大数据架构指南
面向银行和金融部门的Hadoop

Hadoop 3.0 中的新功能
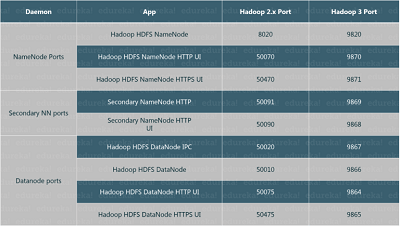
安装 Hadoop:设置单节点 Hadoop 集群

安装Hadoop有两种方式,即单节点和多节点。单节点集群意味着只有一个DataNode在一台机器上运行和设置所有的NameNode、DataNode、ResourceManager和NodeManag.
Hadoop YARN 架构

Hadoop YARN代表又一个资源管理器,随着 Hadoop 2.x 的出现,YARN 成为 Hadoop 生态系统的一部分,YARN 管理集群环境中的资源,在 Hadoop 2.x 之前我们没有任.
基于Hadoop的Apache Hudi 0.10 发布

Apache Hudi 0.10 发布,Hadoop关联http://www.linuxeden.com/a/96092使用 Apache Hudi 在 Uber 构建大规模交易数据湖:https:/.
关于Delta Lake的ACID事务机制简介

近年来,随着大数据利用用例的多样化,需要为分布式存储添加更多功能。这几年诞生了几款OSS存储层SW,可以原样使用HDFS等分布式存储和Apache Spark等分布式处理框架,为分布式存储添加新功能。.
Apache Pig:您需要了解的有关Hadoop编程语言的所有信息

Apache Hadoop 框架的 MapReduce 编程模型可以处理大量的大数据数据。然而,数据分析师并不总是理解这种范式。这就是将一个名为 Pig 的抽象添加到 Hadoop 的原因。 什么是A.
大数据面试问题

在这篇博文中,我们将看到一些在找工作时被问到的常见和重复的大数据面试问题。1.定义大数据?“大数据”是指规模超出典型数据库软件工具捕获、存储、管理和分析能力的数据集。这里的数据大小是主观的,因为它会随.
Pig面试问题

你能给我们举一些例子来说明 Hadoop 在实时环境中是如何使用的吗?假设我们有一个由 10 道选择题组成的考试,20 名学生参加了该考试。每个学生都会尝试每个问题。对于每个问题和每个答案选项,都会生.
热门 Splunk 管理面试问题及答案
MongoDB 面试题
您在创建MongoDB时想解决什么问题?我们曾经并且正在尝试构建我们作为开发人员一直想要的数据库。对于纯报告,SQL 和关系是很好的,但是在构建数据时总是需要一些不同的东西:使编码水平扩展的东西。Mo.
Hadoop 管理员面试问题

生产 Hadoop 部署支持哪些操作系统?主要支持的操作系统是 Linux。但是,通过一些额外的软件,Hadoop可以部署在 Windows 上。namenode的作用是什么?namenode 是Ha.
Hadoop集群面试题

Hadoop可以运行的三种模式是什么?Hadoop可以运行的三种模式是: 1. 独立(本地)模式 2. 伪分布式模式 3. 完全分布式模式 独立(本地)模式有哪些特点?在独立模式下,没有守护进程,一切.
Hadoop面试题之HDFS

Hadoop不是数据库,它是一种具有称为 HDFS 的文件系统的架构。数据存储在没有任何预定义容器的 HDFS 中。关系数据库将数据存储在预定义的容器中。 什么是大数据?大数据只不过是如此庞大而复杂的.
2022年学习数据科学的技巧:

2022年学习数据科学的技巧: Python R NumPy Pandas Flask Scikit-Learn TensorFlow Big Data Linear Algebra线性代数 Inte.
2022年面向专业人士的 10 大大数据分析工具

文字不足以说明数据的重要性以及将其转换为有助于改进决策的形式的需要。当您拥有合适的数据分析工具时,将原始数据转换为有助于管理层做出更好决策的形式并不是一项艰巨的任务。这就是为什么依靠良好的数据分析工具.
Hadoop大数据分布式处理系统简介
Hadoop 是一个用于存储数据和运行应用程序的框架。为任何类型的数据提供大容量存储是其主要功能之一。此外,它具有强大的处理能力,因此它能够一次处理多个并发任务。 Hadoop 模块 Hadoop 分.
Ifood如何使用Golang实现每天消耗超过10亿条 Kafka 消息
Ifood它是一家巴西食品科技公司,每天交付超过100 万个订单,并且每年增长约 110%。作为一家食品技术公司,该平台的流量时间主要是在午餐和晚餐时间,而且在周末会更高。 我们有一个微服务,用于存储.
Kappa架构取代Hadoop的Lambda架构成为主流 - Waehner

实时数据胜过慢速数据。几乎每个用例都是如此。然而,企业架构师使用 Lambda 架构构建新的基础架构,其中包括单独的批处理层和实时层。这篇博文探讨了为什么称为 Kappa 架构的单个实时管道更适合。迪.
Kafka-on-Pulsar 实现了偏移更好支持kafka - StreamNative
KoP(Kafka on Pulsar) 2.8.0 支持连续偏移,现在可以投入生产。默认情况下,Pulsar broker 只支持 Pulsar 协议。通过协议处理程序,Pulsar broker .
Honeycomb使用Apache Kafka为数据摄取提供高可用性缓冲管道

当您将遥测数据发送到 Honeycomb 时,Honeycomb 的基础架构需要先缓冲您的数据,然后再在我们的“检索器”列式存储数据库中进行处理。在 Honeycomb 的整个存在过程中,我们一直使用.
PostgreSQL与Elasticsearch和PGSync的实时数据集成 -Tolu
PGSync是一个变更数据捕获工具,用于将数据从Postgres转移到Elasticsearch。它允许你保留Postgres作为你的真实来源,并在Elasticsearch中公开结构化的非规范化文档.
如何使用传统数据库思维进行实时数据流分析? – thenewstack
大多数流数据技术需要开发人员的思维方式不同于使用传统关系数据库的思维方式。但是现在,专注于时间序列数据库的初创公司Deephaven Data Labs发布了Deephaven Community C.
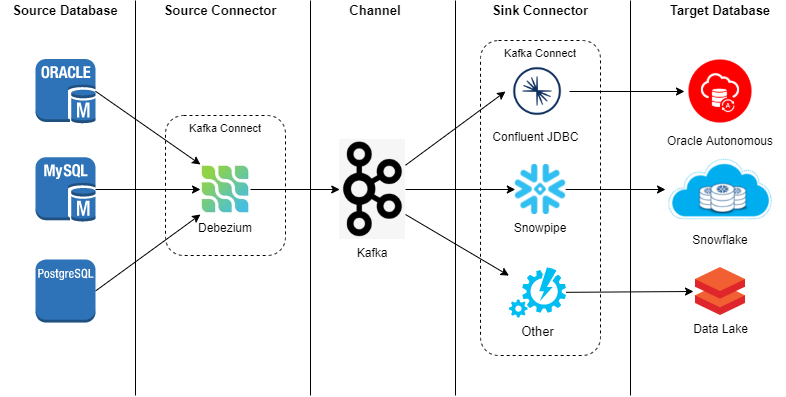
构建企业CDC数据湖解决方案 -DZone
Airbnb 如何建造“Wall框架”来防止数据错误?

通过广泛的数据质量、准确性和异常检查获得对数据的信任。Airbnb 已经开始了一个大规模的项目,以确保整个公司的数据可信。为了使员工能够更快地利用数据做出决策并为业务指标监控提供更好的支持,我们引入了.
大数据处理与数据工程Lambda架构简介
我们生活在一个技术时代,大数据、物联网、机器学习都已成为不可避免的现实。在当今世界,决策过程依赖于可以跨越各种数据源(例如社交媒体、日志文件、传感器数据等)的数据。虽然数据的异构性增加了多方面,但随之.
构建数据平台的快速工具指南 - Monte
下面我们分享“基本”数据平台的样子,并列出每个空间中的一些热门工具:数据摄取 与几乎所有现代数据平台的情况一样,需要将数据从一个系统摄取到另一个系统。随着数据基础设施变得越来越复杂,数据团队面临着从各.
Spring Boot调度任务源码与教程 - Thanh
调度是指在特定时间或特定时间间隔后执行任务,以带来减少时间、减少资源、最大化吞吐量的好处。调度的诞生是为了处理诸如收集每日报告、每月报告或在一段时间后处理数据之类的任务。Spring 提供了一组大部分.
推特大规模应用的流处理框架:Apache Heron
Apache Heron是实时、分布式、容错的流处理引擎。自 2014 年以来,Heron 为 Twitter 的各种用例提供了所有实时分析的支持。事件报告下降了一个数量级,证明了经过验证的可靠性.
高效实现大数据流式处理大型API响应的注意事项 - simonwillison
过去,大多数 Web 工程师会很快否定 API 端点的想法,即流式输出无限数量的行,他们认为应尽快处理 HTTP 请求!处理请求所花费的时间超过几秒钟都是一个危险信号,现在应该重新考虑某些事情。Web.