AI基准测试已经接近或超越人类
语音、图像、阅读、语言理解、小学数学、codegen --所有这些都接近或超过了人类的表现: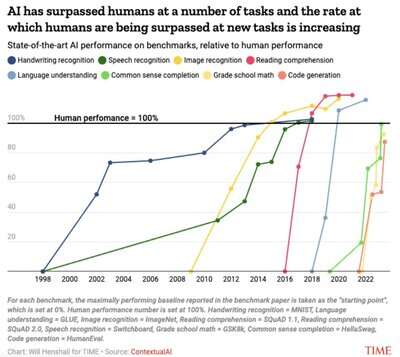
一个名为Dynabench 的平台,用于创建实时且不断发展的基准。并创建了一个图表来显示人工智能基准“饱和”的速度有多快,即最先进的系统在各种任务上开始超越人类的表现。
从那时起,重要的科学家和出版物就使用这个数字作为展示人工智能加速进步的快速方式,例如去年发表的这篇《科学》文章。
对于每个基准,我们将基准论文中报告的最高性能基准作为“起点”,我们将其设置为-1。人类表现数字设置为 0。总之,对于每个结果 X,我们将其缩放为 (X-人类)/Abs(起始点-人类)。Paperswithcode使查找结果变得更加容易。
Dynabench 本身现在由 MLCommons(Meta于 2022 年转让所有权)所有,这是一个开放工程联盟,其使命是通过加速人工智能创新来造福社会。
该平台很强大:除了最初的任务之外,它还举办了诸如Flores、DataPerf和BabyLM等挑战。
该平台引入的动态对抗性数据集还远未得到解决,更重要的是,Dynabench、Dynaboard 和GEM首创的对抗性和整体基准测试哲学现在正变得更加主流。
评估从来都不是一个容易的话题。最近的一个例子是,语言模型在报告相同内容的不同排行榜上的排名存在巨大差异。简单评估指标的微小变化可能会导致截然不同的结果。没有商定的标准化框架,我们只能使用语言模型来评估其他语言模型。创新型公司希望在这里做得更好,比如Patronus。
在 Contextual AI,我们正在积极为那些希望将 LLM 驱动的产品大规模推向客户的企业解决关键限制,包括归因、幻觉、数据僵化和隐私。在经过静态测试集、动态基准测试、红队测试、ELO 评级和发展心理学工具之后,在正确评估 LLM 方面仍有许多工作要做,尤其是在关键设置方面。
幻觉、归因和陈旧性等重要问题将在不远的将来得到解决。隐私将得到改善,成本也将降低。这是一个令人兴奋的时代。谁知道几年后我们的地块会变成什么样呢?