将MongoDB从2000 个事件/秒处理吞吐量提升到惊人的 80,000 个事件/秒。
介绍
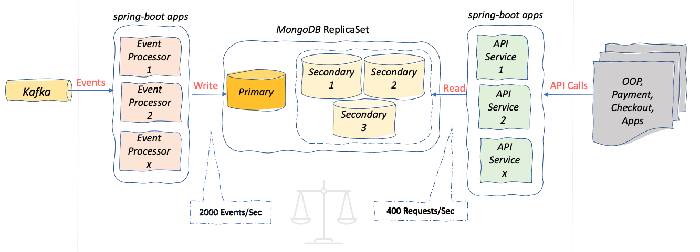
如下图所示,我们的系统必须在事件处理应用程序完成的写入和 API 服务应用程序完成的读取之间取得平衡。每当事件处理应用程序需要写入超过平均水平(2K 个事件/秒)时,API 应用程序就会出现巨大的中断和响应超时(P99>500 毫秒),从而打破了我们的 SLA。
 本文解释了我们如何识别和修复 MongoDB 中的瓶颈并实现令人难以置信的性能提升。
提示:最大的性能提升顺序:
本文解释了我们如何识别和修复 MongoDB 中的瓶颈并实现令人难以置信的性能提升。
提示:最大的性能提升顺序:
- 将所有 Simple MongoDB 索引替换为复合索引
- 压缩 MongoDB 文档中最大的 JSON 字段
- 采用 Kafka batching + MongoDB BulkOperations进行事件处理
- 使用 Mark-Sweep 技术控制删除
1.索引优化
在确认 API 响应时间不佳是由于慢查询数量增加导致后,我们重新访问了现有的 MongoDB 索引。
慢查询:需要超过 100 毫秒才能完成的查询
幸运的是, Idealo 有一个令人难以置信的MongoDB 分析器工具,可以监控我们所有的 MongoDB 副本集,我们可以将其用于我们的调查。
MongoDB 分析器结果显示我们现有的索引是次优的:所述totalDocsExamined到nReturned 比5:1
所以我们用复合索引替换了所有现有的简单索引:新的 QueryPlan 显示totalDocsExamined与nReturned 的 比率为1:1。即:MongoDB 返回它从磁盘读取的所有 Doc,因为所有必要的过滤都已经被新的复合索引覆盖了。
99% 的慢查询都消失了!
2. 压缩最大的 JSON 字段
虽然索引优化删除了 99% 的慢查询,但仍然偶尔会出现 API 响应延迟和超时。我们的性能测试揭示了一个有趣的发现。深入查看这些 JSON 文档发现文档的大小非常巨大。
关于模式设计的事实
- 文档是自包含的,其中包含所有可能的字段。因此在阅读时不再与其他集合建立关系和连接
- 单个 JSON 文档平均有 3000 多行,其中 90% 属于单个字段 offerList
- MongoDB 分析器工具显示单个查询传输高达 8MB!仅慢查询就占了从 MongoDB 传输的 30GB 数据。
应用级压缩的 PoC:选择一种更适合我们数据的通用压缩算法。因此,我们编写了一个小程序来比较GZip与LZ4_Fast与Zstd以及3 种不同输入大小的实验。小: 103.25Kb | 中: 4.02Mb |大: 12.5Mb。
我们的实验结果支持zstd ,它提供了最佳压缩比和最佳解压缩速度。
带有压缩的架构:
{
“_id”:“{...}”,
“offerListId” : “XXXXXXXXXXX” ,
“parentProductId” : NumberLong ( 5380287 ),
“olBytes”:BinData(0,“KLUv/WCRNv1KAFp23BU2MIu2AUBeWCiw......” ),
"rawLen" : NumberInt ( 14225 )
}
|
olBytes替换旧的纯 JSON 字段offerList.另请注意,rawLen添加了一个新字段来存储纯 JSON 的原始长度。这将被算法用于在解压缩时分配准确的缓冲区,从而显着提高解压缩时间。
这次用压缩重复性能测试,显示出令人鼓舞的结果。
我们实时推出了压缩改进,结果非常棒。
- 正常的事件处理吞吐量从 2000 个事件/秒增加到 9000 个事件/秒 (4X)。
- 性能测试吞吐量高达 80,000 个事件/秒,这在以前是不可能的。我们见证了野兽模式的行动!
- 所有数据库查询 (P99) 现在都可以在 < 15 毫秒内完成。
- 减少网络 I/O 并大大减少应用程序对 JVM 堆的使用(减少 4 倍)
注意:如果您想知道为什么我们进行应用程序级压缩而不使用 MongoDB 的内置压缩,原因如下
- 1. MongoDB 的压缩仅针对静态数据以节省磁盘空间。当从磁盘访问压缩的集合数据时,它将在内存/缓存中解压缩。
- 2.另外,不支持压缩Document中的单个字段
3. Kafka 批处理 + MongoDB BulkOperations
使用批处理之前,需要 100 次往返 MongoDB 来处理 100 个事件,现在只需要一次。更重要的是?它做了同样的工作,但应用程序(副本)减少了 2 倍。批处理大大提高了资源利用率。
BulkOperations bulkOps
= mongoTemplate.bulkOps(BulkOperations.BulkMode.UNORDERED);
bulkOps.upsert(upsertList);
bulkOps.updateMulti(deletList);
return bulkOps.execute();
|
4. Mark-Sweep 控制删除
在一个较大的集合(1300 万个文档)上在很短的时间内删除大量文档显示出一些负面的阅读性能。这可能是由于昂贵的索引计算。
传入事件代表更新或删除操作,我们处理它,然后它到达。我们无法真正控制限制和传播删除率。所以我们决定来一个。
实施标记-清除
在事件处理应用程序中,收到删除事件后,
- 不要删除相关文档
- 而是附加一个新的删除标记字段。例如:{'del':true}
- 通过后台调度程序,使用BulkMode删除带有限制的“标记”文档
总结
- 复合索引消除了 99% 的慢查询。有了更好的索引,磁盘访问就减少到绝对需要。
- 压缩最大的字段消除了 99.9% 的慢查询,并提供了令人难以置信的全方位性能提升。
- 批量化极大地提高了资源利用率。它将App ←to→ MongoDB 交互减少了 100 倍(批量大小)
- Mark-Sweep Delete方法提高了大型 MongoDB 集合的稳定性。