Marker 将 PDF、EPUB 和 MOBI 转换为 Markdown。它比 nougat 快 10 倍,比 arXiv 更准确,而且幻觉风险很低。 Marker 针对吞吐量进行了优化,比如转换 LLM 预训练数据。在大多数文档上更准确,并且产生幻觉的风险较低。
- 支持一系列 PDF 文档(针对书籍和科学论文进行了优化)
- 删除页眉/页脚/其他工件
- 将大多数方程转换为乳胶
- 设置代码块和表格的格式
- 支持多种语言(尽管大多数测试是用英语完成的)。请参阅settings.py参考资料 获取语言列表。
- 适用于 GPU、CPU 或 MPS
Marker 是深度学习模型的管道:
- 提取文本,必要时进行 OCR(启发式、超正方体)
- 检测页面布局(布局分段器、列检测器)
- 清理并格式化每个块(启发式,牛轧糖)
- 组合块和后处理完整文本(启发式,pdf_postprocessor)
Nougat 是一个了不起的模型,但由于自回归解码的原因,速度很慢,而且容易产生幻觉(arXiv 中的页面占 1.5%,外部占 5%以上)。 Marker 可以逐步转换和清理文本。 它使用 4 个模型--列检测器、布局检测器、牛轧糖、后处理器。 如有需要,它还会进行 OCR。
但我想要一个更快、更通用的解决方案。Marker 速度快 10 倍,并且幻觉风险低,因为它仅通过 LLM 前向传递传递方程块。
为了进行基准测试,我找到了一些有并行 latex 和 pdf 版本的文档,然后将 latex 转换为 markdown。 其中一半来自 arXiv,一半是教科书。 我将参考文献与转换后的版本进行比较,并计算出 0-100 的对齐度/准确度得分。
Marker 的单页速度是 nougat 的 10 倍,而且在 arXiv 之外更为准确(think* 为非 arXiv 图书,其余为 arXiv 图书)。 在此基准测试中,两者都使用了最大 3GB 的 VRAM(在 A6000 上运行)。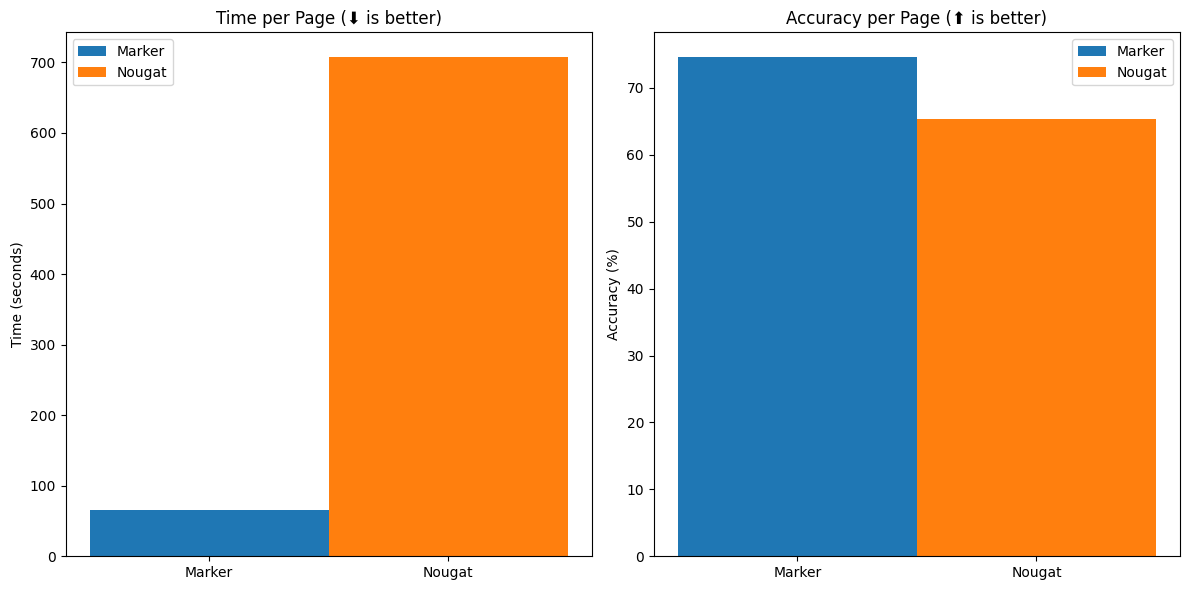
Marker 很容易并行化,吞吐量与并行工作者基本成线性关系。 甚至还有一个脚本可以在多个 GPU 上运行转换。 您还可以调整批量大小,以加快处理每个 PDF 的速度,但代价是需要使用更多的 VRAM。
PDF 是一种棘手的格式:只是带有位置的文本块。 没有关于如何将文字连接在一起的信息。
挑战在于
- - 在多栏布局中对文本进行排序
- - 了解提取的文本是否损坏
- - 处理不同类型的块(缩进代码等)
我尝试了很多方法来查找文本块的顺序,甚至训练了一个模型来直接预测顺序(输入边界框,输出顺序)。 这是基于 layoutreader但这并不准确,而且可能导致重复。
然后,我自己给一个数据集贴了标签(有点喧宾夺主地给整个 pdf 都贴了相同的标签),并训练了一个模型来检测列数。 然后找到垂直的分栏,并对栏内的块进行排序。
列检测器在这里
我使用启发式方法(如拼写错误率)来确定是否需要使用 tesseract 进行 OCR。 Ocrmypdf 比单独使用 tesseract 更准确,因为它会先对页面进行转换。 对所有文本进行 OCR 的准确性低于提取文本,因为 OCR 会引入错误。
提取文本并排序后,我使用布局分割器来检测块类型(文本、公式、表格等)。 我使用 IBM 的 DocLayNet 数据集对 layoutlmv3进行了微调 ,最终模型在这
用nougat将方程转换为 Latex。 通过只在方程上运行 nougat,幻觉表面积大大减少。 我希望能对 nougat 进行微调,使其能在更小的区域内运行(虽然 nougat 做得很好)。
启发式方法适用于清理和连接数据块。 表格、代码、方程式等则以不同方式处理。 最难的部分是缩进块--我需要为此重新训练布局检测器。 这样我们就完成了大部分工作,但启发式方法无法处理所有边缘情况。
我训练了一个后处理器模型,它可以接收几乎是最终文本的内容,并通过删除人工痕迹、添加空格等方式对其进行定稿。 该模型是一个标记分类器,用于检测每个输入标记前面是否需要空格、是否需要删除等。
对于训练数据,我们需要清理文本,将清理后的文本与原始文本对齐,然后将两者与 LLM 的标记对齐。 一个问题是,大多数标记化器在某种程度上都具有破坏性--它们会删除空白、用 unk 替换某些字符等。
我试过 bloom,它的词汇量很大,而且不会像 mdeberta 和其他软件那样删除空白。 但 bloom 将一些 unicode 字符编码为未知字符,因此不适合使用。 (尽管我非常希望它能工作!)。 基于 bloom 的后处理器在这里
我使用了将 unicode 字符标记化为字节的 byt5。 这种方法效率较低,但可以编码任何 utf-8 字符。 一个字符可以是多个令牌(一个令牌 = 一个字节),因此我重新组合令牌并处理每个字符。模型这里
后处理器是一个需要改进的地方。 我需要对原始序列和清理后序列的对齐方式进行清理,并收集更多的训练数据。
Marker 有其局限性,包括
- 它只支持与英语类似的语言。 由于使用了 nougat 和 layoutlm 许可,它是非商业性的。
如果没有一些了不起的开源工作,Marker 将无法实现,这些开源工作包括但不限于:
- - LayoutLMv3 from Microsoft
- - Nougat by Meta
- - DocLayNet from IBM
- - ByT5
- - OCRmyPDF + tesseract
- - PyMuPDF
我认为构建整个管道/应用程序是开源人工智能的一大机遇。 管道可能比单一模型更有效,但对一个模型进行微调要比将多个模型串联起来更常见。
我在 4 台 A6000 上训练/微调了所有模型。 我很想知道,在 GPU 资源相对有限的情况下,我能取得多大的进展!
总之,希望这篇文章对你有用! 如果你真的尝试了标记,请告诉我你的效果如何。 我已经在多种 PDF 文件中尝试过,但有很多边缘情况。