Scalable系统设计之NoSQL- HBase和Cassandra
HBase
- 关键点: 十亿级别的行 X 百万级别的列 大容量
- 大表模型(高一致性)。
- Map/reduce with Hadoop 能够实时获得基于查询的优化性能的节约型网关适合:
- 适合:随机 实时的读写操作,高吞吐量写,随机访问大数据集。
- 案例: Facebook 消息数据库
列族特点:
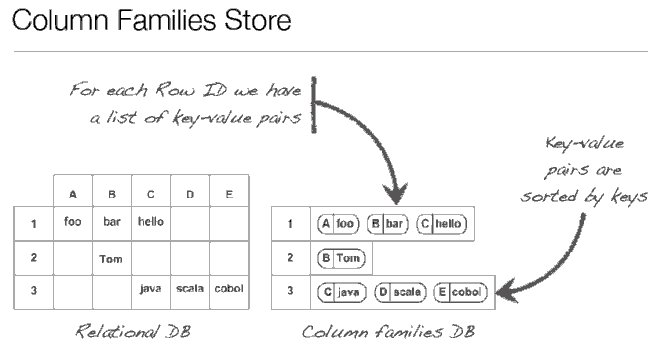
Hbase数据模型
- 三维数据Cell :
RowKey、ColumnKey、 Timestamp
- 按照排序后的RowKey shard成region
- 在每个region中,数据归组为列族。
- 每个列族中数据排序是:
Row Key、Column Key、 Timestamp
HBase案例

HBase的系统架构

HBase Region架构
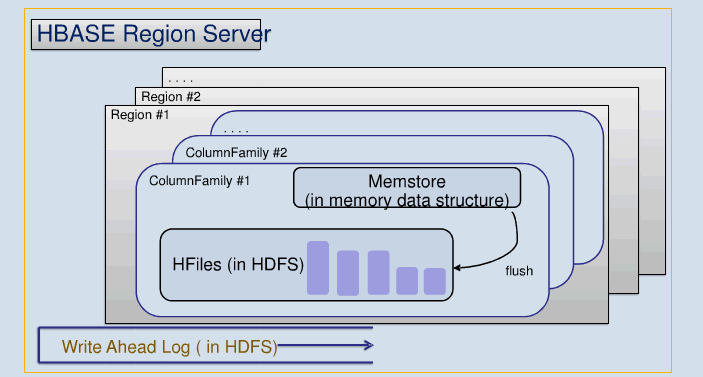
HBase读写模式
- 擅长随机读写
- 写方式:
1.顺序写,同步到日志log
2.更新内存memstore
- 读方式:
在memstore或持久的HFile中寻找,HFile是排好序有索引的。
HBase特点
- 自动失败恢复,1 actvie, rest standby
- 使用HDFS,可靠性好,可利用Map Reduce对HDFS数据进行分析处理
Cassandra
- 关键点: 继承BigTable的列结构、Dynamo的最终一致性。
- 按列查询 写快于读
Map/reduce possible with Apache Hadoop - 适合: 当写操作多于读操作 (如logging).
- 案例:: 银行Banking, 金融系统,写必须快于都的场合,实时的数据分析等.
Cassandra数据模型

Cassandra的数据模型案例
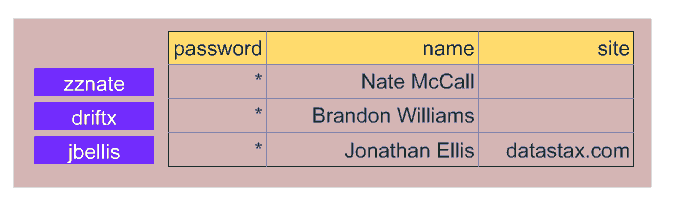
Cassandra JSON数据模型

Cassandra购物车案例
 Cassandra写操作:
Cassandra写操作:

Cassandra读操作

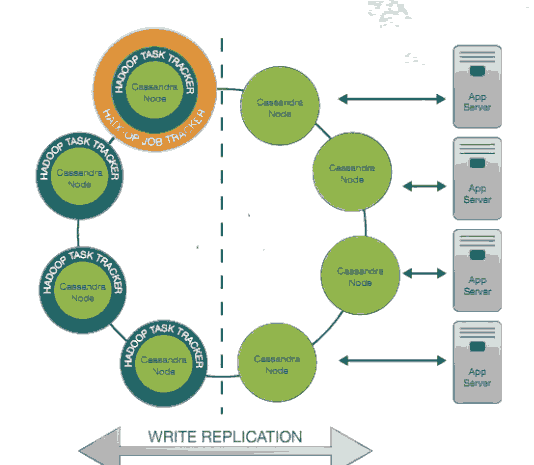
基于Cassandra的实时和大数据分析系统:
HBase和Cassandra 比较
- Hbase更加适合于数据仓库、大型数据的处理和分析(如进行Web页面的索引等)慢活。高一致性CP。
- Cassandra 则更适合于实时事务处理和提供交互型数据 ,快活,最终一致性AP。Cossip 完全对称
- 对比翻译文章:http://wangxu.me/blog/p/371 。
更多伸缩性scalable讨论