Spring Batch批处理
批处理顾名思义是批量处理大量数据,但是这个大量数据又不是特别大的大数据,比Hadoop等要轻量得多,适合企业单位人数薪资计算,财务系统月底一次性结算等常规数据批量处理。
Spring Batch是一个用于创建健壮的批处理应用程序的完整框架。您可以创建可重用的函数来处理大量数据或任务,通常称为批量处理。
如Spring Batch文档中所述,使用该框架的最常见方案如下:
•定期提交批处理
•并行处理作业的并发批处理
•分阶段,企业消息驱动处理
•大型并行批处理
•手动或故障后的计划重新启动
•依赖步骤的顺序处理(扩展到工作流程驱动的批处理)
•部分处理:跳过记录(例如,回滚时)
•整批事务:对于批量小或现有存储过程的情况/脚本
Spring Batch的特点有:
- 事务管理,让您专注于业务处理,实现批处理机制,你可以引入平台事务机制或其他事务管理器机制
- 基于块Chunk的处理,通过将一大段大量数据分成一段段小数据来处理,。
- 启动/停止/重新启动/跳过/重试功能,以处理过程的非交互式管理。
- 基于Web的管理界面(Spring Batch Admin),它提供了一个用于管理任务的API。
- 基于Spring框架,因此它包括所有配置选项,包括依赖注入。
- 符合JSR 352:Java平台的批处理应用程序。
- 基于数据库管理的批处理,可与Spring Cloud Task结合,适合分布式集群下处理。
- 能够进行多线程并行处理,分布式系统下并行处理,变成一种弹性Job分布式处理框架。
Spring批处理的基本单元是Job,你需要定义一个Job代表一次批处理工作,每个Job分很多步骤step,每个步骤里面有两种处理方式Tasklet(可重复执行的小任务)和Chunk(块),掌握Spring Batch主要是将这几个核心概念搞清楚。
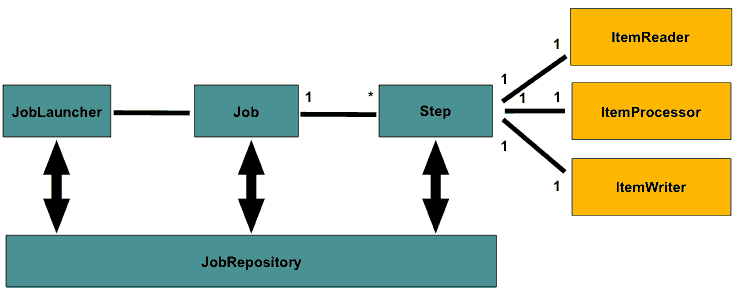
在SpringBoot架构下,我们只要做一个JobConfig组件作为JobLauncher,使用@Configuration配置,然后完成上图中Job和Step以及ItemReader,ItemProcessor和ItemWriter,后面这三个分别是存在一个步骤里,用于处理条目的输入读 、处理然后输出写出。至于图中JobRepository只要我们在Application.properties中配置上datasource,SpringBoot启动时会自动将batch需要的库表导入到数据库中。
下图是每个步骤内部的事务处理过程,在进行读入 处理和写出时,如果有任何一个步骤出错,将会事务回滚,也只有这三个步骤全部完成,才能提交事务机制,进而完成一个步骤。

下面我们看一个简单案例如何使用SpringBatch的,这个案例功能是从一个CSV文件中导入数据到数据库中。
首先导入pom.xml:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
这里使用MysSQL作为Job仓库,在Application.properties配置:
spring.batch.initialize-schema=always
spring.datasource.url=jdbc:mysql://localhost:3306/mytest
spring.datasource.username=banq
spring.datasource.password=XXX
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
配置了spring.batch.initialize-schema为always这样能自动启动时导入批处理需要的数据库表。
下面我们实现批处理的关键类@Configuration:
首先定义一个Job:
@Bean
public Job importUserJob() {
return jobBuilderFactory.get("importUserJob")
.incrementer(new RunIdIncrementer())
.flow(step1())
.end()
.build();
}
这个Job名称是importUserJob,其中使用了步骤step1:
@Bean
public Step step1() {
return stepBuilderFactory.get("step1").<User, User> chunk(3)
.reader(reader())
.processor(processor())
.writer(writer())
.build();
}
这个步骤step1中使用了chunk,分块读取数据处理后输出。下面是依次看看输入 处理和输出的方法:
@Bean
public FlatFileItemReader<User> reader(){
FlatFileItemReader<User> reader = new FlatFileItemReader<User>();
reader.setResource(new ClassPathResource("users.csv"));
reader.setLineMapper(new DefaultLineMapper<User>() {{
setLineTokenizer(new DelimitedLineTokenizer() {{
setNames(new String[] { "name" });
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper<User>() {{
setTargetType(User.class);
}});
}});
return reader;
}
这是输入,读取classpath下的uers.csv文件:
testdata1
testdata2
testdata3
一次读入三行,提取一行中数据作为User这个对象的name输入其中:
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id ;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
User是我们的一个实体数据,其中ID使用数据库自增,name由user.csv导入,User对应的数据表schema.sql是:
CREATE TABLE `user` (
`id` int(11) NOT NULL auto_increment,
`name` varchar(45) NOT NULL default '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
我们只要在pom.xml中导入JPA包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
并在application.properties中加入,就可以在SpringBoot启动时,自动使用datasource配置的数据库建立User表了。
spring.jpa.generate-ddl=true
下面我们回到批处理,前面定义了输入,下面依次是条目处理:
public class UserItemProcessor implements ItemProcessor<User, User> {
@Override
public User process(User user) throws Exception {
return user;
}
}
这个条目处理就是对每个User对象进行处理,这时User对象已经包含了从CSV读取的数据,如果希望再进行加工处理就在这里进行。
下面是条目输出:
@Bean
public JdbcBatchItemWriter<User> writer(){
JdbcBatchItemWriter<User> writer = new JdbcBatchItemWriter<User>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<User>());
writer.setSql("INSERT INTO user(name) VALUES (:name)");
writer.setDataSource(dataSource);
return writer;
}
每一行数据我们从CSV读出以后放入到User中,然后再插入数据表user保存。
至此,我们简单完成了一个批处理开发过程,具体代码见 Github
下面我们会展示更多Springbatch特性:
Spring scheduler调度计划 给批处理加上调用计划执行时间
Spring并行批处理 并行处理利用多线程或多流程并行处理
Spring批处理远程分块 实现主从计算的分布式批处理架构
Spring批处理分区 对数据进行分片sharding后分区用多线程或分布式系统处理
其他专题