分布式共识一致性教程
-
基于Postgres逻辑复制的推送式发件箱模式
1825 1 10K
只有几个模式让我觉得很舒服:“如果你想构建成熟的系统,你应该一直使用它”。其中之一是发件箱模式。为什么?因为它保证了你的业务流程和沟通不会卡在中间。正如我在发件箱中解释的,收件箱模式和交付保证解释了:.
-
async-raft:使用 Tokio 框架实现 Raft 分布式共识协议
1395
速度极快的 Rust、现代共识协议和可靠的异步运行时——该项目旨在为下一代分布式数据存储系统(SQL、NoSQL、KV、流式传输、图形......或者更奇特的东西)提供共识主干)。这个 crate 与.
-
分布式系统中的数据复制
1551 1 2K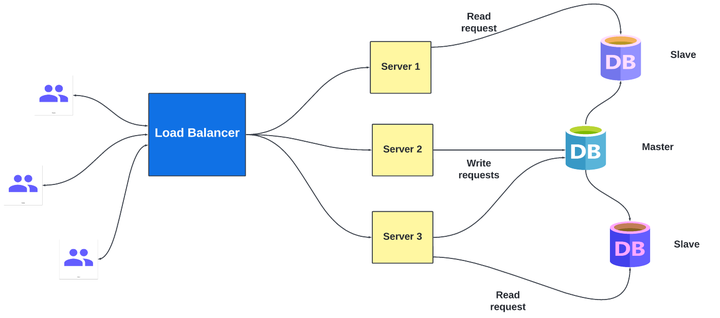 数据复制是制作数据项的多个副本以确保可用性的过程。复制的数据通常存储在不同的数据库实例中,因此即使一个实例发生故障,我们也可以从其他实例中获取数据。实现数据复制的一种流行架构是主从架构。主从架构为了理.
数据复制是制作数据项的多个副本以确保可用性的过程。复制的数据通常存储在不同的数据库实例中,因此即使一个实例发生故障,我们也可以从其他实例中获取数据。实现数据复制的一种流行架构是主从架构。主从架构为了理. -
分布式系统的仲裁模式
1587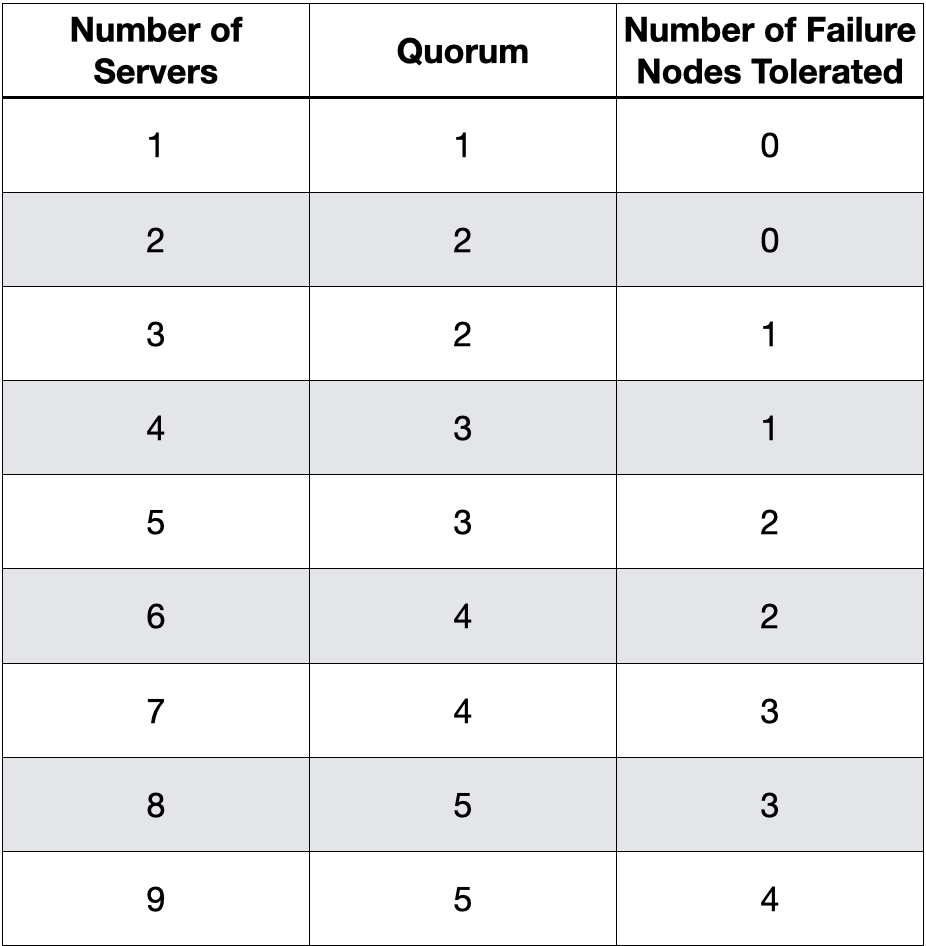 任何分布式系统的常量之一是失败。我们构建的系统能够抵御故障。假设我们想要复制到集群中的不同节点以实现高可用性和容错。我们需要问的下一个问题是——我们集群中有多少节点需要确认他们从原始服务器获得了复制副.
任何分布式系统的常量之一是失败。我们构建的系统能够抵御故障。假设我们想要复制到集群中的不同节点以实现高可用性和容错。我们需要问的下一个问题是——我们集群中有多少节点需要确认他们从原始服务器获得了复制副. -
分布式系统中的内存限速器 - ajin
1025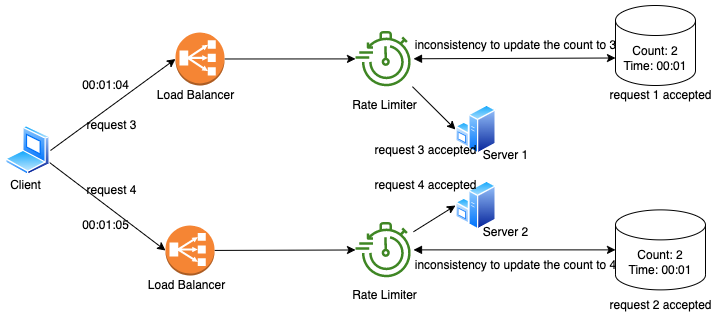 在多台服务器分布在世界各地不同地区的情况下,为每台服务器实施速率限制器将导致两个主要问题: 不一致 竞争条件 在本文中,我们将探讨这两个主要问题,以及我们如何实施更好的策略来解决分布式系统的这些问题。.
在多台服务器分布在世界各地不同地区的情况下,为每台服务器实施速率限制器将导致两个主要问题: 不一致 竞争条件 在本文中,我们将探讨这两个主要问题,以及我们如何实施更好的策略来解决分布式系统的这些问题。. -
19种分布式系统设计模式 - Nishant
2125 2 6K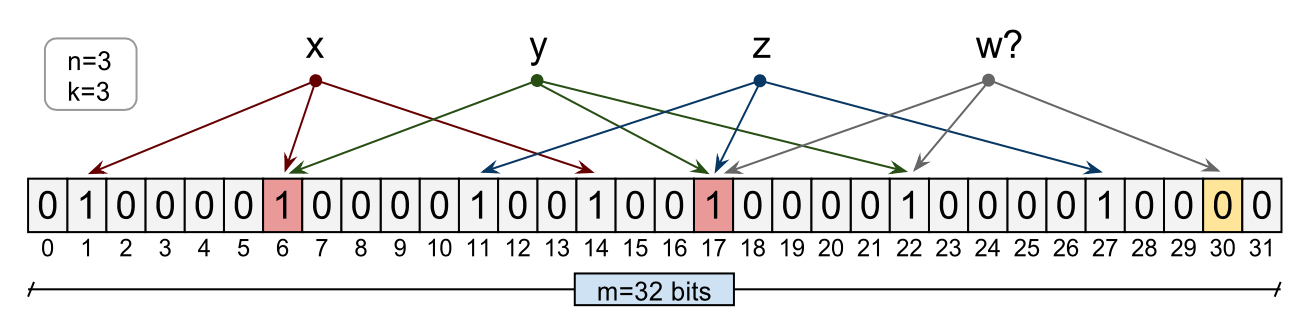 涉及与分布式系统相关的常见设计问题的关键模式:1. 布隆过滤器布隆过滤器是一种节省空间的概率数据结构,用于测试元素是否是集合的成员。它用于我们只需要知道元素是否属于它应该所在的地方(缓存)。在BigT.
涉及与分布式系统相关的常见设计问题的关键模式:1. 布隆过滤器布隆过滤器是一种节省空间的概率数据结构,用于测试元素是否是集合的成员。它用于我们只需要知道元素是否属于它应该所在的地方(缓存)。在BigT. -
缓存高一致性:Meta的缓存失效解决方案
1892 1
缓存有助于减少延迟、扩展读取繁重的工作负载并节省成本。它们实际上无处不在。缓存在您的手机和浏览器中运行。例如,CDN 和 DNS 本质上是地理复制缓存。多亏了许多在幕后工作的缓存,您现在可以阅读这篇博.
-
waraft: Erlang的Raft实现
856
WARaft是WhatsApp使用Erlang编写的一个Raft库。它提供了一个Erlang实现,在复制的状态机之间获得共识。共识是容错分布式系统的一个基本问题。WARaft已被用作WhatsApp消.
-
从架构师思维看分布式事务两种技术方案 - banq
1866 1 程序员从无到有构建代码,应该注重组合思维,做出来的东西需要能够相互组合在一起;而架构师是从上而下的视角,因为不参与具体细节构建,但为了落地,应该具有多维度多维度视角,从程序员到架构师思维转变很重要。下.
程序员从无到有构建代码,应该注重组合思维,做出来的东西需要能够相互组合在一起;而架构师是从上而下的视角,因为不参与具体细节构建,但为了落地,应该具有多维度多维度视角,从程序员到架构师思维转变很重要。下. -
分布式数据库的复制原理 - Quastor
994 3K
如果您对后端工程感兴趣,那么设计数据密集型应用程序 (DDIA) 是必读的。数据工程世界充满了流行语和炒作,但Martin Kleppman在分解所有核心技术方面做得非常出色。这是 DDIA 关于复制.
-
比UUID更快:如何生成分布式唯一时间戳标识符 - vanillajava
1827 1 3K
本文介绍了一个直接支持分布式标识符生成的实现。1. 分布式系统中的并发标识符生成每个主机都有一个预定义的唯一主机标识符或hostId 。TimeProvider[url=https://github..
-
tikv/raft-rs:在 Rust 中实现的 Raft 分布式共识算法源码
1621 1
在构建分布式系统时,一个主要目标通常是构建容错。也就是说,如果网络中的一个特定节点出现故障,或者存在网络分区,则整个集群不会发生故障。参与分布式共识协议的节点集群必须就价值达成一致,一旦达成该决定,该.
-
bastion-rs/bastion:类似Akka的高可用分布式容错Rust运行时
1241 1
Bastion 是一个高可用、容错的运行时系统,具有动态的、面向调度的、轻量级的进程模型。它通过轻量级进程实现提供类似参与者模型的并发性,并有效地利用所有系统资源来保证最多一次的消息传递。特点: 基于.
-
ChiselStore:Rust编写的Raft分布式SQLite数据库
2057
ChiselStore 是一个可嵌入的分布式Rust SQLite,SQLite 是一个快速而紧凑的关系数据库管理系统,但它仅限于单节点配置。ChiselStore 扩展 SQLite 在具有Raft.
-
什么是加密货币DAO?
1689加密货币DAO是去中心化自治组织(Decentralized Autonomous Organization简写),也称为去中心化自治公司,这类似一种有限责任公司,只不过无需CEO,是由程序代码自动执. -
shosti/wraft: 使用Rust和WebRTC在浏览器中实现分布式Raft
2410 1 2K 是一个基于 WebRTC 的 Raft 实现,用 Rust 编写,用于 WebAssembly。这里有几个演示应用程序,代码在 GitHub 上是开源的。这是一个有趣且具有挑战性的项目,所以我想我会写.
是一个基于 WebRTC 的 Raft 实现,用 Rust 编写,用于 WebAssembly。这里有几个演示应用程序,代码在 GitHub 上是开源的。这是一个有趣且具有挑战性的项目,所以我想我会写. -
Peritext:用于富文本协作的新型CRDT
1689 5K
Google Docs 等协作编辑器允许人们实时处理富文本文档,当用户希望立即查看彼此的更改时,这很方便。然而,有时人们更喜欢更异步的协作方式,在这种方式下,他们可以暂时处理文档的私人副本,然后再分享.
-
配置Apache Kafka生产者参数以获得高可用性和弹性 - Nabraj
1160 4K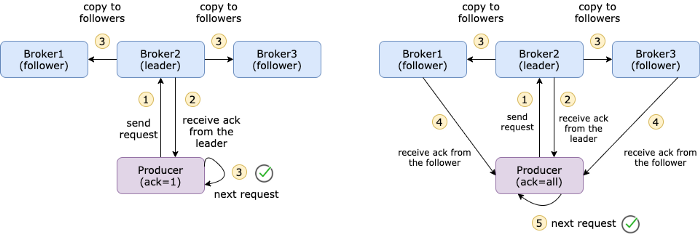 Apache kafka以其弹性、容错性和高吞吐量而闻名。但它的表现并不总是满足所有人的期望。在某些情况下,我们可以通过缩小或扩大代理规模来改进它。而在大多数情况下,我们必须玩配置游戏。在卡夫卡的生态.
Apache kafka以其弹性、容错性和高吞吐量而闻名。但它的表现并不总是满足所有人的期望。在某些情况下,我们可以通过缩小或扩大代理规模来改进它。而在大多数情况下,我们必须玩配置游戏。在卡夫卡的生态. -
分布式共识灵活Paxos英文参考资料目录
732 8K
灵活Paxos是比Paxos更宽松灵活的算法,它是一个简单的观察,不需要要求 Paxos 中的所有群体都参与,要求领导选举阶段(阶段 1)使用的仲裁与之前复制阶段(阶段 2)使用的仲裁能重叠就足够了。.
-
建模重要性:使用建模工具发现Paxos实现中的一个错误 - brooker
823
在过去的几周里,我一直在学习优秀的P 编程语言,一种用于建模和指定分布式系统的语言。我在 P 中做的第一件事就是实现 Paxos——一种我很熟悉的算法,有很多微妙的失败模式,而且很容易出错。为了测试 .
-
分布式共识协议Paxos本质是一次写入寄存器? - maheshba
1224 1 4K
在系统中,我们通过抽象来处理复杂性。对于任何系统,都存在三个关键问题: 它实现了什么抽象? 这种抽象的设计空间是什么? 为什么这个抽象有用? 在这篇文章中,我们将回答 Paxos 的前两个问题。本文档.
-
NFT可能创建了元宇宙的谢林点?
1223
谢林点是指基于理性前提下,人们没有事先沟通,而能达成的一种默契,注意,这是基于理性前提,不是基于心理暗示,大家都如果因为数字8吉祥而选择8,这属于基于心理暗示,理性前提是基于理智判断情况下,我知道你是.
-
如何在微服务分布式架构中删除数据? - bennorthrop
2098 1 3K
尽管微服务具有各种好处,但似乎也有许多新的复杂性和并发症。我最近经常遇到的一种情况(并没有找到很多很好的资源)是删除数据。考虑一个简单的例子:有三种服务:Product 服务,管理与所提供的产品,Or.
-
优步是如何使用Apache Flink和Kafka实现实时Exactly-Once广告事件处理?
1320 3K
优步最近推出了一项新功能:UberEats 上的广告。这种新能力带来了 Uber 需要解决的新挑战,例如广告拍卖、竞标、归因、报告等系统。本文重点介绍我们如何利用开源技术构建 Uber 的第一个“近实.
-
比较服务间通信的技术 - ardalis
1523 1 5K
在分布式软件应用程序中,不同的服务或进程或应用程序经常需要相互通信。微服务和容器以及云原生应用程序的现代架构趋势都增加了应用程序将越来越多地部署为相关服务的集合而不是单个单体的可能性。这些应用程序可以.
-
跨微服务的 ACID 事务
1002
大规模分布式系统上的分布式事务被认为本质上是邪恶的,需要按照CAP 定理,为了避免走弯路,请参考:分布式事务可能是个伪概念以及Shopify如何使用Saga等模式实现电子商务:Shopify如何使用R.
-
如何在多区域运行Zookeeper?- Ankur
1372 5K
Zookeeper将自己定义为“用于维护配置信息的集中式服务”等。为了对数据建模,它使用具有路径作为标识符并保存值的znode。在 Flipkart,我们使用 zookeeper 作为为多个应用程序提.
-
Uber如何重新架构其作业平台?
1180 1 7K
优步的使命是帮助我们的消费者在全球数千个城市轻松前往任何地方并获得任何东西。在其核心,我们捕捉消费者的意图并通过将其与一组正确的提供者进行匹配来实现它。 作业履行(Fulfillment )是“向客户.
-
Facebook开源分布式系统的NTP时间校准器
896
这是一种可以将任何PC服务器变成时间设备的 PCIe 卡,Facebook 工程师已经构建并开源了一个 Open Compute Time Appliance,这是现代计时基础设施的重要组成部分。Fa.
-
Redis Cluster:为高性能付出了不安全的代价 - emil
926 6K
本文旨在解释为什么 Redis 不适合用作 NoSQL 数据库,其中持久化数据的持久性和一致性是必不可少的。很难想到比 Redis 更广为人知的数据存储。在 Stack Overflow 上,它连续三.
