In-Stream大数据处理模式
来自In-Stream Big Data Processing一文总结了当前大数据实时处理的通用设计和模式,主要是Storm, Cassandra, Kafka组合,也包括LinkedIn的Samza。
有关批数据处理(batch-oriented data processing:以Hadoop为基础的Hive或Pig等 )的问题和缺点大家已经意识到了,实践中需要实时查询和in-stream处理之类实时大数据处理,由此应运而生了Twitter’s Storm, Yahoo’s S4, Cloudera’s Impala, Apache Spark, 和 Apache Tez。
这些In-Stream处理技术是瞄准每天80亿的事件数据,提供容错和严格的事务,保证任何一个事件不丢失也不重复,这样的系统如果基于Hadoop批处理架构会带来高延迟和高成本维护,这就需要我们从更高层次抽象和总结出典型的模式。
高层次抽象图如下:
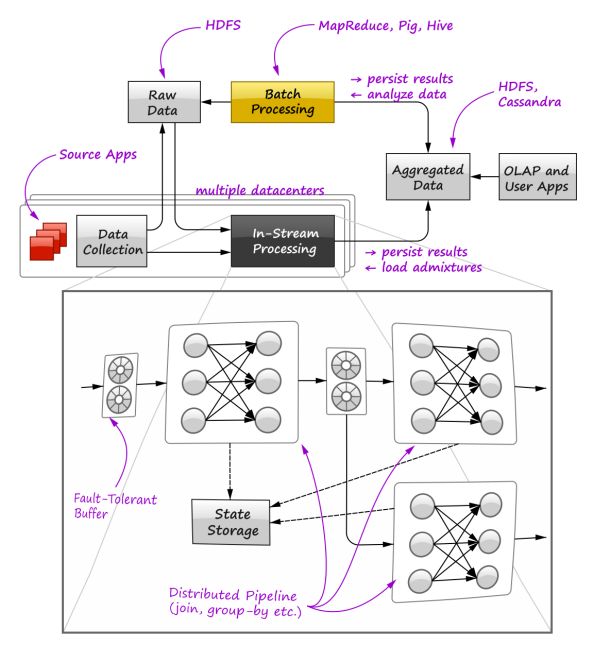
这张图主要表达了in-stream实时处理和批处理如何结合在一起,实现和OLAP接口,以供用户查询使用(banq注:类似Lambda架构),图中黄色部分代表以Hive为基础的Hive Pig批处理,而以Storm/Samza为代表的in-stream处理是黑色部分,这两条不同路线汇总的数据最后聚合在一起,供用户查询。
该图放大了in-stream处理内部细节,主要由容错Buffer 分布式的pipeline 和中间状态保存三个部分组成。
该文提出了Distributed Query Processing分布式查询处理,认为可以结合传统关系数据库和in-stream以及批处理三个不同架构于一体,统一提供对外查询接口。如下图:

在这个查询引擎中,可以抽象出三者共有的两个处理模式:
1. pipelining(管道线)
2. Partitioning(分区) 和 Shuffling(洗牌)
该文然后开始详细介绍这两种核心处理模式,待续.....
个人观点:如果说CQRS是一种命令和查询分离架构,而DDD是命令架构中核心,那么该查询引擎应该是CQRS查询架构中的核心。
[该贴被banq于2013-08-28 09:29修改过]








