我们都喜欢建立绿地新项目。 但不可避免的是,开始一个新的项目需要与商业利益相关者进行大量的会议,以确定初始需求和典型的数据模型。这些都是......不那么有趣的。
当这些会议之一发生在高碳水化合物的午餐之后(米面等精致碳水导致胰岛素抵抗 容易发困,需要午睡),你的思想很容易飘走...
回到那些关于实体设计的大学讲座。想一想名词和它们有什么属性。狗和猫都是动物,有4条腿。除了现在是客户、订单、产品和购物车。
但这是建立一个系统的最佳方式吗?在我们现在重写的前一个绿地项目中,我们不是做了完全相同的事情吗?我们肯定不会犯和上次一样的错误......对吗?
购物车统统
随着会议的继续,购物车的设计初具规模。ShoppingCart是一个名词,毕竟,它有一个项目列表,每个项目都有简单的属性,比如Price和Quantity。这是实体关系图中的购物车部分,我们将打印出来并保存在我们的办公桌上就像软件设计经典中的一篇圣文:
我们还意识到购物车也有一些与之相关的行为,如AddToCart()、SaveForLater()和 等操作Checkout()。所以我们现在将数据和行为结合在一起……这本质上是一个聚合,这意味着我们现在正在进行领域驱动设计!
更多属性,更多问题
在开发过程中,我们开始看到计划中的一些缺陷。
首先,我们了解到,如果一个项目的价格下降,新的较低价格也应该反映在购物车中。因此,每当价格发生变化时,我们必须将该值复制到包含该物品的任何购物车中。然而,如果一个项目的价格上升,我们需要警告用户,并让他们接受新的价格。所以现在购物车中的物品需要存储当前的价格和之前的价格,每当任何相关数据发生变化时,我们都必须做大量的复制工作。
接下来,我们意识到,我们需要库存水平来准确反映仓库中的可用库存。企业打算用这个来给客户施加压力,让他们在没货之前购买。
为了使这个值保持最新,每次仓库中任何物品的库存发生变化时,我们都需要检查每个活动购物车中该物品的实例并更新其值。你也许可以通过连接表来获得这些信息,但这并不总是一种选择。例如,你可能需要对数据进行规范化处理以提高性能,或者仓库数据可能存在于一个物理上不同的系统中,无法参与数据库连接。
情况变得更糟。事实证明,我们发现围绕着交付估算、项目名称和描述的类似问题。因此,每当这些数值发生变化时,它们也需要从它们的真实来源复制到任何有匹配项目的购物车中。至少营销人员坚持认为,对产品名称和描述的修改应该是不频繁的,主要限于打字错误。让我们希望这是真的。
因此,现在我们的购物车开始变得更加混乱,而且我们开始担心我们需要编写所有的批处理作业来保持这个东西的更新。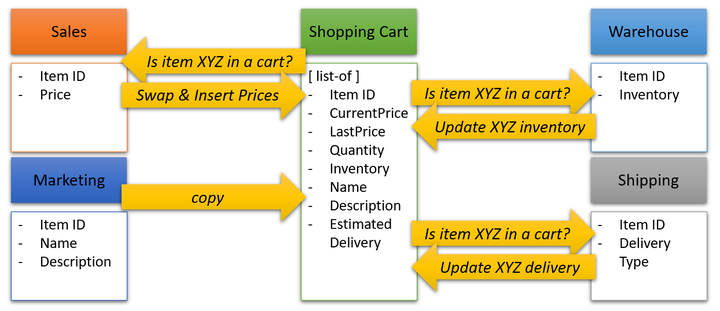
我们的 Cart 对象看起来不再像一个正确的 DDD 聚合,一切都依赖于其他一切,数据被复制到各处。
旧项目的似曾相识的沉没感开始蔓延。发生了什么事?而且,更重要的是,我们如何解决它?
反需求
为了帮助分解一个复杂的领域,我们可以使用反需求Anti-requirements来找到错误地混杂在同一个实体上的属性。使用反需求是一种强大的方式,通过将你的领域分解成可以独立发展的独立岛屿来增加自主性。
反需求是非常简单的:你创建一些关于两个属性的假需求,并把它提交给业务利益相关者。"如果产品的名称中有超过20个字符,"你对他们说,"那么它的价格必须至少是20美元。"
当他们嘲笑你的时候,这实际上暗示一个潜规则:虽然这两个属性在口头上与同一个名词有关,但它们之间并没有任何有意义的逻辑关系。
如果没有反需求,找出这些细节可能是很棘手的。
由于业务领域的专家倾向于认为“两个无关属性之间存在逻辑关系”是显而易见的,这使得他们不太可能主动提供这些信息。他们通常会对开发人员不知道这些信息感到惊讶。这使得我们作为开发者和架构师的工作就是去挖掘这些信息。
因此,考虑到这一点,让我们回到我们的购物车,问问自己:如果我问在属性A和属性B上可能操作的业务规则,业务人员会不会认为我已经知道?如果答案是肯定的,你可能已经找到了一个反要求。
全新改进的购物车
让我们开始梳理一些反需求,看看它对我们的购物车有什么影响,从价格的概念开始。
- 当产品价格超过 100 美元时,名称应改为全部大写。荒谬的!
- 当产品描述超过 3000 个字符时,价格应增加 10%。可笑!
- 当一件商品的库存高于 1000 件时,我们应该多收取 10% 的费用。不可思议!
但是等等,我们需要小心。当听到最后一个反需求时,我们的业务利益相关者可能会说,虽然这确实不可思议,但我们可能需要在库存较低时收取更多费用。毕竟,这只是供求关系的作用。
通过以这种方式使用反需求,您可能会意外地发现否则可能被忽略的业务需求(业务策略、业务规则)。
但是无论我们想出什么反需求,价格和数量是相关的这一点仍然很清楚。毕竟,您必须乘以price×quantity才能得到总成本。
这表明可以在其他地方提取高度耦合的价格和数量值。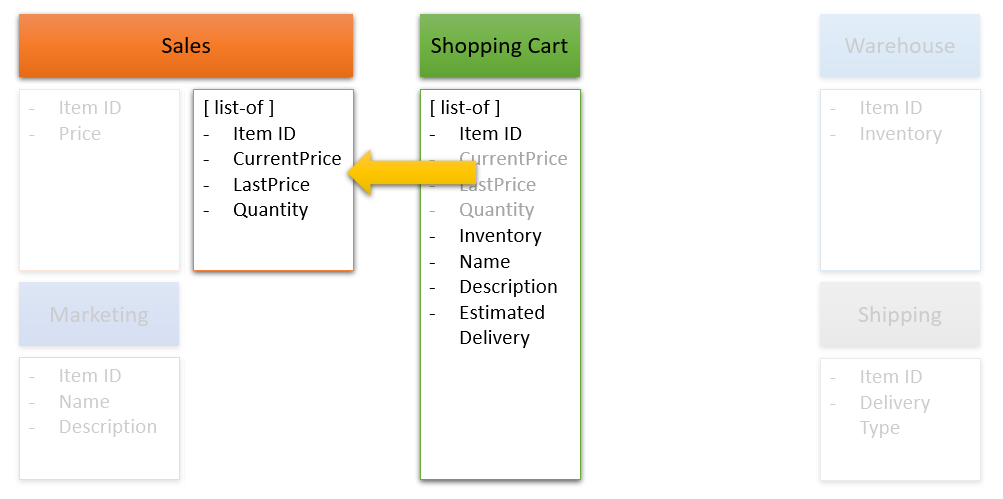
以同样的方式,我们可以开始分析其他属性对,为每个属性制定反需求,并根据它们听起来的荒谬程度来确定是否提取其他更紧密耦合的属性组。
- 产品名称会影响预计交货时间,因为我们按字母顺序运送产品。荒诞!
- 每次库存水平发生变化时,我们都必须更新商品的描述。荒谬!
- 我们拥有的商品库存越多,运送它们所需的时间就越长。怪诞!

还记得那个购物车实体吗?我们使用反需求作为俱乐部将其粉碎。事实证明,虽然购物车是企业使用的名词,但“购物车”已经不复存在了……只是一个简单的CartId而非成熟的实体或集合。
眼尖的读者会在这里注意到,数量Quantity不属于任何一个事物,而是在 Sales、Shipping 和 Warehouse 之间共享。重要的是要认识到,即使是单个属性也并不总是意味着同一件事。
在销售中,数量是价格的乘数。
在运输中,数量是在一个箱子里放入多少件物品……甚至多个箱子。
在仓库中,数量是要保留和补货的数量。
这些值恰好来自同一个地方,稍后我们将展示如何处理它。
这表明并非业务使用的所有名词都需要在您的领域模型中具有对应的实体。
提高效率
只有把一起变化的数据分组,在技术和组织上也有很多优势。
从技术角度来看,一起变化的属性也应该被类似地缓存起来。例如,一个产品的名称和描述并不经常变化,可以缓存很长时间,但价格和库存可能会经常变化。将它们存储在不同的实体中,可以让我们为每个实体使用最合适的缓存策略。在我们的案例中,将产品名称和描述存储在一个托管在内容交付网络(CDN)上的JSON文件中,可能是比使用关系型数据库更好、更可扩展的方法。
事实上,如果你根据https://mycdn.com/products/{ProductID}/{Size}.png这样的惯例在CDN上存储产品图片,那么你已经开始使用这些策略分解你的域名了。
从组织的角度来看,你不再需要同时召集所有的商业利益相关者。 如果你需要增加交付不需要运输的数字商品的能力,现在需要参与的人数大大减少,只需要对 "购物车 "的相关部分有洞察力的人。
对于我们的购物车来说,剩下的唯一问题就是把胖墩儿的所有碎片都拿出来,再把它们重新组合起来。
ViewModel 组合
任何事情都是有代价的,使用反要求进行分解也不例外。每个组件都获得了更大的自主权,但(一开始)可能会觉得这是以更大的复杂性为代价的。
我们的用户仍然认为 "购物车 "是一个东西,并希望看到我们在购物车页面上分离的所有属性。
我们可以使用一种叫做ViewModel组合的策略将所有的购物车属性整合在同一个页面上,使用像ServiceComposer这样的工具,由服务或微服务提供的独立组件可以从不同的后端系统中查询自己的数据,并将其整合到一个单一的ViewModel中,而不会在UI层重新引入耦合。
在ViewModel组合中,每个组件都注册了它对提供特定URI路由模式的数据的兴趣。然后,对于每个网络请求,所有感兴趣的数据提供者被要求获取他们的数据,这些数据被添加到动态ViewModel中。最后,一个单独的服务(让我们称之为品牌服务)获取ViewModel并将其渲染成HTML。
POST请求的情况也类似。组件为POST路由注册处理程序,以便与他们各自的后端系统进行通信,通常使用异步消息。这就是每个服务如何将数量值持久化到它自己的数据存储中,而不被其他组件所了解。
使用ViewModel组合确实增加了一些复杂性,至少在短期内是这样。它不会使构建第一个屏幕的速度加快,但会使构建第10个、第50个和第100个屏幕的速度加快。限制不必要的耦合,即使是在UI层,也会使我们更容易在未来继续创建新的功能。
视图模型组成技术也允许在数据存储技术方面的灵活性。例如,一个服务可以由一个传统的关系型数据库提供。同时,另一个服务可以使用图形数据库或键值存储,使用Redis的重缓存层,甚至是CDN上的JSON文件。
当一个服务只需要担心自己在整个系统中的垂直部分时,你会发现数据库图实际上可以舒适地放在一张纸上。
总结
在当今日益复杂的软件系统中,"名词有属性 "的建模方法势必会导致类、组件和系统成为一个混乱的耦合体。反要求是我们可以用来寻找逻辑服务边界的一种策略,它可以帮助我们发现哪些属性是属于一起的,哪些属性是没有必要互相靠近的。
随着时间的推移,过多的耦合会导致系统演变成一个大泥球。最终,在不破坏一些看似不相关的东西的情况下对任何地方进行修改都是不可能的。
那些解耦为自主服务的组织将能够更加灵活,并在未来几年为企业提供价值。毕竟,与大多数其他商业项目不同,软件并没有真正 "完成"。
其他人将在 3 年内重写系统。再次。