在我们的领域模型实现中,我们成功地使用了许多 DDD 模式和原则。在这篇文章中,我将展示一个内聚机制的示例,该机制使我们能够解决产品的复杂性。
业务领域
在整个欧盟行业的天然气运输和天然气交易中,客户可以在一个时间段内分配天然气容量。例如,客户可以从 01/01/2024 到 31/12/2024 分配 1000 kWh 的吞吐量。
我们使用术语Customer Allocated Capacity,在我们无处不在的语言中定义这个概念。该分配具有许多属性,例如客户合同和网络点。但在这篇文章中,更有趣的属性是:
- 分配Time Slot时间周期
- 分配Throughout吞吐容量
该领域中的一个复杂用例是在两个客户之间分配分配的容量(第 33 条)。一位客户可以分配容量产能,然后将其转移给另一位客户。使此操作变得复杂的是,转移可能只针对一个子周期,并且可能会影响许多已分配的容量。
下图描述了使用事件风暴符号的用例的简化视图: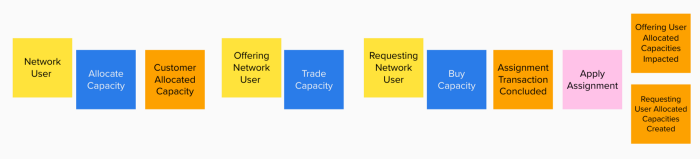
应用分配策略是本文中讨论的算法。让我们从描述我们用来与领域专家协作的不同领域建模技术开始。
领域建模
事件风暴符号是一种高级建模技术。它不太适合对预期解决方案的细节进行建模。更好的补充符号是 Gherkin 语言的表格表示。
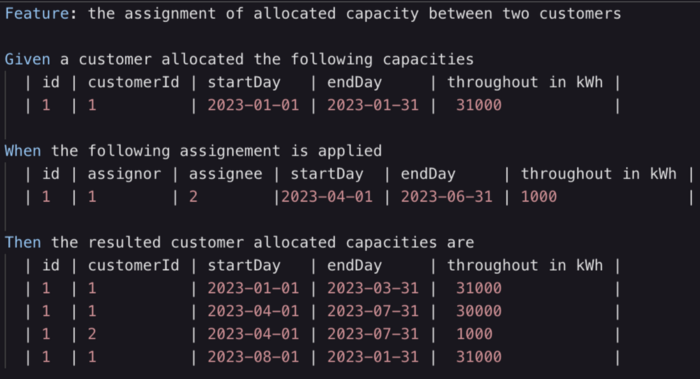
即使 Gherkin 是解决其他类型问题的良好协作工具,它也不是本案例的最佳工具。我们更愿意采用更直观的符号来简化对话。因此,我定义了一种简单的视觉语言,其中包含匿名周期和每个周期的给定数量。让我们用这个符号看看上面的例子:
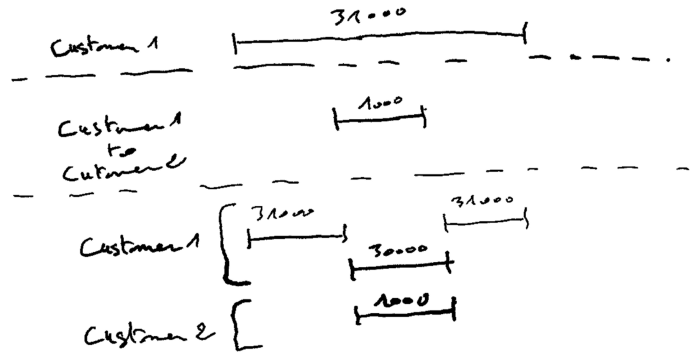
因此,我们在与领域专家的讨论中采用了一种半正式的语法来勾勒出一个有用的模型。该符号仅将重点放在领域问题的复杂部分。
表格形式的 Gherkin 符号和 excel 文件用于协作处理每小时的容量。
定义共享模型后,下一步是模型实现。
测试策略
模型实施完全由行为测试指导。我使用了经典的 Outside-In 双循环工作流程。我从 Gherkin 场景开始每次测试迭代,使用逐渐复杂的具体示例描述所需的行为。然后我尝试通过测试。当事情变得复杂且无法仅通过高级测试进行管理时,我开始添加更多低级测试以掌握复杂性。这种方法可以快速识别红色测试的来源。
除了 JUnit,我们还使用 Gherkin/Cucumber 作为测试工具,它有很多优点:
- Gherkin 也可以用作协作工具
- 不同的场景由 UL 定义
- 不同的场景是一个活的文档
- 团队中的任何人都可以轻松添加场景
- 如果我们有失败的场景,错误会很快得到修复
但是 Gherkin/Cucumber 也有很多缺点:
- 我们应该编写 Glue 代码。如果没有完善的战略,胶水代码就会变得一团糟。
- IDE 编辑器缺少高级支持。但这对于多插入符编辑 Guru 来说不是问题。
- 在测试用例组合爆炸的情况下,可扩展性有限。在我们的案例中,我们的产品经理的创造力使我们能够以更好的方式使用 excel 文件枚举案例。
为了处理胶水代码的复杂性,我们定义了一组规则和模式,使代码可预测且易于编写和理解。这可以作为单独帖子的主题。
现在让我们谈谈实现设计。
实施策略
通常,在第一次迭代中,我不会尝试设计 API 背后的细节。当我添加足够多的例子时,我让设计浮现出来。在某些时候,当我开始面对赋值算法中的算术运算时,我至少有两种设计选择。
第一个设计方案
第一个解决方案是使代码更具体并在域实体中定义操作:
val customerAllocations = customerAllocation.apply(assignement) |
或/和域服务:
val customerAllocations = service.applyAssignement(customerAllocations, assignement) |
算术运算使用 CustomerAllocatedCapacity 实体表示:
interface CustomerAllocatedCapacity { |
使用此解决方案,没有通用代码,并且接口更加明确。但是域实体中使用的字段是隐式的,代码更难理解,因为将与领域对象操作交织在一起。更糟糕的是,对分配的容量求和并不是一个领域概念。
二次设计方案
第二种选择是将专门的数学提取到一个单独的模块中。在一个日期范围内对数量的所有操作都由一个新的中央显式概念处理:QuantityOverDateRange 值对象。
interface QuantityOverDateRange { |
因此,要对域实体的日期范围和数量进行计算,我们应该:
- 将 CustomerAllocatedCapacity 实体转换为 QuantityOverDateRange 值对象
- 使用 QuantityOverDateRange 对象进行计算
- 从生成的 QuantityOverDateRange 对象创建新实体
例如,域实体变为:
class CustomerAllocatedCapacity( |
通过隔离算法逻辑并使其独立于我们的领域实体,代码变得更加通用,但也更加明确和清晰。而这正是 Eric Evans 在蓝皮书中所推荐的:
您可能会看到模型的一部分可以看作是专门的算法;分开它们。
这个解决方案基于四层。

上层是 CustomerAllocatedCapacity 领域模型。领域模型使用通用域模型 QuantityOverDateRange。DateRange 值对象是基于 Guava Range 泛型实现的。
QuantityOverDateRange 的主要属性是:日期范围、数量和组 ID(不同实例之间的关联 ID)。
interface QuantityOverDateRange { |
主要操作是:减法和加法。SubtractionResult 包含有关剩余范围和更改的信息。它们都用于在应用分配算法后创建客户分配的容量。
data class SubtractionResult( |
除了 QuantityOverDateRange 中的主要操作外,还有许多其他操作用于不同的用例。以下代码让我们了解了 QuantityOverDateRange API。
interface QuantityOverDateRange { |
客户分配容量分配的入口是QuantityOverDateRangeList。这个值对象的作用是封装一个QuantityOverDateRange的有序列表,并允许根据定义的顺序减去一个QuantityOverDateRange。
interface QuantityOverDateRangeList { |
因此,为了在域模型中实现分配算法,我们创建了一个 QuantityOverDateRangeList,将要受影响的 CustomerAllocatedCapacity 列表封装为 QuantityOverDateRange 列表。然后我们以 Assignment 实体作为参数调用减法操作。最后,我们将 SubtractionResult 转换为生成的 CustomerAllocatedCapacity 列表。
在我们总结之前,我想提一下我们的内聚机制中的另一个复杂操作。它是 QuantityOverDateRange 列表的总和。此操作未在分配用例中使用,但后来添加用于其他业务用例。
fun sum(values: List<QuantityOverDateRange>): List<QuantityOverDateRange> { |
为了重用,未提取 QuantityOverDateRange 值对象。最初的目标是让分配解决分配算法的复杂性。但是,创建的内聚机制具有更多功能令人羡慕。拥有 QuantityOverDateRange 的现有模型简化了以下功能的实施。
总结前面的代码,QuantityOverDateRange 包含以下四个操作:
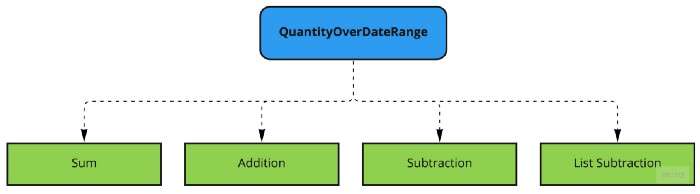
QuantityOverDateRangeList 包含单个操作:
如果没有体现领域驱动思维常识的熟练且积极进取的开发人员,就不可能实现这种内聚机制。
除了结对编程、mob/ensemble 编程、尝试各种避免浪费和技术卓越的采用之外,团队还有一定的热情。让我们看一个例子。
积极进取的团队
当我们的解决方案稳定后,在一次谈话中我谈到了为我们的场景语言定义一个可执行的可视化DSL的可能性。一个技术高超、积极进取的开发者实现了这个想法。他完善了我们语言的语法,使其正规化,然后他实现了解释器。他给我们做了一个演示。写一个抽象的测试,只用足够的数据来测试应用程序的复杂风险部分,这是令人惊讶的。这个POC的唯一真正限制是没有自动格式化。
(id , contrat , parent) |
语法由三个垂直块组成,用空行分开。它们是Given/When/Then块。在水平方向上,有两个部分:左边是日期范围的数量,右边是其他属性。第一行包含属性名称。下面几行,每一行都在Given和Then块中定义一个CustomerAllocatedCapacity的实例。When块包含一个赋值实体。
结论
层和抽象是强大的设计原语,DDD 使用它们来定义模式,以解决软件核心的复杂性。这篇文章讨论了 DDD 内聚机制的一个具体示例,该机制用于定义使代码更加人性化的抽象。
实施此类模式需要团队成熟,但管理企业战略产品中的规模复杂性至关重要。在这种情况下,极限编程、DDD、BDD 和 TDD 原则、实践和模式不是可选的。