如果您的公司建立在单体monolith之上。由于您的业务知识在内部传播,因此这种单体monolith可能是您的最佳资产,但是由于多年的技术债务和团队在相互沟通的情况下发布代码,这些是脏的。
单体程序缓慢,不透明,容易出错,未经测试。发布新代码时开发人员和sysops团队都开始担心,因此最终会建立和定义繁重的流程以及漫长的发布周期和漫长的手动测试过程。这是因为我们需要安全地发布新版本,我们不能中断生产,因为恢复或回滚很困难。
但是,单体仍然存在,可以为您带来大部分收入,但也会影响团队的表现。您如何改善主要收入来源并优化团队以实现长期可预测性和业务发展?这是DDD派上用场的地方。
但是,在使用DDD之前,我们需要了解为什么单体程序仍在工作并为大量流量提供服务。因为单体本身不是一个错误的根源,问题出在耦合造成大泥球。
单体非常便宜且用途广泛。单体架构能够长期存在的原因是,单体架构中的决策在中期是可恢复的。因为数据和代码在一个地方,所以重构更简单(可以使用您最喜欢的IDE来完成),并且数据传输便宜。例如,让我们从以下用例开始:
我们是像Amazon这样的在线购物平台,并且我们出售图书。在产品的第一个迭代期间,我们不会验证仓库中书籍的库存,因为我们没有收到那么多的采购订单,因此我们可以手动修复损坏的订单。我们最终得到以下架构图。 几个月后,我们的业务开始增长,每分钟开始有几笔订单,黑色星期五和圣诞节期间的订单量达到顶峰。由于我们的书籍缺货,我们无法处理越来越多的订单中断。我们决定实现一个StockService,该服务将在结帐过程中验证我们要购买的书籍是否仍有库存。
几个月后,我们的业务开始增长,每分钟开始有几笔订单,黑色星期五和圣诞节期间的订单量达到顶峰。由于我们的书籍缺货,我们无法处理越来越多的订单中断。我们决定实现一个StockService,该服务将在结帐过程中验证我们要购买的书籍是否仍有库存。
如您所见,添加新服务和业务规则非常便宜:只需添加一些新类和对其他服务的依赖关系就足够了。我们没有做出艰难的决定,我们只是遵循单体中已经存在的模式。我们可以这样做是因为:
- 单体移动数据很便宜
- 单体中的决策仅限于单个过程
- 单体具有明确且通用的模式
- 可以使用IDE的帮助来重构单体结构
因此,我们正在做的事情是向前推进,而不是做出复杂的设计决策并提供新功能,从而增加了技术负担。这使小型团队可以快速迭代产品,但是,随着团队数量的增长,这是一个问题。原因是因为不同的团队将需要来自不同服务的数据和逻辑来满足用户需求。

如您所见,在UserService上,团队A和团队C之间存在重叠,因为他们俩都需要来自其用户的数据以保证其功能。面对这种情况的方法有3种,在下表中分为三类:求职,协作和效果。
所有权 合作 影响 |
因为没有解决此问题的简单方法,所以解决方案是拆分整体。要了解在同一代码中拥有不同团队的复杂性,只需参考使两个线程在内存中使用同一组数百个变量的复杂性即可。
因此,经过几个月或几年的工作,我们将这种单体整体分成了微服务。我见过的最常见的分割整体的方法是定义数据边界的策略。例如,所有与用户相关的数据将最终出现在UserService中,StockService中的库存信息等等。
这种方法的问题在于:
- 它可能看起来像域驱动设计,但事实并非如此,因为它基于数据,而不是业务知识。
- 它可能看起来像微服务架构,但事实并非如此,因为服务之间的耦合度很高,因此服务和团队都不是自治的。
而且,我们构建了一个分布式的单体,它无法轻松移动数据并且无法使用IDE进行重构,因此基础架构成本也更高。那么,我们如何确保不会出现这种情况呢?
我会做的最基本的建议是根据(业务领域)知识而非数据来划分您的架构。公司如何构造知识完全取决于人员和他们所从事的业务,但是可以尝试几种廉价的探索模式。
要应用这些模式,我们需要将业务视为业务平台:我们没有一个产品,而是我们有一套产品。这些产品的定义是适用于角色的一组功能。例如,基于此模式,我们可以定义购物平台,如下图所示:
每个产品的成功都应独立衡量和发展。但是,正如您所注意到的,某些跨产品模块可能存在依赖性。例如,一键购买(1 click purchase)产品类似普通购买(purchase)产品,它们可能取决于库存和用户信息。
我们如何确保那些依赖关系不会影响团队绩效并且我们不重复逻辑?
首先,我们需要将产品切成模块,以了解可能发生耦合的地方:
正如你所看到的,一键购买1 click purchase和普通购买Purchase需要来自同一来源的信息。但是,如果我们更深入,我们将看到差异:
- 会同时使用一键购买1 click purchase和普通购买standard purchase的购买者是否相同?
- 我们需要的书籍信息在两个过程中是相同的吗?
- 这两种产品中库存信息是否以相同方式相关?
- 两种产品中的装运信息是否使用相同的方式?
如果是这些问题yes,那么我们可能要制造的两倍数量的系统,因此至少其中一些最有可能no, they are different。让我们仔细看看:
数据源 一键购买 普通购买 |
购买者 只有先买过书的人才需要此功能 每个购买者都需要普通购买 |
在我们的案例中,只有书籍在两种产品中具有相同的特征,它们不是行为而是数据。这种情况意味着我们的产品分别有一个有界的上下文,在这些上下文中,对用户问题的了解和理解是不同的。这是有道理的,因为我们将知识链接到产品,产品链接到角色。(banq注:同一个书籍存在于不同有界上下文,也就是产品中)
当我们在有界上下文之间(不同产品之间)共享信息时,我们应该尽可能支持团队绩效。这意味着有时我们需要重复知识。这在其他系统中很常见:我们在浴室和厨房都有洗手池。
有多种方法可以跨有界上下文共享数据,我个人更喜欢使用基于事件的体系结构(如SQS)或数据流传输平台(如Kafka,进行状态采购)进行数据流传输。您还可以使用更简单的工具(例如数据库视图)共享信息(如果您拥有分布式数据库(例如Yugabyte或AWS RDS))。
即使这些模式看起来很浪费,也请考虑一下我们的身体如何运作。我们的身体总是在向我们的肌肉和器官输送血液,以确保可得性和健康。现在考虑一下,在您的身体中,每当肌肉想要运动时,是否需要向您的心脏请求一些血液,因此您的心脏需要向您的肺部请求氧气。现在每秒钟重复一次。
但是,信息需要来自其他有界上下文(例如,新买家的注册流程),并且他们需要信息的所有者。我们可以发泡,漂洗,重复和分裂更多的产品,直到我们拥有更小的模块,这些模块对于我们的团队来说更容易处理。例如,下图显示了在假想的图书购物平台上的产品和依存关系:
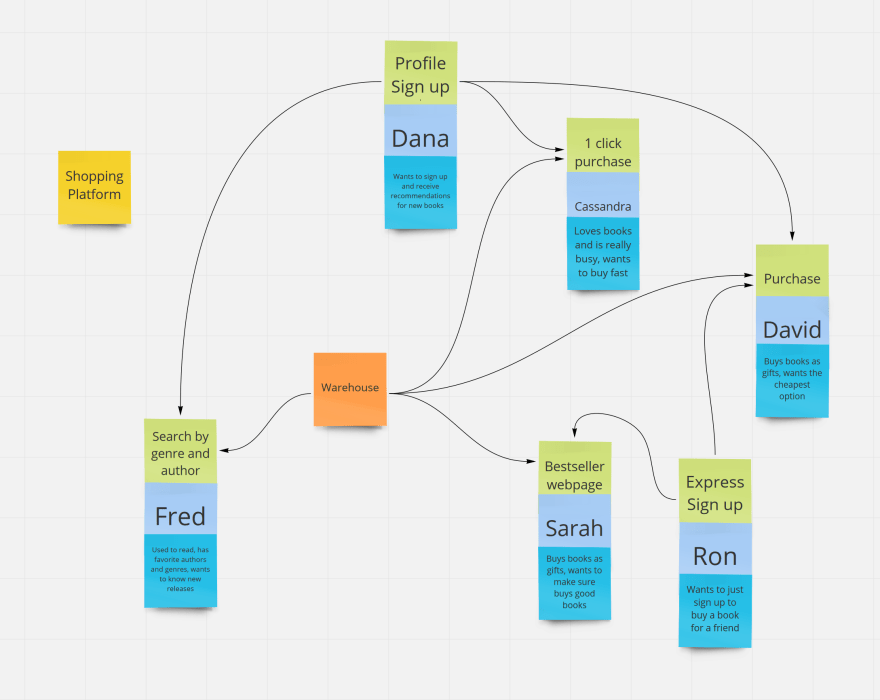
如果我们发现大部分的相关信息暴露给其他产品(有界上下文),我们可以抽象产品到一个更通用的上下文(一般用于角色,不用于业务),并公开一个更简单的服务(例如UserService)。
因此,总而言之,我想分享一些我认为有用的观点:
- 在平台中思考可以使我们更好地拆分业务。
- 将产品链接到角色和有界上下文,可以使边界明确。(banq注:产品=有界上下文=功能特性集)
- State-sourcing和事件驱动的体系结构对于构建分布式和可用平台至关重要。
- 团队不应共享代码,而应共享一个公共业务平台(banq注:中台)。