ORM是明显的反模式
作为Java和Ruby程序员与架构师的Yegor昨天发表一篇博文:ORM Is an Offensive Anti-Pattern,认为ORM是一个可怕的反模式,违反了所有的面向对象原则,撕裂了对象,将它们变成哑巴和被动的数据袋,没有任何借口在任何应用程序中使用ORM,无论是成千上万的小型Web应用或企业级的基于数据表的CRUD操作系统(ORM包括Java的Hibernate/JPA,python的django,),那么取而代之是什么?会讲SQL的对象 (SQL-speaking object)。
ORM是如何工作的
对象关系数据库ORM技术或模式是使用面向对象技术如Java访问一个关系数据库,每个语言都有ORM实现,如Java的Hibernate,Ruby的active record, PHP的Doctrine, Python的 SQLAlchemy,在java中,ORM甚至被设计为标准,如JPA。
首先,让我们看看ORM是如何工作的,。 让我们使用Java,PostgreSQL,Hibernate。 假设我们有一个表在数据库中,称为post :
|
现在,我们需要为这个表产生Java应用的CRUD方式(增删改查),首先,我们曾经一个Post类:
|
在使用Hibernate操作之前,我们得创建一个session工厂:
|
工厂每次我们要使用Post对象时产生一个session,每次使用session应当如下使用代码包装:
|
当session准备好后,下面我们就可以从数据表中获取所有的post:
|
我认为这是清楚的, Hibernate是一个强大的连接到数据库的引擎,通过执行必要的SQL SELECT请求,获取检索数据。 然后它创建了类Post的实例,并将数据装入其中。 当这个对象过来时,它填满了数据,我们应该使用getter方法将这些数据取出,比如我们使用 getTitle() 方法。
当我们想做一个反向操作,将一个对象发送到数据库,我们做的都基本相同,只不过以相反的顺序。 我们创建类Post的一个实例 文章,然后塞进入数据,请求Hibernate保存它:
|
这是几乎是每一个ORM工作原理。 基本原则始终是相同的——ORM装有数据的贫血对象。 我们谈论的是ORM框架,这些框架与数据库交互, 对象只有帮助我们将请求发送给ORM框架,并理解其响应。 除了getter和setter,对象没有其他方法。 他们甚至不知道他们来自哪个数据库。
这是对象关系映射是如何工作的。
也许你会问,怎么了?
ORM怎么了?
说真的,有什么错吗? Hibernate是最流行的Java库,已经超过10年了。 世界上几乎每一个SQL-intensive应用程序都是使用它。 每个Java教程会提及Hibernate(或者 其他一些ORM 像TopLink或OpenJPA)用于database-connected应用程序。 它实际上是一个标准, 然而我还要说它错了? 是的。
我声称整个ORM背后的想法是错误的。 它的发明是也许OOP领域空引用之后第二大错误 。
其实,我不是唯一一个说这样的事情的人,绝对不是第一个。 很多非常受人尊敬的作者已经发表关于这个主题,包括 Matinfowler的OrmHate , Jeff Atwood的对象关系映射是计算机科学的越南战争 ,Ted Neward的计算机科学的越南 , Laurie Voss的ORM是一种反模式,等等还有许多其他人。
然而我的观点不同于他们所说的,尽管他们的理由是来自实践且有效,如ORM是慢的,数据库升级很难等,他们错失了主要点,你能从Bozhidar Bozhanov的ORM Haters Don’t Get It文章中看到非常好的实战回答。
ORM主要点并不是封装数据库交互到一个对象,释放数据,遍历时撕开了坚固且聚合的living organism(实体),对象的一部分保持数据,而另外一部分是在ORM引擎(session factory)内部执行,这些引擎知道如何处理这些数据,并且转换它到关系数据库,看看这张图,它模拟了ORM如何工作:
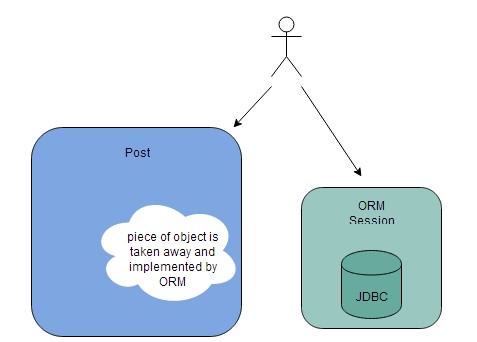
我作为Post文章的读者,得和两个组件打交道,1是ORM,2是返回一个砍了头的对象,我打交道的行为应该有一个单点(操作一个组件),这个对象才是OOP,而在ORM这种情况下,我得与两个点打交道,ORM和数据对象,甚至我们都不能称之为对象。
因为这个可怕的和明显地违反了面向对象范式,我们已经有很多实际中受人尊敬的出版物都在提到这个问题,这里举例一些:
SQL并没有隐藏,ORM的用户应该会使用SQL(或者方言如HQL),看看上面案例,我们调用session.createQuery("FROM Post")是为了获得所有文章Posts,即使它不是SQL,也很类型,关系模型并没有被封装到对象中,相反,它暴露在整个应用程序中,使用这个对象的每个人都必须与关系数据库打交道,以获得或保存什么,这样ORM并没有隐藏和封装SQL,而是污染了整个应用程序。
难以测试。当一些对象要与Posts文章列表交互时,它需要处理一个实例 SessionFactory 。 我们如何在测试中模拟这种依赖性? 我们必须创建一个它的模拟吗? 这个任务有多复杂? 看看上面的代码,你将意识到冗长和繁琐的单元测试。 相反,我们可以编写集成测试并将整个应用程序连接到一个测试版本的PostgreSQL。 在这种情况下,没有必要模拟一个 SessionFactory ,但这种测试将会相当缓慢,更重要的是,我们却将一个并没有和数据库有关系的数据对象却作为数据库的实例对象进行测试。非常糟糕的设计。
我要再次重申。 上面ORM问题导致的后果。 ORM基本缺点是撕裂了对象,可怕和明显违反了对象理念:一个对象是什么。
待续见下贴:
[该贴被banq于2014-12-02 11:55修改过]