几个月前我一直在考虑撰写“什么是新的企业数据平台?” 在过去的几年中,我一直是新数据平台的数据解决方案架构师和产品负责人。我学到了很多东西,我想与社区分享我的经验。
当我们设计和构建数据平台时,我们致力于提供其他团队开发项目所需的能力和工具。我没有忘记数据,但我认为数据应该是一种服务,而不是一种产品。数据即服务是通过云数据平台实现。
拥有敏捷的云数据平台而不锁定供应商取决于:
- 使用开源技术作为平台的核心。这使我们能够将我们的平台转移到另一个云提供商。
- 为流式和批处理数据提供数据中心服务。
- 管道话自动处理数据:这让我们给我们的数据轻松地移动到不同的数据存储库。
- 数据服务层脱开 数据的持久化引擎。
数据模型(领域驱动设计)
数据平台需要全局数据模型定义。在我们看来,有一个糟糕的模型总比没有模型好。这是最初的决定之一(最重要的一个),但只要我们能在数据平台设计上工作,我们就不会认为它是一个障碍。这是一个应该涉及整个公司的战略决策。最重要的是一项长期决策, 在技术方面进行更改很容易,但更改全局数据模型需要数年和大量的努力。
我们相信url=https://www.jdon.com/tags/272]领域驱动设计[/url。多年来,我们一直在使用 DDD 方法。在我们看来,IT 公司有一个优势,因为从业务人员到开发人员,所有公司都参与其中,这是 DDD 成功的关键。在其他类型的公司中,需要更多的努力才能使所有人参与其中。
关于数据域的一些重要事项:
- 数据域有两种视图,生产者和消费者。通常,这些域是不同的,因为消费者的域是来自多个生产者域的数据的组合。
- 特定数据可以有一个主域和一个辅助域。
- 该数据域的组织也不是一成不变的。域被更改、合并、演化或移除。
数据摄取模式
新数据平台最有价值的资源是数据,同时也是最复杂的提供。上传数据有两种方式:
- Pull : 基于核心团队和集中管理,开发数据管道,将数据引入平台。一开始,这很有效,因为没有与其他团队的依赖关系,但最终,正如我 在上一篇文章中已经解释的那样,他们最终会陷入瓶颈。
- Push:在操作、架构和范式方面这是最好的方法,但它取决于其他团队。例如,分销团队需要分析销售数据。拥有销售数据需要销售团队将数据推送到数据平台。我们可能会等待销售数据很长时间,因为销售团队没有时间去做,或者这不是他的首要任务。
我们认为,提供“Pull ”服务的最佳方法是开发自动数据摄取引擎服务。
什么是数据摄取引擎服务?
这是一个自助服务平台,无需代码即可创建ETL流程和流式流程,只需要SQL语句和映射。
目标是提供多种风格来涵盖所有情况:
- 允许团队自行将数据推送到交换区。
- 提供一个核心集中的团队,为非技术团队上传数据。
- 提供自助服务平台,简化技术团队的数据摄取。
- 更改数据捕获。
- 事件。
- 图像、文件等...
我们必须提供所有工具和标准流程(摄取、数据质量等),以允许生产者将他们的数据自动推送到数据平台。此自助服务可以是 Web 门户或 GitOps 解决方案。
事件驱动的微服务架构是应用基于流的“推送策略”的最佳场景之一。这些架构遵循发布-订阅通信模式,通常基于持久消息传递系统,例如 Apache Kafka。
这种模式提供了可扩展和松散耦合的架构:
- 发布者向主题发送一次消息。
- 所有注册此主题的订阅者都会收到此消息。事件产生一次,消费多次。
- 发布者和订阅者操作可以彼此独立运行。它们之间没有依赖关系。
- 这些持久主题通常具有基于时间或大小的限制。在出现错误场景的情况下,重新处理更加复杂。
- 重新发送历史数据的过程。
- 海量场景的异步数据质量API。
数据湖
它是分析、机器学习环境和存储原始数据的自然选择。数据湖是一个数据存储库,通常基于对象存储,它允许我们存储:
- 来自关系数据库的结构化数据。
- 来自 NoSQL 或其他来源(CSV、XML、JSON)的半结构化数据。
- 非结构化数据和二进制数据(文档,视频,图像)。
- 目前,云存储服务已经有了很大的改进,并提供了不同的服务质量,使我们能够:
- 为热数据提供高性能和低延迟。
- 以低成本拥有大存储容量和更高的延迟,用于冷热数据。
- 提供对数据的只读访问。它允许数据湖成为所有用户的数据来源和单一数据存储库。
- 结构化数据和半结构化数据以列格式存储。有很多存储数据的选项,但一个很好的选择是使用Delta Lake,我们将在下一节中对其进行描述。
- 数据按业务数据域分区存储,分布在多个对象存储中。
- 提供Hive Metastore服务,以通过使用外部表提供spark-SQL访问。这允许拥有数据的单个图像并将用户从数据的物理位置中抽象出来。
Spark-SQL 和 Hive Metastore
Spark SQL 为我们提供了一个分布式查询引擎,以更优化的方式使用我们的结构化和半结构化数据,并使用类似于数据目录的 Hive Metastore。使用 SQL,我们可以从以下位置查询数据:
- 数据帧和数据集 API。
- 外部工具,如Databricks Notebooks。这是一个用户友好的工具,可促进非技术用户的数据消费。
数据湖即服务
如果我们把到目前为止描述的所有部分放在一起,我们可以设计和构建一个数据湖平台:
- 该数据摄取引擎 负责摄取的数据,创建和管理在蜂巢Metastore的元数据。
- Data Lake的核心由对象存储层和 Hive Metastore 组成。这是允许我们将计算层作为服务提供的两个主要组件。
- 计算层由 集成到数据湖中的几个Spark集群组成。这些集群允许使用 spark 作业、SQL Analytics 或 Databrick Notebooks 访问这些数据。
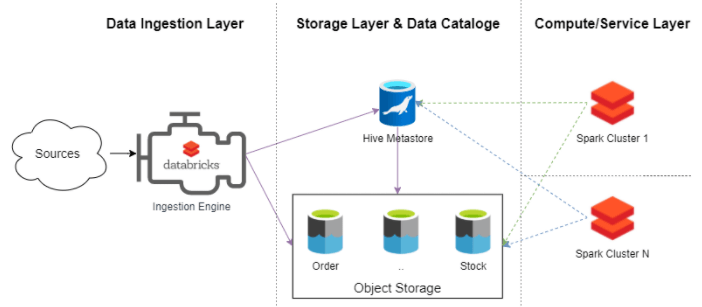
在我们看来,提供这种动态且可扩展的计算/服务层的能力使我们能够提供数据湖平台即服务,否则我们将拥有与传统本地数据湖更相似的东西。我们可以创建一个 24x7 的永久集群,或者我们可以创建临时集群来运行我们的工作。Spark 集群是这个计算和服务层的核心。它是我们将在 Data Lake 平台中提供的服务目录的最小公约数。
Delta Lake作用
它是一个开源层,提供ACID功能并确保读者永远不会看到不一致的数据。Data Pipelines 可以在不影响正在运行的 spark 进程的情况下刷新数据。
还有其他重要的功能,例如:
- Schema on-write:它在写入数据时强制执行模式检查,当检测到模式不匹配时作业失败。
- Schema Evolution:它支持兼容方案演变的模式演变,例如添加新列。
- 时间旅行:数据版本控制是机器学习用例中的一个重要功能。允许将数据作为代码进行管理。作为代码存储库,用户对数据进行版本控制,对数据集的每次更改都会在其整个生命周期中生成新版本的数据。
- Merge:支持合并、更新和删除操作,以实现复杂的摄取场景。
数据湖的演变
几年前,传统数据湖、数据仓库和数据中心之间的区别是概念性的,也是技术性的。
基于 Hadoop、Spark、Parquet、Hive 等的数据湖技术有很多局限性。目前,Delta Lake和其他选项(例如Apache Hudi)为Data Lake生态系统增加了新的惊人功能。这些特性与解耦体系结构(计算和存储层)、无服务器以及其他新特性(如Databricks的SQL分析或Delta引擎)结合在一起,展现了新一代的数据湖平台。
Databricks将这一代命名为Lake House。在我们看来,目前这一新一代的成熟度允许Data Lakes提供两个新角色:
- Data Hub
- 数据仓库用于特定和简化场景:数据仓库的能力提升了很多,但此时仍需要高水平的技术知识来分发数据并实现与其他产品如Snowflake、Big query或Oracle Autonomous Data Warehouse相同的性能。
结论
结合Kafka等事件中心,新一代数据湖是我们数据平台核心的不错选择。 它是一项成熟的技术,主要基于开源,具有极具竞争力的性价比,不断演进,我们可以在所有云供应商中提供。