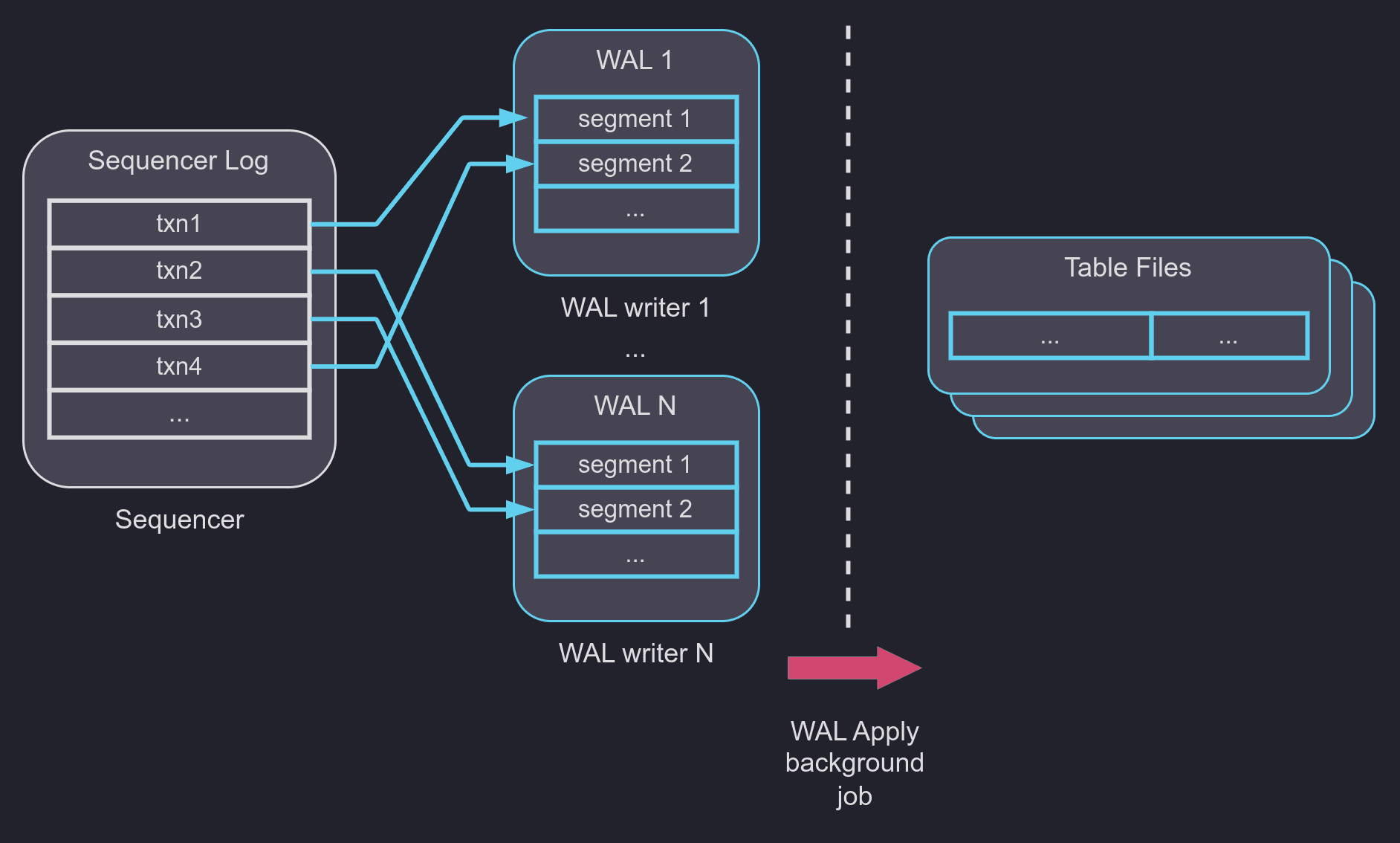
我们尽量避免长时间使用 Write Ahead Log,直接写入表存储。为了更清晰的复制路径和非锁定并行写入,接受 WAL 写入放大并不是一个容易的决定。最后,额外的写入操作不会影响整体吞吐量。相反,由于更好的并行性, 与我们自己的非 WAL 表的(非常出色的)性能相比, 我们在时间序列基准套件中实现了 3 倍的写入性能。
看看其他数据库如何解决复制问题,我们选择了实现具有异步一致性的多主复制的目标。我们相信这种方法在容错和交易吞吐量之间取得了最佳平衡。对于自动写入故障转移情况,必须具有内置的重复写入删除机制。QuestDB 下一步将把内置的 Sequencer 组件迁移到分布式环境,并解决多个实例之间的 WAL 共享。
和朋友一起骑双人自行车是我们看到的 QuestDB 最好的冗余解决方案。
我们非常欢迎在 GitHub 上为我们的项目做出开源贡献。