大数据架构指南
Honeycomb使用Apache Kafka为数据摄取提供高可用性缓冲管道

当您将遥测数据发送到 Honeycomb 时,Honeycomb 的基础架构需要先缓冲您的数据,然后再在我们的“检索器”列式存储数据库中进行处理。在 Honeycomb 的整个存在过程中,我们一直使用.
PostgreSQL与Elasticsearch和PGSync的实时数据集成 -Tolu

PGSync是一个变更数据捕获工具,用于将数据从Postgres转移到Elasticsearch。它允许你保留Postgres作为你的真实来源,并在Elasticsearch中公开结构化的非规范化文档.
如何使用传统数据库思维进行实时数据流分析? – thenewstack

大多数流数据技术需要开发人员的思维方式不同于使用传统关系数据库的思维方式。但是现在,专注于时间序列数据库的初创公司Deephaven Data Labs发布了Deephaven Community C.
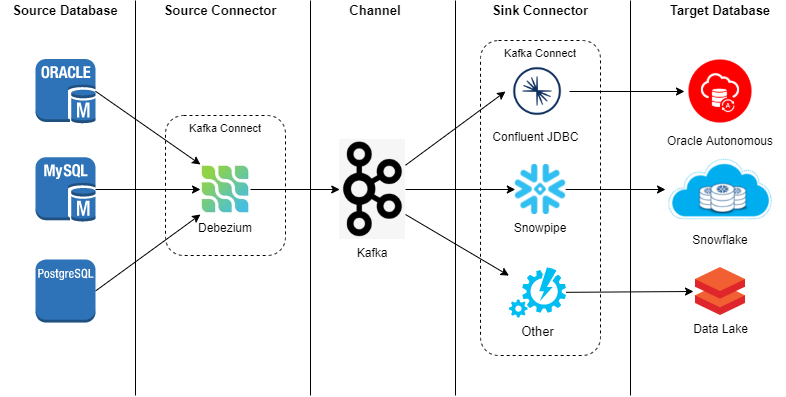
构建企业CDC数据湖解决方案 -DZone
Airbnb 如何建造“Wall框架”来防止数据错误?
通过广泛的数据质量、准确性和异常检查获得对数据的信任。Airbnb 已经开始了一个大规模的项目,以确保整个公司的数据可信。为了使员工能够更快地利用数据做出决策并为业务指标监控提供更好的支持,我们引入了.
大数据处理与数据工程Lambda架构简介

我们生活在一个技术时代,大数据、物联网、机器学习都已成为不可避免的现实。在当今世界,决策过程依赖于可以跨越各种数据源(例如社交媒体、日志文件、传感器数据等)的数据。虽然数据的异构性增加了多方面,但随之.
构建数据平台的快速工具指南 - Monte
下面我们分享“基本”数据平台的样子,并列出每个空间中的一些热门工具:数据摄取 与几乎所有现代数据平台的情况一样,需要将数据从一个系统摄取到另一个系统。随着数据基础设施变得越来越复杂,数据团队面临着从各.
Spring Boot调度任务源码与教程 - Thanh

调度是指在特定时间或特定时间间隔后执行任务,以带来减少时间、减少资源、最大化吞吐量的好处。调度的诞生是为了处理诸如收集每日报告、每月报告或在一段时间后处理数据之类的任务。Spring 提供了一组大部分.
推特大规模应用的流处理框架:Apache Heron

Apache Heron是实时、分布式、容错的流处理引擎。自 2014 年以来,Heron 为 Twitter 的各种用例提供了所有实时分析的支持。事件报告下降了一个数量级,证明了经过验证的可靠性.
高效实现大数据流式处理大型API响应的注意事项 - simonwillison

过去,大多数 Web 工程师会很快否定 API 端点的想法,即流式输出无限数量的行,他们认为应尽快处理 HTTP 请求!处理请求所花费的时间超过几秒钟都是一个危险信号,现在应该重新考虑某些事情。Web.
使用Redis和Lua缓存聚合数据以实现可扩展的微服务架构? - itnext

具有大量增长数据的基于微服务的扩展应用程序在有效交付聚合数据(如顶级列表)方面面临挑战。在本文中,我将向您展示如何使用 Redis 缓存聚合数据。而数据库将项目/行数据存储为“真实来源”并使用分片进行.
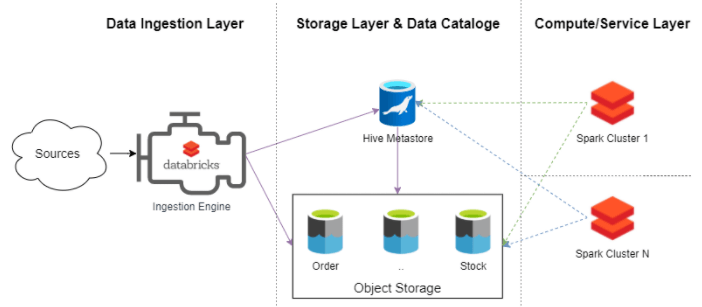
以Kafka事件中心+Spark为核心构建新一代数据湖平台 - DZone
JVM上高性能数据格式库包Apache Arrow入门和架构介绍 – Gkatziouras
ClickHouse数据库的起源
ClickHouse最初是Yandex Metrica中用于Web分析的解决方案,Metrica是一项用于分析网站流量的流行服务,目前在Google Analytics(分析)之后排名第二。2008年.
时序数据库QuestDB是如何实现每秒140万行的写入速度?
QuestDB是一个快速开源时间序列数据库,QuestDB是一个用于时间序列,事件和分析工作负载的开源数据库,主要关注性能(https://github.com/questdb/questdb)。 诞.