大数据主题
Hadoop大数据批处理教程之HDFS
什么是HDFS?
•在一个多节点块集群存储文件。
•在节点间复制模块
•主从架构。
• 没有文件更新
• 一次写,多次读
• 大数据块 顺序读模式
• 为批处理设计
HDFS主服务器特点:
NameNode
- 运行在单个节点服务器上作为主处理器
? 存有文件的元数据(哪个数据块在哪里)
? 直接访问文件的客户端
• SecondaryNameNode
- 不是一个热点容错
- 维持NameNode的元数据拷贝
HDFS从服务器特点:
DataNode
- 一般运行在集群中所有节点
? 堵塞 creation/replication/deletion/reads
? 从NameNode获取等级次序
HDFS的文件存储原理
假设一个文件如图由红绿蓝三个数据块组成,现在将演示如何写入到HDFS系统中:
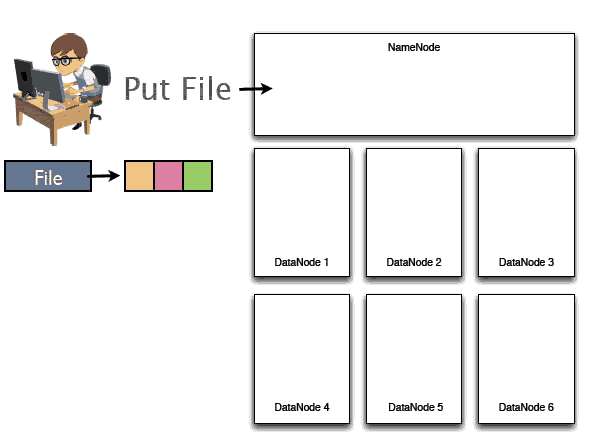
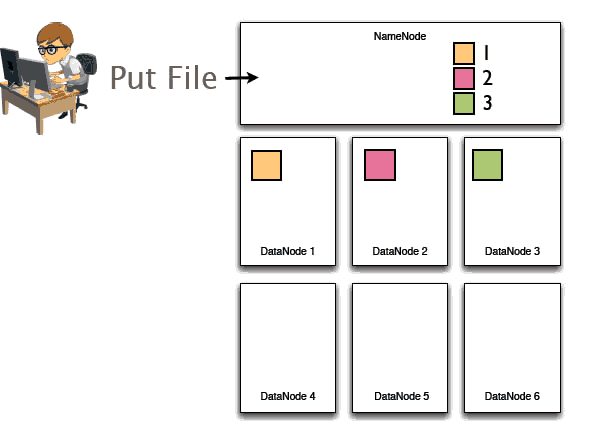
这三块首先在namenode中登记元数据,哪个数据块在哪个服务器上:黄色在1号节点,红色的2号节点 绿色在3号节点。
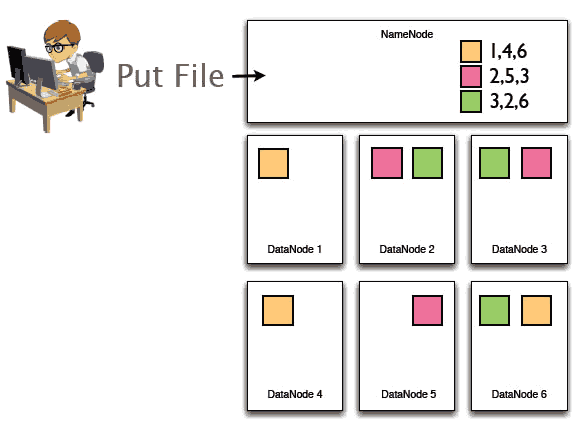
然后HDFS在节点之间复制这些数据块,最后这三块在多个节点中分布如下:
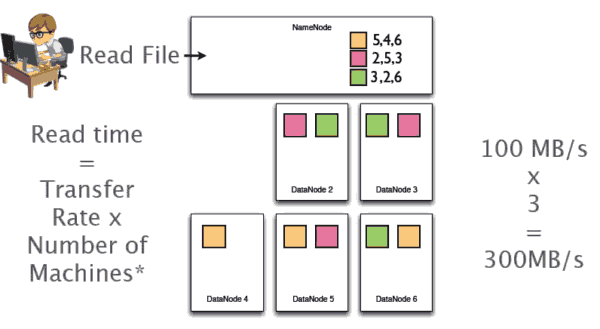
写文件完成后,当我们开始读文件时,读文件由于是并行读取,因此读取时间会提高三倍,如下图:
通过HDFS命令行:
•创建 复制 移动 和删除文件.
•实现管理职责 - chmod, chown, chgrp.
• 设置复制文件的比率
• 使用Head, tail, cat查看文件
下页
Hadoop专题
Storm大数据实时处理
NoSQL
Spark - 大数据Big Data处理框架
大数据专题