大数据专题
在笔记本上实现Spark-GPU集群开发教程
速度、质量、开发时间…… 只能选择其中两个。 这是软件开发中一个古老的权衡。 这篇博客的目标是使用Apache Spark创建一个本地开发环境特别GPU集群计算,笔记本是Macbook Pro。
使其工作…… 然后让它快… 然后让它美丽——马修·罗素
我们将首先让每个部分单独"工作"。 然后进入第二阶段(速度提升),幸运的是速度下降大概是由于GPU集群。 最后,我们将这些部件集成到美丽的东西…… 一个可伸缩的、特别的环境。
第1部分:Spark-Notebook
Apache Spark在笔记本电脑中能被几种语言控制。 选择Scala有几个原因。 首先,它让我获得完整的Spark API, 其次,GPU库允许我无需编写编译C代码而直接使用Java(这样从scala调用Java)。 下面是几个选项:
Zeppelin -> buggy API
Spark-Notebook -> 导入依赖很头疼
Sparknotebook -> 就选择这个了,杀手级应用
下面是从Sparknotebook 仓储Clone下载一份,按照其指引操作,比如下载IScala.jar等等。
第2部分:在JVM上GPU
灵感来自于一个令人印象深刻的库包 ScalaNLP 。 他们声称有一个解析器,可以在一台计算机上每分钟解析一百万字。
ScalaNLP利用java opencl库, JavaCL 。 使用OpenCL而不是CUDA意味着可以在non-NVIDIA显卡上运行代码。 所有苹果电脑都可以使用OpenCL。
另外不希望编写C代码,因为移植性不强,我们需要企业级的开发,这就是 Aparapi 出现的原因。 它编译Java代码到OpenCL,如果不能获得一个GPU则使用Java线程池运行。
下载AparaPi Mac OS压缩包:
Aparapi_2012_01_23_MacOSX_zip
Aparapi_2013_01_23_linux_x86.zip
Aparapi_2013_01_23_windows_x86.zip
解压后创建一个目录称为Aparapi_2012_01_23_MacOSX_zip。执行:
cd Aparapi_2012_01_23_MacOSX_zip/samples/squares/
sh squares.sh
输出:
Execution mode=GPU
0 0
1 1
2 4
3 9
4 16
5 25
6 36
7 49
8 64
9 81
10 100
出现这个结果表示这个java代码可以运行在Macbook的GPU。
第3部分:整合Spark和笔记本中Aparapi
真正的挑战是让这些工具相互调用。 集成的第一步,我们需要做的就是aparapi jar导入iscala笔记本。 这可以通过使用下面的命令。
mvn install:install-file -Dfile=aparapi.jar -DgroupId=com.amd.aparapi -DartifactId=aparapi -Dversion=1.0 -Dpackaging=jar
在~/.ipython/profile_scala/ipython_config.py底部有一行:
c = get_config()
c.KernelManager.kernel_cmd = ["java","-Djava.library.path=/Users/.. .../Aparapi_2012_01_23_MacOSX_zip","-XX:MaxPermSize=2048m","-Xmx8g",
"-jar", "/Users/myname/.ipython/profile_scala/lib/IScala.jar","/Users/... .../Aparapi_2012_01_23_MacOSX_zip/aparapi.jar",
"--profile",
"{connection_file}",
"--parent"]
这让aparapi.jar置于Spark集群的classpath上。
注意设置环境变量:
SPARK_DAEMON_JAVA_OPTS=-Xmx8128m SPARK_WORKER_MEMORY=-Xmx2048m SPARK_DAEMON_MEMORY=-Xmx2048m SPARK_REPL_OPTS=-XX:MaxPermSize=2048m SBT_OPTS=-Xmx8128m SPARK_JAVA_OPTS="-Djava.library.path=/Users/... ..../Aparapi_2012_01_23_MacOSX_zip -Xms512m -Xmx8128m" ipython notebook --profile scala
当我们本地部署aparapi jar 时,需要像下面导入aprapi:
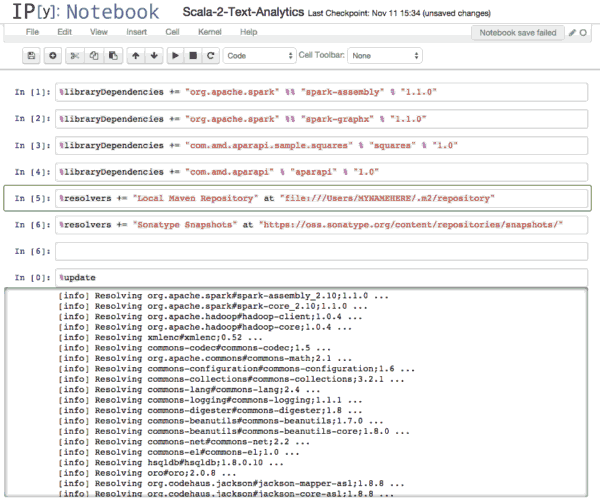
假设在upload命令中没有错误,滚动到列表底部会出现任何导入失败,那就表示一切正常,可以继续下一步。下面的演示scala notebook 是来自sparknotebook github。
第4部分:在笔记本(仅使用Scala)构建案例
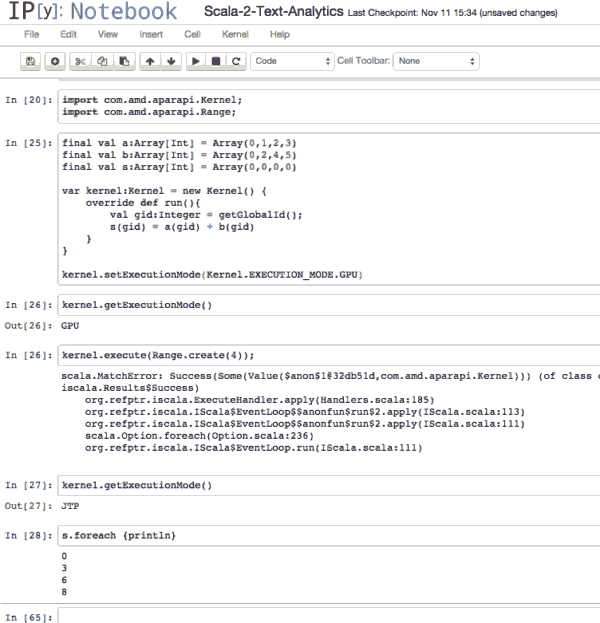
请注意,如果试图设置内核运行在GPU,但因为GPU无法使用,所以会出现切换版本运行在CPU上了。我们需要下一步:
第5部分:在Spark 集群执行GPU内核
当前面将aparapi jar安装到maven时,实际上是安装编译示例代码"squares",如果我们像黑客一样打开之前运行的"squares.sh",如下:
squares.sh
java \
-Djava.library.path=../.. \
-Dcom.amd.aparapi.executionMode=%1 \
-classpath ../../aparapi.jar:squares.jar \
com.amd.aparapi.sample.squares.Main
这意味着编译后的代码已经在我们的类路径… 我们可以从Spark 方法中调用,如下:
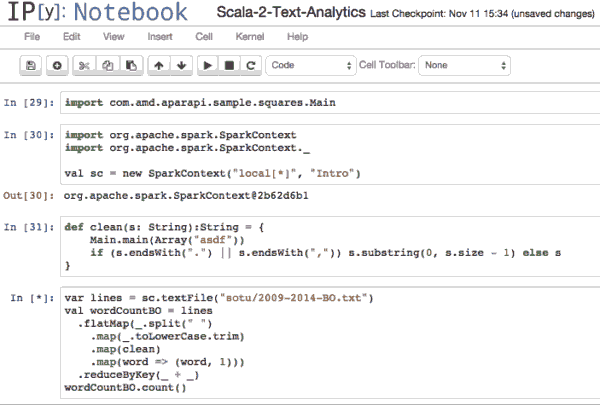
下面是Spark运行在笔记本上的内核上示意图:
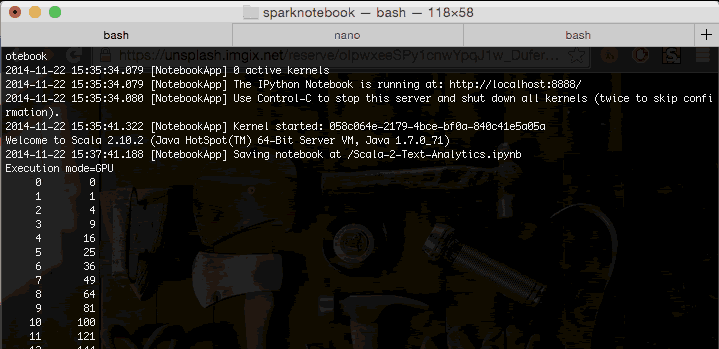
程序日志记录出现GPU…显示它确实是被运行在GPU。