深入学习教程:从感知到深度神经网络
近年来在人工智能领域开始复苏。 它已经扩展到学术界以外的世界,主要参与者 谷歌 、微软和 脸谱网 都创建了自己的研究团队,并做了一些令人印象深刻的 收购 。
这可以归因于一些社交网络用户所产生的大量的原始数据,其中大部分需要分析。以及可以通过gpgpu实现的廉价的计算能力 。
这种复苏在很大程度上驱动了人工智能的新趋势,特别是在 机器学习 被称为"深度学习"。 在本教程将介绍深度学习背后的关键概念和算法,从最简单的组合单元和在Java中构建机器学习的基本概念。这些深度学习的源码库可见: here
感知:早期的深度学习
最早的监督训练算法是感知器,一个基本的神经网络构建块。
假设我们有 N 点在平面上, 有着"0"和"1"的标签, 我们给出一个新的点,我们想猜其标签。我们如何做?
一种可能方法是看最近的邻居返回的标签。 但稍微聪明的方式是最好选择一条线,分隔已经做过标签的数据,作为分类器。
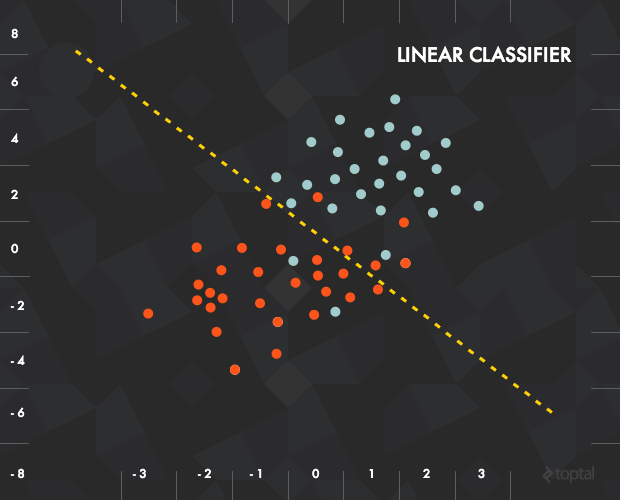
在这种情况下,每一块输入数据将表示为一个向量 X =( x_1、x_2 ),我们函数如果在线以下将是"' 0 ',如果在线以上将是' 1 '。
为了表示这个数学,让我们分隔符定义一个向量的权重 W 和一个垂直偏移量(或倾向) B 。 然后,使用加权和传递函数将我们的函数的输入和重量结合在一起:
![]()
传递函数的结果将被送入一个激活函数产生一个标签。 在上面的示例中,我们的激活函数是一个阈值(如大于某个值是1):
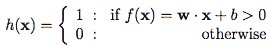
训练感知器
感知器的训练包括喂养它多个训练样本,计算每个阶段的输出。 在每次取样后,调整权重 W 以最小化 输出误差 ,该误差定义为期望的 (目标)和 实际 输出之间的差异 。还有其他的错误功能,如 均方误差 ,但训练的基本原理是相同的。
单一感知器的缺点
单一感知器的深度学习方法有一个主要的缺点:它只能学习 线性可分函数,取XOR,一个相对简单的函数,看它能不能被线性分类器分类?结果是不能。

为了解决这个问题,我们需要使用一个多层感知器,也称为前馈神经网络:实际上,我们一群这些感知器组合在一起来创建一个更强大的机制来学习。
深度学习前馈神经网络