在 Cloudflare,我们采取措施确保我们在基础设施的各个层面都能抵御故障。这包括 Kafka,我们将其用于关键工作流程,例如发送对时间敏感的电子邮件和警报。
我们学到了很多关于保持利用 Kafka 的应用程序健康的知识,因此它们可以始终运行。众所周知,应用程序健康检查难以实施:是什么决定应用程序是否健康?如何让服务时刻保持运行?
这些可以通过多种方式实现。我们将讨论一种方法,该方法使我们能够大大减少不健康应用程序的事件,同时需要更少的人工干预。
Cloudflare 中的 Kafka
Cloudflare 是 Kafka 的主要采用者。由于其异步性和可靠性,我们使用 Kafka 作为解耦服务的方法。它允许不同的团队有效地工作,而不会相互依赖。您还可以在这篇文章中阅读有关 Cloudflare 的其他团队如何使用 Kafka 的更多信息。
Kafka 用于发送和接收消息。消息代表某种事件,例如信用卡付款或在您的平台中创建的新用户的详细信息。这些消息可以用多种方式表示:JSON、Protobuf、Avro 等。
Kafka 在主题中组织消息。主题是事件的有序日志,其中每条消息都标有渐进偏移量。当外部系统写入事件时,会将其附加到该主题的末尾。默认情况下,这些事件不会从主题中删除(可以应用保留)。
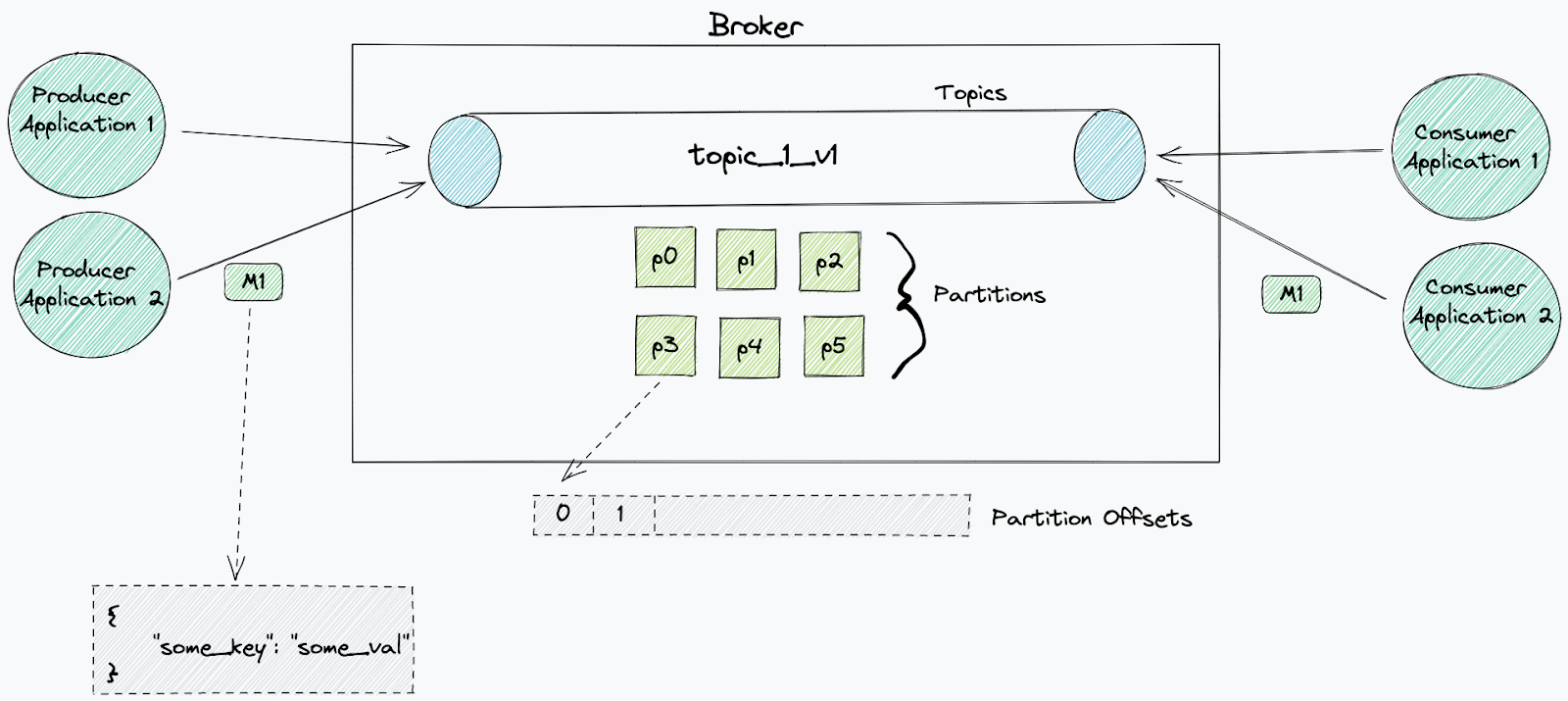
主题作为日志文件存储在磁盘上,其大小是有限的。分区是一种将一个主题日志文件分成许多日志的系统方法,每个日志都可以托管在单独的服务器上——从而能够扩展主题。主题由 Kafka 集群中的代理节点管理。它们负责将新事件写入分区、提供读取服务并在它们之间复制分区。
消息可以由单个消费者或协调的消费者组(称为消费者组)使用。
消费者使用唯一 ID(消费者 ID),允许代理将它们识别为正在从特定主题消费的应用程序。每个主题都可以被无数不同的消费者阅读,只要他们使用不同的 id。每个消费者都可以根据需要多次重播相同的消息。
当消费者开始从主题消费时,它将处理来自每个分区的所有消息,从选定的偏移量开始。对于消费者组,分区被分配给组中的每个消费者。这个划分是由消费者组长决定的。该领导者将接收有关组中其他消费者的信息,并将决定哪些消费者将从哪些分区接收消息(分区策略)。
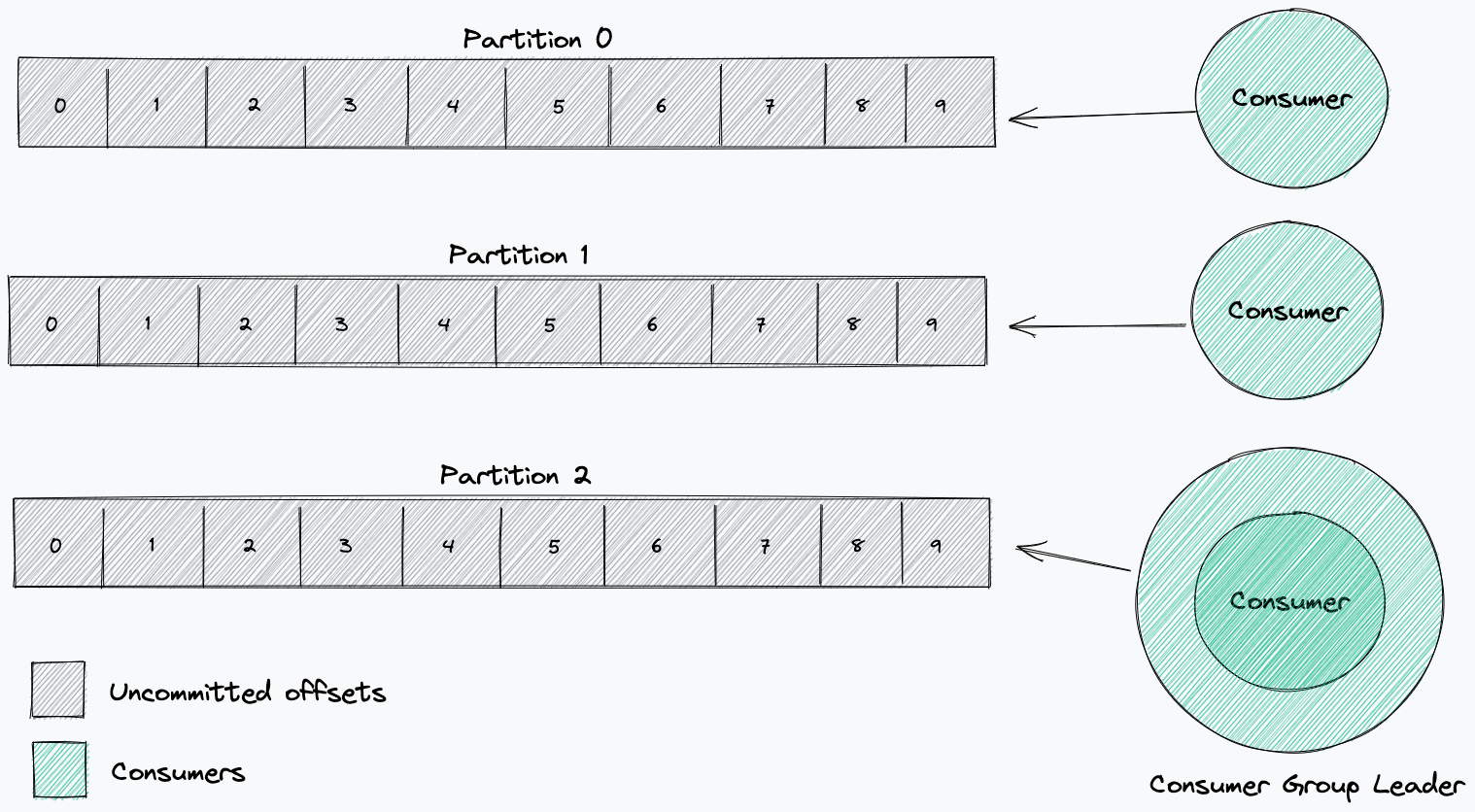
消费者提交的偏移量可以证明消费者是否按预期工作。提交已处理的偏移量是消费者及其消费者组向代理报告他们已处理特定消息的方式。
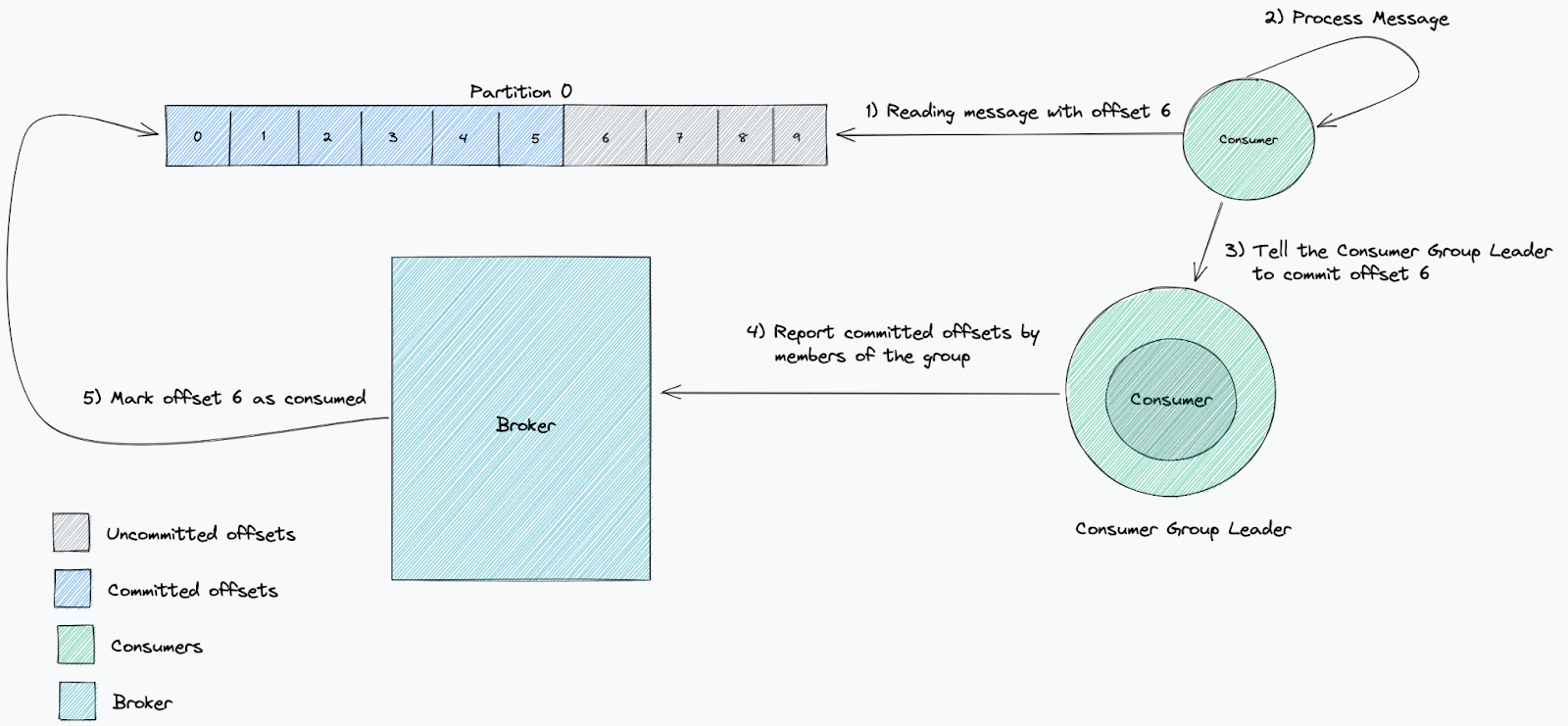
消费者处理速度是否足够快的标准衡量标准是滞后。我们用它来衡量我们落后于最新消息的程度。这跟踪消息写入主题和从主题读取消息之间经过的时间。当服务落后时,这意味着消费速度低于新消息的产生速度。
由于 Cloudflare 的规模,消息速率通常最终会非常大,而且许多请求对时间很敏感,因此监控这一点至关重要。
在 Cloudflare,我们使用 Kafka 的应用程序作为微服务部署在 Kubernetes 上。
Kubernetes 应用的健康检查
Kubernetes 使用探测器来了解服务是否健康以及是否准备好接收流量或运行。当 liveness 探测失败并且超过重试界限时,Kubernetes 会重新启动服务。
当就绪探测失败并且超过重试限制时,它会停止向目标 pod 发送 HTTP 流量。对于 Kafka 应用程序,这无关紧要,因为它们不运行 http 服务器。出于这个原因,我们将只介绍活性检查。
对消费者进行的经典 Kafka 活性liveness 检查检查与代理的连接状态。通常最好的做法是保持这些检查简单并执行一些基本操作——在这种情况下,比如列出主题。如果出于任何原因此检查始终失败,例如代理返回 TLS 错误,Kubernetes 将终止服务并启动同一服务的新 pod,从而强制建立新连接。简单的 Kafka 活性liveness 检查可以很好地了解与代理的连接何时不健康。
Kafka健康检查的问题
由于 Cloudflare 的规模,我们的许多 Kafka 主题被分成多个分区(在某些情况下可能是数百个!)并且在许多情况下,我们消费服务的副本数不一定与 Kafka 主题上的分区数相匹配. 这可能意味着在很多情况下,这种简单的健康检查方法是不够的!
如果从 Kafka 主题消费的微服务在消息发布到主题时定期消费和提交偏移量,那么它们是健康的。当此类服务未按预期提交偏移量时,这意味着消费者处于不良状态,并且它将开始累积滞后。我们经常采取的一种做法是在 Kubernetes 中手动终止并重启服务,这会导致重新连接和重新平衡。
当消费者加入或离开消费者组时,会触发重新平衡,消费者组负责人必须重新分配哪些消费者将从哪些分区读取。
当重新平衡发生时,通知每个消费者停止消费。一些消费者可能会将分配给他们的分区拿走并重新分配给另一个消费者。我们注意到在我们的库实现中何时发生了这种情况;如果消费者不确认此命令,它将无限期地等待从不再分配给它的分区中消费新消息,最终导致死锁。通常需要手动重启有故障的客户端应用程序才能恢复处理。
智能健康检查
当我们看到消费者报告“健康”但无所事事时,我们突然想到,也许我们在健康检查中关注的是错误的事情。仅仅因为服务连接到 Kafka broker 并且可以从主题中读取,并不意味着消费者正在主动处理消息。
因此,我们意识到我们应该专注于消息摄取,使用偏移值来确保取得进展。
1、PagerDuty 方法
PagerDuty 写了一篇关于这个主题的优秀博客,我们在提出我们的方法时将其作为灵感。
他们的方法使用当前(最新)偏移量和承诺的偏移量值。当前偏移量表示发送到主题的最后一条消息,而提交的偏移量是消费者处理的最后一条消息。
通过确保最新的偏移量发生变化(接收新消息)并且提交的偏移量也在发生变化(处理新消息)来检查消费者是否向前移动。
因此,我们提出了解决方案:
- 如果我们无法读取当前偏移量,则活性探测失败。
- 如果我们无法读取提交的偏移量,则活性探测失败。
- 如果提交的偏移量 == 当前偏移量,则通过 liveness 探测。
- 如果自上次运行健康检查以来提交的偏移量的值没有改变,则活动探测失败。
为了衡量提交的偏移量是否发生变化,我们需要存储上一次运行的值,我们使用内存映射来实现,其中分区号是键。这意味着我们服务的每个实例仅具有当前正在使用的分区的视图,并将对每个分区运行健康检查。
新问题
当我们第一次推出智能健康检查时,我们开始注意到发布后一段时间的级联故障。经过初步调查后,我们意识到这是在重新平衡发生时发生的。它最初会影响一个副本,然后很快导致其他副本报告为不健康。
我们观察到的是由于我们将提交偏移量的先前值存储在内存中,当发生重新平衡时,服务可能会重新分配到不同的分区。当这种情况发生时,意味着我们的服务错误地假设该分区的提交偏移量没有改变(因为这个特定的副本不再更新最新值),因此它会开始报告服务不健康。失败的 liveness 探测将导致它重新启动,这反过来又会触发 Kafka 中的另一次重新平衡,导致其他副本面临同样的问题。
解决方案
为了解决这个问题,我们需要确保每个副本只跟踪它当时正在使用的分区的偏移量。幸运的是,我们内部使用的 Shopify Sarama 库具有观察重新平衡何时发生的功能。这意味着我们可以使用它来重建内存中的偏移量映射,以便它只包含相关的分区值。
这是通过从会话上下文通道接收信号来处理的:
for { |
验证这个解决方案很简单,我们只需要触发重新平衡。为了测试这在所有可能的场景中是否有效,我们启动了一个服务的单个副本,该副本使用多个分区,然后继续扩大副本数量,直到它与分区计数匹配,然后缩减为单个副本。通过这样做,我们验证了运行状况检查可以安全地处理分配的新分区以及被删除的分区。