Kafka消息系统教程
Apache Kafka – 集群架构

Apache Kafka 到目前为止已经非常适合开发可靠的互联网规模的流应用程序,这些应用程序还具有容错能力,并且能够处理实时和可扩展的需求。在本文中,我们将重点介绍 Java 中的 Kafka 集群.
Spring Boot 中动态管理 Kafka 监听器

在当今的事件驱动架构中,有效管理数据流至关重要。Apache Kafka是一个流行的选择,但尽管有Spring Kafka等辅助框架,但将其集成到我们的应用程序中仍面临挑战。一项主要挑战是实施适当的动.
Kafka中手工提交偏移量的4种方法

在Kafka中,消费者从分区读取消息。在读取消息时,需要考虑一些问题,例如确定从分区中读取哪些消息,或者防止重复读取消息或在发生故障时丢失消息。解决这些问题的方法是使用偏移量。在本教程中,我们将了解 .
实时数据处理:Kafka 和 Flink

在大数据时代,实时洞察是保持领先的关键。但是如何利用不断流动的数据流的力量呢?Apache Kafka 和 Apache Flink登场,这对实时数据处理带来革命性变革的梦之队。这对充满活力的二人组协.
Redpanda简介
在本教程中,我们将讨论一个名为Redpanda的强大事件流平台。这是对事实上的行业流媒体平台Kafka 的竞争,有趣的是,它还与 Kafka API 兼容。我们将了解 Redpanda 的关键组件、功.
Spring Boot与Kafka + kafdrop结合使用的简单示例

该项目是如何将 Kafka 与 Spring Boot 结合使用的简单示例。我们将使用kafdrop显示本地 kafka 集群 UI。它有一个名为的主题product-topic,我们将通过 REST.
Kafka中避免重复消息的5种有效方法
Apache Kafka 因其强大的特性而成为分布式消息系统的不错选择。在本文中,我们将探讨避免Apache Kafka消费者中出现重复消息的高级策略。重复消息消费的挑战Apache Kafka 的至.
Apache Kafka 中 GroupId 和 ConsumerId 的区别

在本教程中,我们将阐明Apache Kafka中 GroupId 和 ConsumerId 之间的区别,这对于理解如何正确设置消费者非常重要。此外,我们还将讨论 ClientId 和 Consumer.
API 优先的 Kafka 主题创建方法

要点: DoorDash 工程团队通过内部 API 和基础设施服务改进了 Kafka 主题创建方法,实现了实时管道启动时间的大幅减少,节省了开发人员的时间。 他们开发了一个基于 Infra Servi.
案例:使用 Web UI 探索近乎实时的流数据
Expedia Group是世界领先的在线旅游平台之一,他们开发了一个工具,帮助用户使用Kafka、Postgres和WebSockets查询和获取实时流数据,并通过Web浏览器获取实时事件他们面临的.
在Spring Boot中创建 Kafka 主题
在本教程中,您将学习如何在 Spring Boot 应用程序中创建新的 Kafka 主题。当新消息发送到 Kafka 主题时,也可以自动创建主题。然而,在生产环境中,主题自动创建通常是关闭的。这就是为.
Apache Kafka中"主题"的综合指南

在本指南中,您将了解有关 Kafka 主题(Kafka 中数据的核心结构)的更多信息。您将学习如何有效地创建、管理和利用 Kafka 主题。每个步骤都包含实际示例和简单的解释,确保清晰理解。什么是 A.
使用 Apache Kafka 和 Spring Modulith 实现发件箱模式

在这篇博客中,我们将探讨事件驱动系统中常见的“双写”问题,以及如何使用 Spring Modulith 来简单地实现 Outbox 模式来解决该问题。在构建任何涉及多个组件的非复杂系统时,迟早会遇到需.
在虚拟线程中处理 Kafka 记录

Quarkus 中的虚拟线程支持不仅限于 REST 和 HTTP。 许多其他部分支持虚拟线程,例如 gRPC、计划任务和消息传递。 在这篇文章中,我们将了解如何在虚拟线程上处理 Kafka 记录,从而.
KIP-932:Kafka用作一个简单的队列
简单队列要求:无消息排序要求想使用Kafka作为一个简单的队列?有了新的KIP-932:引入共享(消费者)群体之前的Kafka消费者组Kafka常规消费者组非常适合可伸缩性和保持消息顺序两种选择。 保.
使用 Kafka 泳道处理不平衡流量
HubSpot 的客户使用工作流程来自动化其业务流程。工作流由触发器和操作集合组成,触发器告诉工作流何时“注册”要处理的记录,操作集合告诉工作流如何处理这些注册的记录。有数百万个活动工作流程,每天总共.
大模型 + 矢量数据库 + Kafka = 实时 GenAI
Apache Kafka 作为机器学习基础设施的关键任务且可扩展的实时数据结构为数千家企业提供服务。生成式人工智能 (GenAI) 与 ChatGPT 等大型语言模型 (LLM) 的发展改变了人们对智.
米其林、汉莎航空使用Kafka数据流的案例
售后销售和客户服务需要在正确的时间获得正确的信息来做出针对具体情况的决策。使用 Apache Kafka 进行数据流处理可实现真正的解耦、领域驱动设计以及跨实时和批处理系统的数据一致性。共同的业务目标.
2023年能源和公用事业数据流状况

这篇博文探讨了 2023 年能源和公用事业行业的数据流状态。公用事业基础设施、能源分配、客户服务和新业务模式的发展需要实时的端到端可视性、可靠且直观的B2B 和B2C 通信,以及与 5G 等先锋技术的.
2023年保险数据流的状况
这篇博文探讨了 2023 年保险行业的数据流状态。索赔处理、客户服务、远程信息处理和新业务模式的发展需要实时的端到端可见性、可靠且直观的B2B 和 B2C 通信,并与人工智能/机器学习等前沿技术集成以.
Netflix 使用Psyberg简化数据工程

在 Netflix,我们的会员和财务数据工程团队利用与计划、定价、会员生命周期和收入相关的各种数据来推动分析、为各种仪表板提供支持并做出基于数据的决策。Netflix 财务报告中的许多指标均由我们团队.
使用Spring Boot和Open Telemetry监控Kafka
在本文中,您将了解如何使用 Spring Boot 和 Open Telemetry 为 Kafka 生产者和消费者配置跟踪。我们将使用 Micrometer 库来发送轨迹,并使用 Jaeger 来存.
使用 Apache Kafka 和 OpenTelemetry 最大化可扩展性
OpenTelemetry Collector 和 Apache Kafka 之间的选择不是零和游戏。每个都有其独特的优势,甚至可以在某些架构中相互补充。OpenTelemetry Collector.
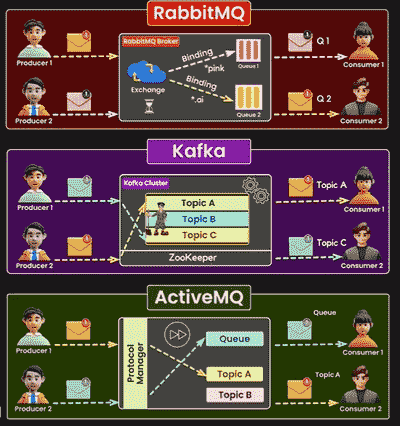
一张图比较:RabbitMQ、Kafka和ActiveMQ
Linux 6.6 ext4提高Kafka性能34%
有了这个补丁,测试在5066毫秒内完成,结果性能提高了34%。在Kafka版本2.6.2的测试场景中,使用2K的数据包大小,导致10%的性能提升。来自阿里Liu Song的测试:我在 32 核环境中进.
Kafka 事务的一次性语义
事务为发布到 Kafka 的一组消息提供原子性、一致性、隔离性和持久性 (ACID) 的保证。这意味着要么事务中的所有消息都将成功写入 Kafka,要么不会写入任何消息。在确保数据一致性和避免任何数据.
Spring Kafka教程指南大全

我们将指导您完成将 Spring Kafka 集成到微服务架构中的过程。Spring Kafka 是将 Apache Kafka 的强大功能与 Spring 生态系统的优雅和便利连接起来的桥梁。在您的.
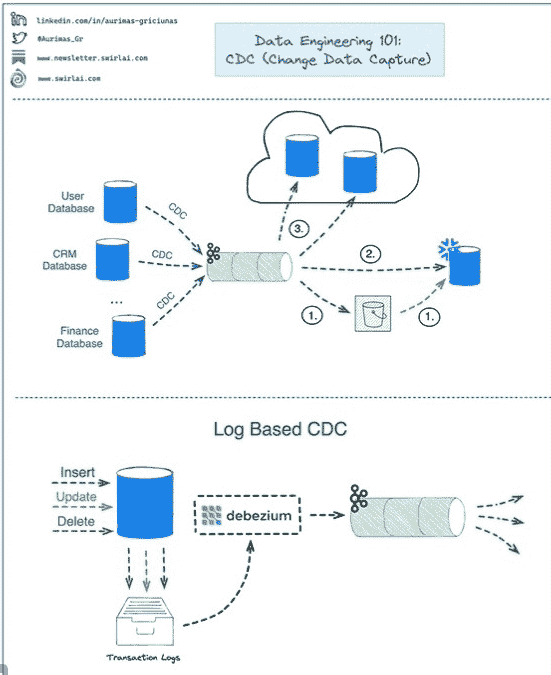
从数据库导出数据CDC的几种方式
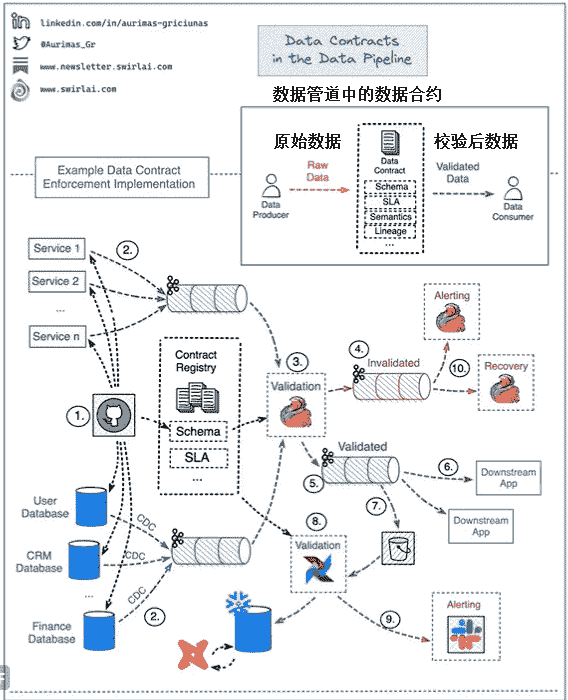
一张图解释数据合同如何实施
kcctl:Apache Kafka Connect的命令行客户端CLI
Kafka Connect 的现代且直观的命令行客户端。该项目是Kafka Connect的命令行客户端。依靠kubectl的习惯用法和语义,它允许您注册和检查连接器、删除它们、重新启动它们等。这说明.