大数据专题
Flickr使用Hadoop和Storm扩展计算机视觉处理能力
Flickr在2013年时每年有5亿张图片上传,估计到2014年底数字翻番。如何帮助用户组织 搜索和浏览这么大的一个图片集呢?
首先,通过对图片进行标签分类,Flickr依靠计算机自动为这些图片贴上标签,任何上传的图片都会使用计算机视觉软件进行分类然后贴上标签。对图片能标签花 鸟 建筑 教堂 户外等分类。
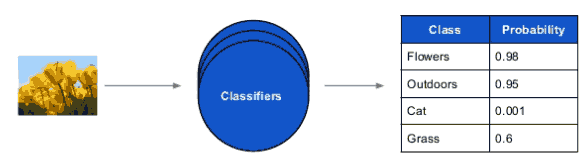
Flickr目标是:训练数千个分类器classifier,每天分类数百万的图片,然后计算自动标签,每半周激活一次自动预处理,能够在90天内全部做完。 上图中分类器能够判别这张上传图片0.98接近花,还有0.95接近标签分类:户外,Cat猫只有0.001可能性。
分类器classifier
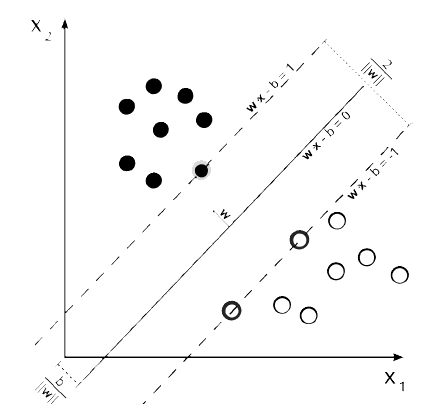
什么是一个分类器?分类器其实是一行算式:
z = wx - b
这是一个切分正数和负数的公式,训练就是在一个很大边界内调整w和b,以便取样出正和负。在给出某个大范围内划分出正负。
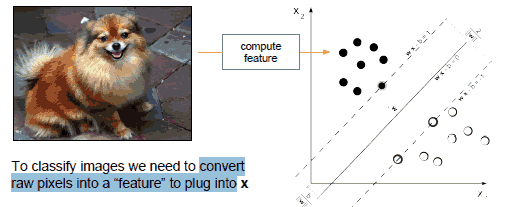
为了对图片分类,需要将原始像素转为特征feature,然后插入x中:
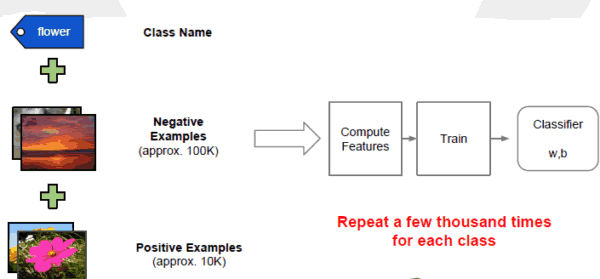
具体分类和培训过程如下:
使用Hadoop进行批处理
数据有两种Pixel data像数数据和Label Data标签数据,存中储在HDFS如下:

通过Hadoop进行归类,mappers发射 (photo_id, pixels)或 (photo_id, class, label)数据,而reducers利用排序产生 (photo_id, pixels, json(label data)),其中最后产生如:
1 <pixelsb64> [(cat, FALSE), (dog, TRUE)]
2 <pixelsb64> [(cat,TRUE), (dog, FALSE)]
3 <pixelsb64> [(cat, FALSE), (dog, TRUE)]
使用Hadoop进行分类计算:

通过Mapper进行特征计算分类,产生(class, feat64, label),每个图片都有一个分类,然后通过reducer利用排序训练,产生(class, w, b)。
使用Storm进行流处理
使用Storm进行自动分类标签的架构

编制一个Topology:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("images", new ImageSpout(), 10);
builder.setBolt("autotag", new AutoTagBolt(), 3) .shuffleGrouping("images") builder.setBolt("dbwriter", new DBWriterBolt(), 2) .shuffleGrouping("autotag")
定义一个Bolt:
class Autotag(storm.BasicBolt):
def __init__(self):
self.classifier.load()
def process(self, tuple):
<process tuple here>
Storm是一个大型查询框架,用于进行可伸缩扩展,可以原子性启动 杀死 或失效,无单点风险。