如果您从事数据领域,您可能听说过开放表格式,例如 Apache Iceberg、Apache Hudi 或 Delta Lake。
开放表格式是数据存储的包装器,并使用一系列文件来
- 跟踪表上的架构/分区 (DDL) 更改。
- 跟踪表的数据文件及其列统计信息。
- 跟踪表上的所有插入/更新/删除 (DML)。
我们将使用 Apache Iceberg 来说明使用 OTF 的好处。虽然实现上存在差异和细微差别,但以下部分也适用于 Apache Hudi 和 Delta 格式。
建议按照代码进行操作!请按照此 GitHub 存储库中的设置部分 创建数据并将其插入订单表中。
Apache Iceberg 可以与多种数据处理系统配合使用;spark-sql我们在示例中使用。
无需重新处理即可演化数据和分区架构
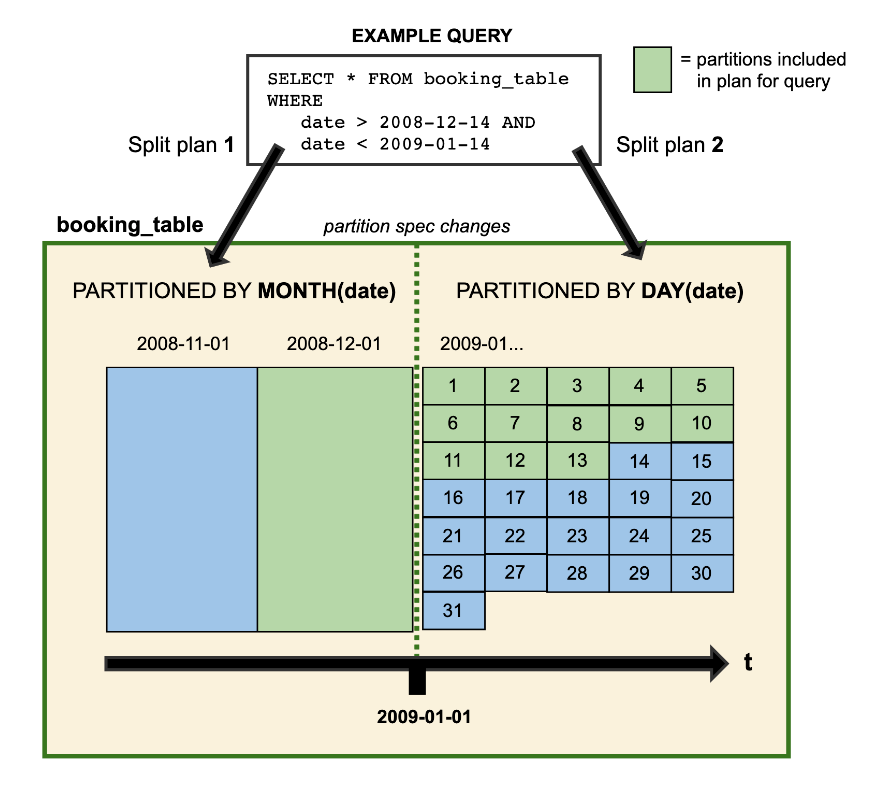
Apache Iceberg 使您能够更改表的数据模式或分区模式,而无需重新处理现有数据。元数据文件跟踪架构和分区更改,允许系统使用相应历史数据的适当数据/分区架构来处理数据。
模式schema和分区演化是分析表中的常见操作,对于传统的 OLAP 系统来说通常成本高昂或容易出错。Apache Iceberg 使数据和分区模式演变成为一项简单的任务。
-- schema evolution
ALTER TABLE local.warehouse.orders ALTER COLUMN cust_id TYPE bigint;
ALTER TABLE local.warehouse.orders DROP COLUMN order_status;
-- parititon evolution
ALTER TABLE local.warehouse.orders ADD PARTITION FIELD cust_id;
INSERT INTO local.warehouse.orders VALUES
('e481f51cbdc54678b7cc49136f2d6af7',69,CAST('2023-11-14 09:56:33' AS TIMESTAMP)),
('e481f51cbdc54678b7cc49136f2d6af7',87,CAST('2023-11-14 10:56:33' AS TIMESTAMP));
-- check snapshots
select committed_at, snapshot_id, manifest_list from local.warehouse.orders.snapshots order by committed_at desc;
-- We will have two since we had two insert statements
-- See the partitions column statistics and data files added per snapshot
select added_snapshot_id, added_data_files_count, partition_summaries from local.warehouse.orders.manifests;
|
上面的代码显示表上的每个操作(插入/删除/更新集)都将被视为快照。我们还可以通过表的清单查看分区架构、列统计信息以及每个快照添加或删除的文件数。
我们还可以打开该文件./data/iceberg-warehouse/warehouse/orders/metadata/v.metadata.json(在项目目录中)以分别查看“schema”和“partition-specs”部分下的不同数据和分区模式。
系统如何处理分区已演变的数据的直观表示:
隐藏分区允许您根据列转换定义(并启用使用)分区。例如,您可能希望按时间戳列上的日期进行分区。在 HIVE(没有 OTF)中,您必须在数据中创建一个单独的日期列。但是,使用 Apache Iceberg,您可以在另一列的转换上定义分区,如下所示:
/* -- created in the setup section
CREATE TABLE local.warehouse.orders (
order_id string,
cust_id INT,
order_status string,
order_date timestamp
) USING iceberg
PARTITIONED BY (date(order_date));
*/
-- The below query automatically uses the partition to prune data files to scan.
SELECT cust_id, order_date FROM local.warehouse.orders WHERE order_date BETWEEN '2023-11-01 12:45:33' AND '2023-11-03 12:45:33';
|
查看之前的时间点表状态,也称为时间旅行
由于元数据文件跟踪数据(以及数据/分区架构)的所有更改,因此我们可以返回到时间点表状态(也称为时间旅行)。例如,如果您想查看四天前的表是什么样子,您可以使用时间旅行来实现。
-- get the time of the first data snapshot
select min(committed_at) as min_committed_at from local.warehouse.orders.snapshots;
-- e.g. 2023-11-21 12:03:08.833
-- Query data as of the oldest committed_at (min_committed_at from the above query) time or after
SELECT * FROM local.warehouse.orders TIMESTAMP AS OF '2023-11-21 12:03:08.833';
-- 15 rows
-- Query without time travel, and you will see all the rows
SELECT * FROM local.warehouse.orders;
-- 17 rows
|
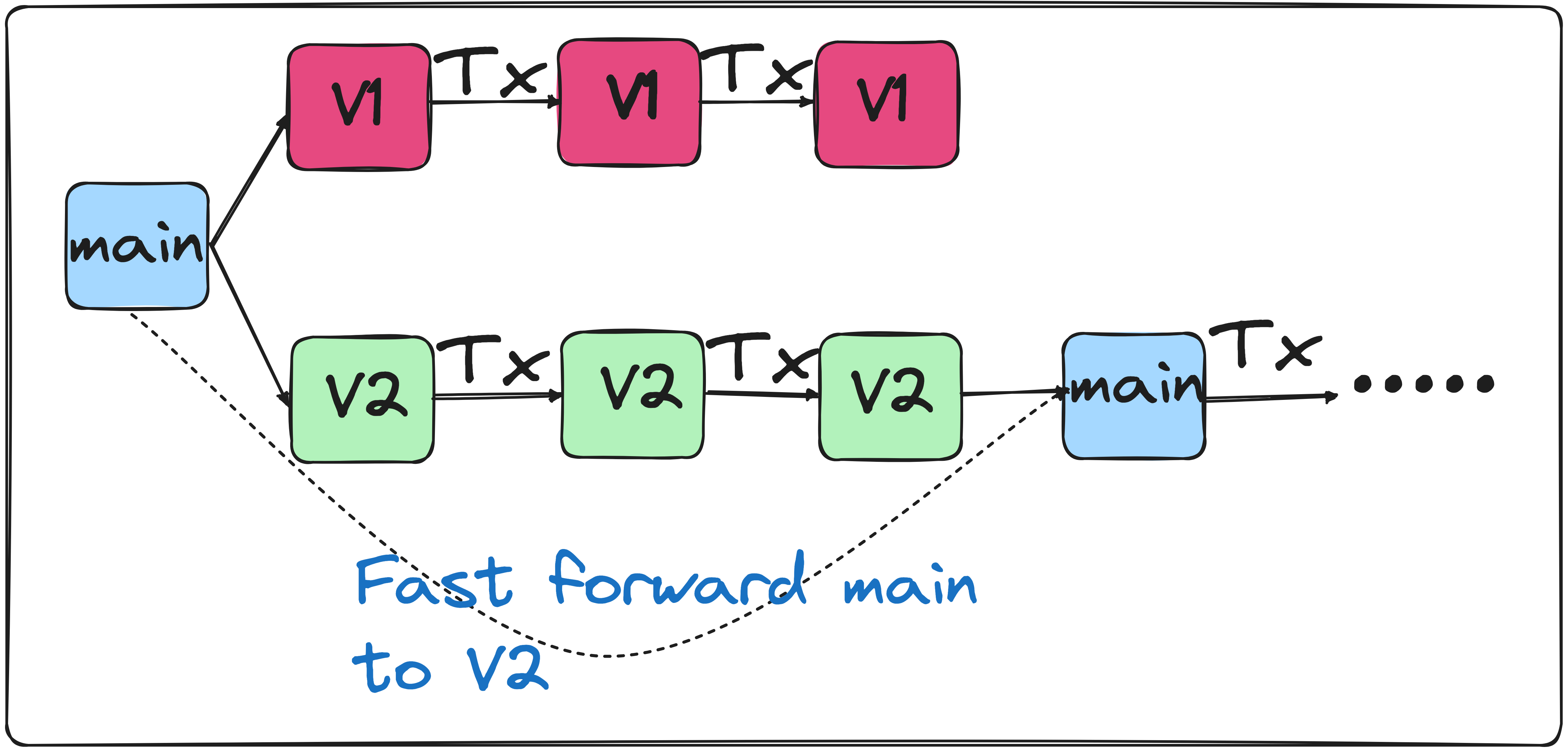
类似于 Git 的表分支和标签
Apache Iceberg 通过管理每个分支的独立元数据文件来实现表的分支。例如,假设您必须在生产中运行管道一周才能验证您所做的更改是否有效。您可以使用分支来执行此操作,如下所示:
DROP TABLE IF EXISTS local.warehouse.orders_agg;
CREATE TABLE local.warehouse.orders_agg(
order_date date,
num_orders int
) USING iceberg;
INSERT INTO local.warehouse.orders_agg
SELECT date(order_date) as order_date, count(order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-02' GROUP BY 1;
-- Create two branches that are both stored for ten days
ALTER TABLE local.warehouse.orders_agg CREATE BRANCH <code>branch-v1</code> RETAIN 10 DAYS;
ALTER TABLE local.warehouse.orders_agg CREATE BRANCH <code>branch-v2</code> RETAIN 10 DAYS;
-- Use different logic for each of the branches
-- inserting into branch v1
INSERT INTO local.warehouse.orders_agg.<code>branch_branch-v1</code>
SELECT date(order_date) as order_date, count(order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-03' GROUP BY 1;
INSERT INTO local.warehouse.orders_agg.<code>branch_branch-v1</code>
SELECT date(order_date) as order_date, count(order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-04' GROUP BY 1;
-- inserting into branch v2
INSERT INTO local.warehouse.orders_agg.<code>branch_branch-v2</code>
SELECT date(order_date) as order_date, count(distinct order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-03' GROUP BY 1;
INSERT INTO local.warehouse.orders_agg.<code>branch_branch-v2</code>
SELECT date(order_date) as order_date, count(distinct order_id) as num_orders from local.warehouse.orders WHERE date(order_date) = '2023-11-04' GROUP BY 1;
-- validate data, the v2 logic is correct
select * from local.warehouse.orders_agg.<code>branch_branch-v1</code> order by order_date;
select * from local.warehouse.orders_agg.<code>branch_branch-v2</code> order by order_date;
|
从上面的练习中,我们注意到branch-v2具有正确的逻辑,因此我们将主分支快进到branch-v2。主分支现在将拥有过去两天的准确数据。
select * from local.warehouse.orders_agg order by order_date desc;
-- Push the main branch to branch v2's state
CALL local.system.fast_forward('warehouse.orders_agg', 'main', 'branch-v2');
select * from local.warehouse.orders_agg order by order_date desc;
|
同时处理多个读取和写入
在传统的OLAP系统(例如HIVE)中,如果多个进程在没有适当保护的情况下读/写同一个表,则可能会出现数据读取不一致,或者数据可能在写入过程中被覆盖。Apache Iceberg 以原子方式更新其元数据,这迫使编写器一次“提交”一个更改(如果多个编写器发生冲突,则会对失败的编写器进行重试 )。
读取数据时,Apache Iceberg 使用最新的快照(使用元数据文件)来确保进程内数据操作不会影响读取。
由于Apache Icerber是OSS,我们可以使用任何实现表格式的系统来读写。
例如,我们可以使用 DuckDB 来读取我们的数据。使用 退出 Spark shell,使用exit;docker退出exit。duckdb通过终端使用命令启动 DuckDB CLI 。
INSTALL iceberg;
LOAD iceberg;
-- Count orders by date
WITH orders as (SELECT * FROM iceberg_scan('data/iceberg-warehouse/warehouse/orders', ALLOW_MOVED_PATHS=true))
select strftime(order_date, '%Y-%m-%d') as order_date
, count(distinct order_id) as num_orders
from orders
group by strftime(order_date, '%Y-%m-%d')
order by 1 desc;
|
总结
下次使用 OTF 时,请记住它是一个元数据文件系统,存储对数据的每次更改以及有关数据文件的统计信息。OTF 可以显着改善您管理分析表的方式和开发人员体验。