机器学习教程
Meta:通过机器学习和因果推理改进 Instagram 通知管理

该博客讨论了用户体验和通知 CTR 模型之间的权衡,以及通知管理系统采用因果推理模型。在 Instagram 上,通知在为 Instagram 和我们的用户之间提供有效的沟通渠道方面发挥着重要作用。随.
Uber 如何使用 ML 和线性规划优化推送通知的时间
内部通知是在线商务的重要潜在客户。优步写了问题陈述的复杂性以及它如何采用线性程序(线性优化)来实现最佳结果。推送通知是 Uber Eats 优食客户发现新餐厅、有价值的促销活动、杂货和酒类等新产品以及.
Expedia使用无监督学习对客户反馈进行分类

Expedia 撰写了关于其使用无监督学习对客户反馈进行分类的方法。我的一部分想知道,云提供商可以开箱即用地提供这些解决方案,难道不应该是一个已解决的问题吗?在Expedia Group ,我们努力为.
谷歌宣布一个用Rust编写的新操作系统:KataOS
这是为嵌入式硬件构建的可验证的安全系统,Google Research 团队针对运行 ML 应用程序的嵌入式设备进行了优化:现在已经为这个安全操作系统 KataOS 开源了几个组件,并与 Antmic.
Snap:如何加速推荐系统的特征工程

开发人员提高特征工程的速度是许多公司快速迭代和构建 ML 应用程序的重点。沿着Airbnb 的 Zipline和 Uber 的Michelangelo Palette的路线,Snap 撰写了关于其内部.
Claimforce为何使用湖仓统一数据湖和数据仓库?

在 Claimforce,我们最初的大数据方法是一个两层架构,包括 Amazon S3 中的数据湖阶段和 Amazon Redshift 中的数据仓库阶段(此处概述)。随着时间的推移,我们意识到拥有两.
神经网络是用类比方式 "思考 "吗? - qualcomm

人只有两种思考方式:因果性和相关性。因果性遵循逻辑形式,属于分析分解的还原主义,遵循第一性原理,这是数学课上练习的;相关性有比喻 形象对比 打比方等形象思考,语文课上练习的。原文转译如下:认知语言学家.
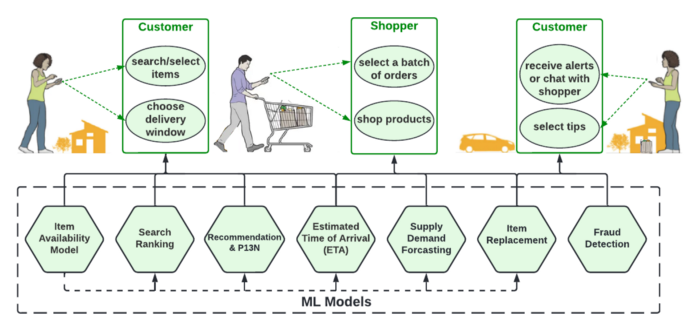
经验教训:Instacart 的实时机器学习之旅 - shu
数据科学面试中8个实用技巧
帮助您在下一次数据科学和/或机器学习面试中取得成功的实用技巧:1.先了解问题在某些情况下,您可能会被要求说出您将如何使用机器学习解决特定问题。大多数应用数据科学家和机器学习工程师角色的面试通常都是这种.
使用人工智能从大脑活动中解码语音 - Meta

Meta AI 研究人员表示,他们开发了一种 AI 模型,无需手术即可帮助从人的大脑活动中解码语音。Meta 表示,其工作旨在帮助科学家加速使用人工智能来更好地了解大脑。这是朝着可以从非侵入性脑记录中.
Instacart如何使用机器学习帮助人们装满购物车?
对于像 Instacart 这样的电子商务平台,搜索是一个重要的工具,它可以帮助人们找到他们想要的产品,即使他们不确定自己在寻找什么,也能让他们轻松购物。在用户开始输入时自动完成用户的查询是提高搜索体.
纽约时报如何使用机器学习使其付费墙更智能
当《纽约时报》付费专区推出时,所有用户的计量表数都是一样的。从那时起,《纽约时报》已经转型为一家数据驱动的数字公司,其付费墙现在成功地使用了一种名为 Dynamic Meter 的因果机器学习模型来设.
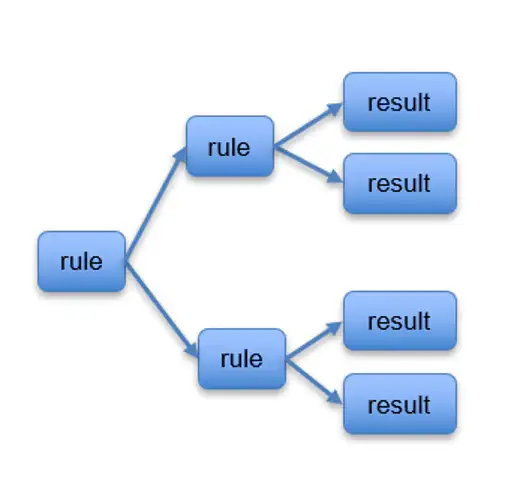
规则引擎与机器学习比较与结合
Endeavour的机器学习平台

Endeavor是一家全球体育和娱乐公司,处于所有文化形式的交汇点。无论你是观看终极格斗锦标赛,还是参加纽约时装周,还是在超级碗比赛中体验优质服务,或是欣赏最新的好莱坞大片,在你的体验背后都有Ende.
Etsy使用交错新算法实现更快的ML实验

在线实验在产品开发中起着核心作用。Etsy 写了它如何使用交错实验测试来捕捉用户在个人层面的偏好。在Etsy,我们的产品和机器学习 (ML) 团队一直在努力改善我们买家和卖家的体验。他们产生的创新必须.
GitHub - h33p/ofps: 用Rust编写的计算机视觉项目

OFPS 是一个通用的光流处理库,OFPS Suite 是一个展示其功能的配套应用程序。点击标题,这是一个用于处理各种运动矢量的框架,以期检测运动或提取相机参数。这是一个非常庞大的项目,包含插件系统、.
机器学习与传统软件开发的冲突与融合 - alepiad
在过去的几年里,我一直在用机器学习和数据科学的想法来颠覆传统的软件公司,这些想法直接来自我团队的核心研究。我发现大多数问题来自三个关键领域。大部分障碍可以归为以下三类之一: 语言 开发过程 预期结果 .
神经网络之所以强大的两个原因 - tunguz

让神经网络如此强大的两个最重要的特性是:可微分性Differentiability组合性Compositionality可微分性使得使用梯度下降进行优化成为可能,梯度下降比大多数其他数字优化方法快几个.
lingua: 最准确的Java和JVM自然语言检测库
最准确的Java和JVM自然语言检测库,适用于长文本和短文本语言检测通常作为大型机器学习框架或自然语言处理应用程序的一部分来完成。如果您不需要这些系统的完整功能或不想了解这些系统的原理,那么一个小型灵.
罗列50多种开源MLOps工具测试结果的网站
过去几周我研究了最流行的开源 MLOps 工具,我想与您分享结果。我创建了一个网站 ( https://mymlops.com/ ),列出了这些工具,解释了何时使用它们以及需要注意的陷阱。您可以根据我.
wink-nlp:在浏览器中运行的JavaScript和NodeJS的自然语言处理
winkNLP是一个用于自然语言处理(NLP)的JavaScript库。专为使NLP解决方案的开发更容易和更快而设计,winkNLP为性能和准确性的正确平衡进行了优化。NLP被用于各种任务,包括文本分.
ifelse过度设计:人工智能建模中的最大错误 - svpino

人们喜欢一开始就跳入他们最喜欢的模型,而没有先提出该模型的基准baseline。这里有一个真实的故事和一些想法:一个团队花了一个月的时间试验了三种不同的模型来解决一个二进制分类问题。 - k-Near.
clubhouse使用机器学习实现人与聊天房间的匹配
早期,clubhouse开用简单的启发式方法对走廊上的房间进行排名,根据你有多少朋友在其中,或者房间的主题与你选择的主题有多密切等等来挑选和推荐房间。后来,我们已经转向使用机器学习模型,它可以对走廊上.
Meta开源其类似GPT-3的语言模型 - Reddit

Facebook 刚刚发布了与 GPT-3 相当的语言模型 Open Pretrained Transformer (OPT-175B)。优点是:模型大小比GPT-3小,只有125M参数的模型,可供任.
pyscript:可在浏览器HTML中使用Python
Anaconda的联合创始人兼CEO Peter Wong在PyCon US上分享了一个名为PyScript的新开源项目。这个项目的目标是在HTML文件中使用Python!这对于一般的Python开发.
treequeues: 为pytree对象提供高性能的队列

如果您使用 jax 并且需要在进程之间传递一些 pytree,我可能会为您提供一些东西:)我开发了一个“树队列”。它是为 pytree 的嵌套数组创建的队列。传输速度比普通队列快10倍。这是通过利用共.
即将推出的GPT-4与GPT-3比较 - Alberto

GPT-4 发布的日子越来越近了。GPT-3 于大约两年前的 2020 年 5 月宣布。它是在 GPT-2 发布一年后发布的——这也是在原始 GPT 论文发表一年后发布的。鉴于我们从 OpenAI 和.
为什么扩散diffution模型如此强大? - Reddit
可以在这里看到200行代码,但它背后的数学是如此简单,这算法智能且简单,但它的生成结果似乎比 GAN 更令人难以置信,而且它的速度很快,模型大小也不算大。案例: https://openai.com/.
HuggingFace在NLP和计算机视觉中的应用 - Reddit
你想做语义分割吗?查看https://huggingface.co/blog/fine-tune-segformer。图像分类?https://huggingface.co/blog/fine-tun.
最大似然估计可能因 "流形过度拟合 "而失败
今天发表的这篇论文似乎提出了一个大胆的主张,即最大似然估计在深度生成模型中不是一个很好的训练目标。流形假设是:观察到的高维数据聚集在低维流形周围,但最大似然方法(例如VAE、归一化流)学习的是高维密度.