本文旨在讨论使用 Java 的搜索自动完成的低级实现,将Trie在用例中使用数据结构。
这是一个示例TrieNode类:
class TrieNode{
Map<Character,TrieNode> children;
boolean isEndOfWord;
TrieNode(){
children = new HashMap<>();
isEndOfWord = false;
}
}
|
请注意,我们在这里使用 Map 来存储 Trie 中特定层级的所有字符。
如果问题是按字母顺序返回结果,那么我们别无选择,只能使用 TreeMap,能确保顺序,但会在插入和搜索时耗费时间,因为 TreeMap 查找/插入将耗费 log(n) 时间。
在本文中,我们假设可以按任意顺序返回结果,以使事情变得简单。
另外,假设我们有来自后台的缓存响应。我们可以将其作为自动完成任务的单词来源。让这个输入是单词,假设我们正在搜索一个单词 searchWord 。因此,方法定义可归结为以下内容:
public List<String> suggestedWords(String[] words,
String searchWord) {
for (String word: words) {
insert(word); // insert to Trie
}
return search(searchWord); // search in Trie and return results
}
|
方法 insert(String word) 可以在 Trie 中插入单词。
以下是该方法的示例实现。
请注意,我们需要将最后一个 TrieNode 的 isEndOfWord 标志设置为 true,表示单词的最后一个字符。
private void insert(String word) {
int len = word.length();
TrieNode current = this.root; // member variable pointing to the root of TrieNode
for (int i = 0; i < len; i++) {
TrieNode node = current.children.get(word.charAt(i));
if (node == null) {
node = new TrieNode();
current.children.put(word.charAt(i), node);
}
current = node;
}
current.isEndOfWord = true;
}
|
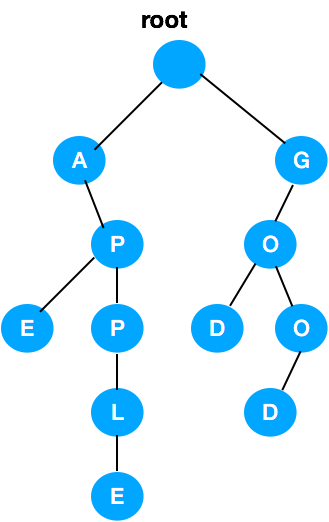
Trie 可以预先填充,也可以在应用服务器中设置。
因此,实时查询只需直接调用 search(searchWord)。在插入一堆单词后,它看起来就像下面这样(例如:apple, ape, god, good):
现在到了主要部分,即搜索自动完成。
首先,我们需要实现前缀搜索。
我们应该能够在 Trie 中搜索前缀。如果找到匹配,我们就需要搜索该特定 TrieNode 中的完整单词。实时应用将返回 k 个结果,而不是所有单词。
为了实现实时性能,返回 k 个单词是合理的。以下是前缀搜索的实现:
private TrieNode startsWith(String prefix) {
int len = prefix.length();
TrieNode current = this.root;
for (int i = 0; i < len; i++) {
TrieNode node = current.children.get(prefix.charAt(i));
if (node == null) {
return null;
}
current = node;
}
return current;
}
|
如果在 Trie 中没有找到前缀,我们将返回 null,否则我们将返回 TrieNode 作为主要搜索的起点。在最坏的情况下,前缀搜索只需要 O(n) 时间。下面,让我用迄今为止定义的所有方法重写搜索函数:
private List<String> search(String searchWord) {
List<String> result = new ArrayList <> ();
TrieNode current = this.root;
int len = searchWord.length();
current = startsWith(searchWord);
if (current != null) {
List<String> list = new ArrayList <> ();
StringBuilder sb = new StringBuilder(searchWord);
// backtrack(list, current, sb, k); yet to implement.
result.addAll(list);
}
return result;
}
|
请注意,searchWord 可能是一个完整的词,也可能不是。但这并不重要,我们会返回 searchWord 的所有完整单词。我已经对上述代码进行了注释,这些代码还有待讨论/实现。我们可以使用回溯法从前缀 TrieNode 开始遍历所有后续 TrieNode,直到找到一个完整的单词。请参考下面的实现:
private void backtrack(List<String> list,
TrieNode current,
StringBuilder sb,
int k) {
if (list.size() == k) {
return;
}
if (current.isEndOfWord) {
list.add(sb.toString());
}
for (Map.Entry<Character,TrieNode> entry: current.children.entrySet()) {
sb.append(entry.getKey());
backtrack(list, entry.getValue(), sb);
sb.setLength(sb.length() - 1);
}
}
|
当最多收集到 k 个单词时,我们就停止回溯 Trie。最重要的是,我们会借助 isEndOfWord 标志来收集单词。StringBuilder 的使用在此不言自明。一旦完成回溯,结果将包含所有完整的单词。现在,如果我们需要返回短语列表而不是单词列表,也可以采用同样的解决方案。这里的单词是短语的同义词,所以并不重要。
您可以在实际的编码面试中快速完成编码,改进的空间是无限的!编码快乐