Base思想与NoSQL
BASE思想:软状态和最终一致
- 假设一个用户转资产给另外一个用户,有两个动作,放入资产,拿走资产,假设这两个动作之间有一个Queue解耦。
- 有一个不确定性:资产已经被用户放入,但是另外一个用户还没拿到。这对用户来说有一个滞后。
- 两边用户都不知道资产何时到达,这种滞后是用户可以容忍,能最终一致确认的。
- 当状态最终一致时,通过事件通知。EDA
NoSQL两种风格
- 基于Dynamo :最终一致性,读到脏数据. 写数据时从来不会阻塞,将数据写到多个节点中,通过一致hashing,然后从这些节点读取数据,返回正确结果给用户。
- 基本基于BigTable :使用常用方式保持节点充分的一致性。比如同步复制
Amazon Dynamo实现
- 目标:我们如何建立一个基于数据中心的分布式哈希表?
- 追求最终一致性,牺牲部分一致性
- 注重:分区 复制和可用性。如果N中的1台发生故障,Dynamo立即写入到preference list中下一台,确保永远可写入。
- 开源 Voldemort
Amazon Dynamo
Google BigTable
- 建立在基于google文件系统上的数据库。
- 富数据模型,结构化存储
- 类似缓存系统,内存中保存的是最新,如果内存没有,到磁盘上数据集1 2 寻找。
- 更新内存数据和记录,如果数据写入硬盘之前崩溃,记录用来保存现场记录。
- 开源: HBase
从SQL过渡到NoSQL
- 要重新看待关系数据库的第二索引和join问题。
- NoSQL一般只有主键,没有第二索引(尽管有的支持),但是绝对不支持Join。
第二索引
- 使用两个表来替换第二索引。
- NoSQL引擎会将ScoreId集合看成是一个对象块。
向Join说No
- joins导致数据库切分sharding无法实施。(Score案例)
- Joinless如何实施?
在自己应用程序中使用join类似功能,比如通过二次查询。增加代码必要的复杂性才能进行水平伸缩。
NoSQL分类
- Key-value stores键值存储, 保存keys+BLOBs (二进制大对象Binary Large OBjects)
- Table-oriented 面向表, 主要有Google的BigTable和Cassandra.
- Document-oriented面向文本, 文本是一种类似XML文档,MongoDB 和 CouchDB
- Graph-oriented 面向图论. 如Neo4J.
Redis
- 关键点:超快Blazing fast ,IM data structure engine,支持五种,Key-value最简单。
- 只有Redis有事务机制
- 适合: 不支持第二索引,在可以控制的数据库大小情况下(放得下整个内存),快速改变数据,快速写数据。
- 案例:股票价格系统 分析,实时数据收集,联系等等。
- Redis Cluster可以进行复制和手工failover.
Redis案例一
- 跟踪用户总数和每天登陆系统的唯一用户数
- 用户总数是一个key-value,key是日期:
redis.incr(Time.now.utc.strftime('%Y-%m-%d'))
读取过去一星期的用户总数:
redis.mget *Array.new(7){|i| (Time.now.utc - (86400 * i)).strftime('%Y-%m-%d') }
- 唯一用户数使用Set 数据结构:
redis.sadd(Time.now.utc.strftime('%Y-%m-%d'), USER)
Redis案例二
- 跟踪股票买入者的请求。
- 关系数据库:

Redis特点
- 关系数据库能够过滤一个字段,而Redis限制你查询数据的方式。
- Key-value意味着只能关注Key,其他都放入value中。
- Key是:symbol,而不是symbol:date
- Value是:score的时间戳(amount/volume/more data 序列化数据作为BloB)
Redis数据特点

- redis.zadd('GOOG', Time.now.utc.to_i, "this would be our value..can be anything, I picked a string")
- redis.zadd('GOOG', Time.now.utc.to_i, "see above")
- redis.zadd('GOOG', Time.now.utc.to_i, "see above 2x")
- redis.zadd('GOOG', Time.now.utc.to_i, "It's OVER 9000!!")
- redis.zrangebyscore('GOOG', (time.now.utc - 5).to_i, time.now.utc.to_i)
Riak
- 关键点: 容错性Fault tolerance 失败恢复
- 内置全文本搜索
- 适合: 如果你希望有类似Cassandra-like (Dynamo-like)风格, 但是你不想处理器复杂性和膨胀性。单服务器有良好可伸缩性scalability, 可用性availability 和容错性 fault-tolerance, 采取是昂贵的多站点复制multi-site replication.
案例:销售点数据收集,工厂控制系统,那些不能允许几秒当机的场合。
Riak数据结构
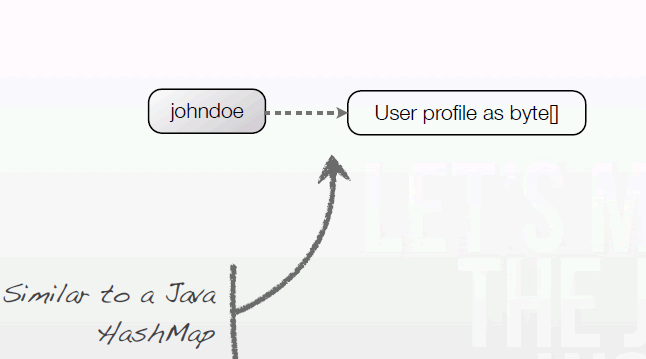
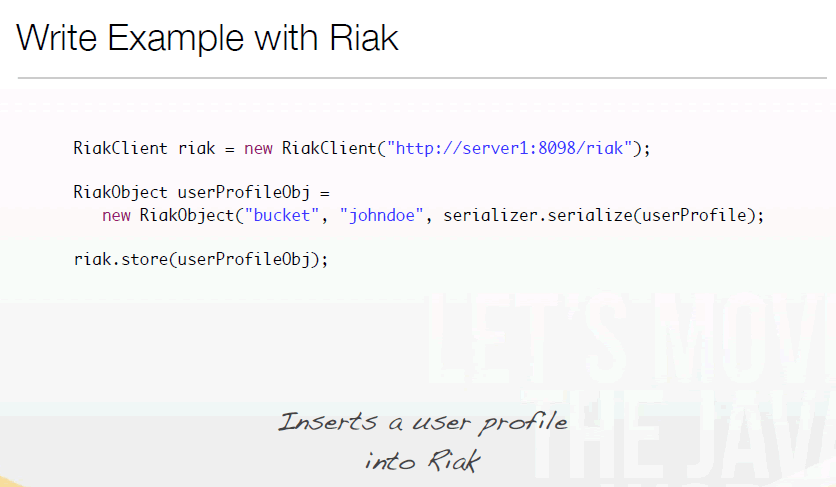
插入Profile
查询Profile

Voldemort产品介绍
- 应用在LinkedIn ,不是关系数据库。
- 是一种带有存储系统的内存缓存。这样就不需要单独缓存了。
- 云存储:使用Voldemort实现只读 read-only index,使用Hadoop作为数据文件。建立TB级别数据处理 。
更多伸缩性scalable讨论