消息队列教程
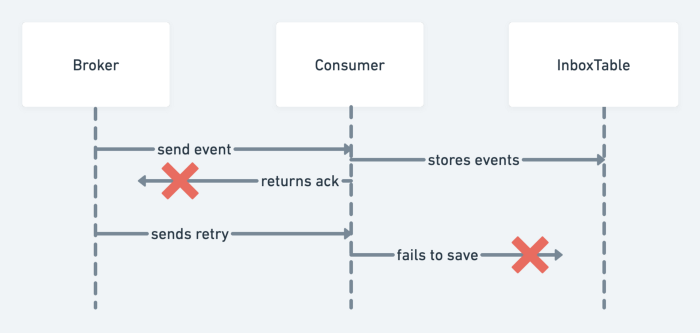
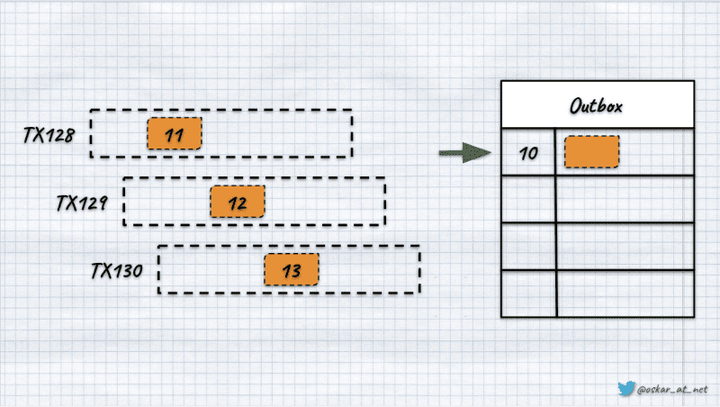
事件模式:使用幂等消费者(收件箱)检测重复消息
2023年流Stream预测 - tspann

Apache Pulsar、Apache Flink SQL as a Service、Apache Pinot等流Stream架构技术预测:Apache Pulsar2023年,Pulsar的新版本.
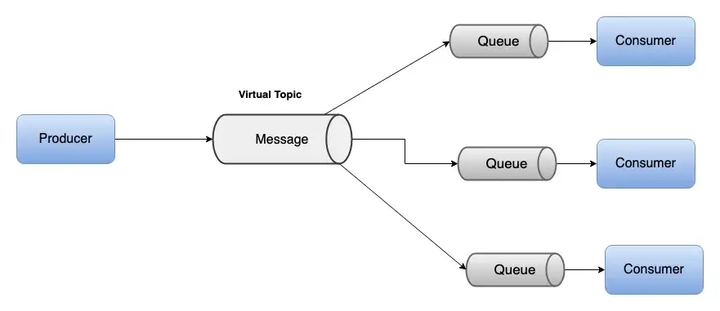
ActiveMQ中虚拟目的地
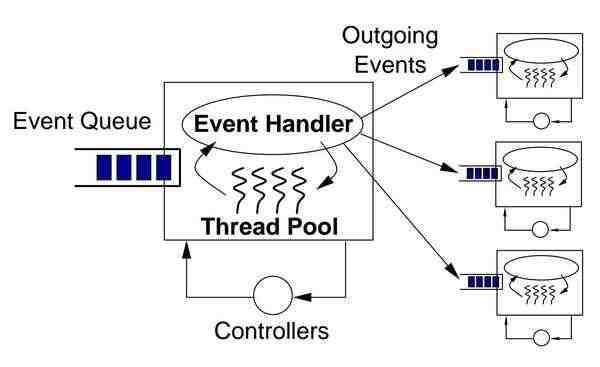
基于Spring Integration和Apache Camel的SEDA
亚马逊的分布式计算宣言 - werner

在将近25年之后,我将完整地发表《分布式计算宣言》,这是亚马逊早期的一份内部文档,它改变了我们电子商务平台的架构。亚马逊的系统架构的一个非常简短的历史:在我们深入了解亚马逊的架构历史之前,先了解一下我.
Postgres 序列问题如何影响您的消息传递保证 ?
Knative Eventing 的三种实现方法 | Mete
Dendrite项目从Kafka迁移到NATS

Matrix 是建立在分布式数据结构之上的实时通信联合协议,Dendrite是一个按照微服务架构建立的Matrix家庭服务器的实现。我们使用 Kafka 作为在微服务组件之间分发事件和异步任务的一种手.
事件驱动API架构的五个协议

在这篇文章中,我们将讨论 5 种常见的事件驱动方法——WebSockets、WebHooks、REST Hooks、Pub-Sub和Server Sent Events。我们将定义它们的本质和作用,以.
Timestone:Netflix 的高吞吐量、低延迟优先队列系统

Timestone:Netflix 的高吞吐量、低延迟优先队列系统,内置支持不可并行化的工作负载。Timestone 是我们内部构建的高吞吐量、低延迟优先级排队系统,用于支持我们的媒体编码平台Cosm.
Apache Camel 路由简介
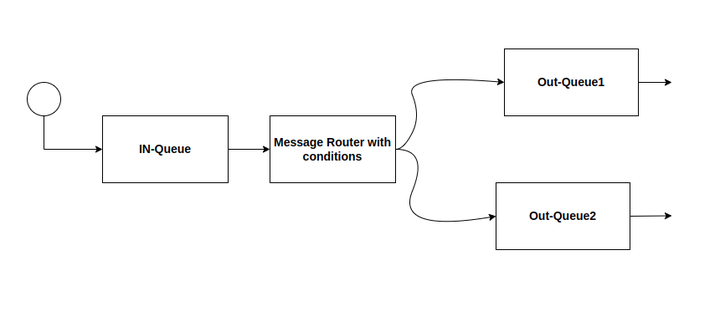
消息队列和消息总线有什么区别?

消息队列消息队列是从一个应用程序接收一堆消息,并在先进先出(FIFO)的基础上将它们传递给一个或多个其他应用程序。消息队列由发布者和消费者组成。我们所说的发布者将消息留给队列。消费者也接收它们并进行处.
Apache Kafka重试和维护重试事件的顺序

RabbitMQ的脑裂踩坑 - ryanrodemoyer
我的手表嗡嗡作响,在黎明前的昏迷中,我无法辨认这是警报还是电话。时间是凌晨 4 点 45 分:我们最大的客户报告说他们的请求需要两个多小时才能返回结果。我们认为这是因为我们的RabbitMQ消息系统。.
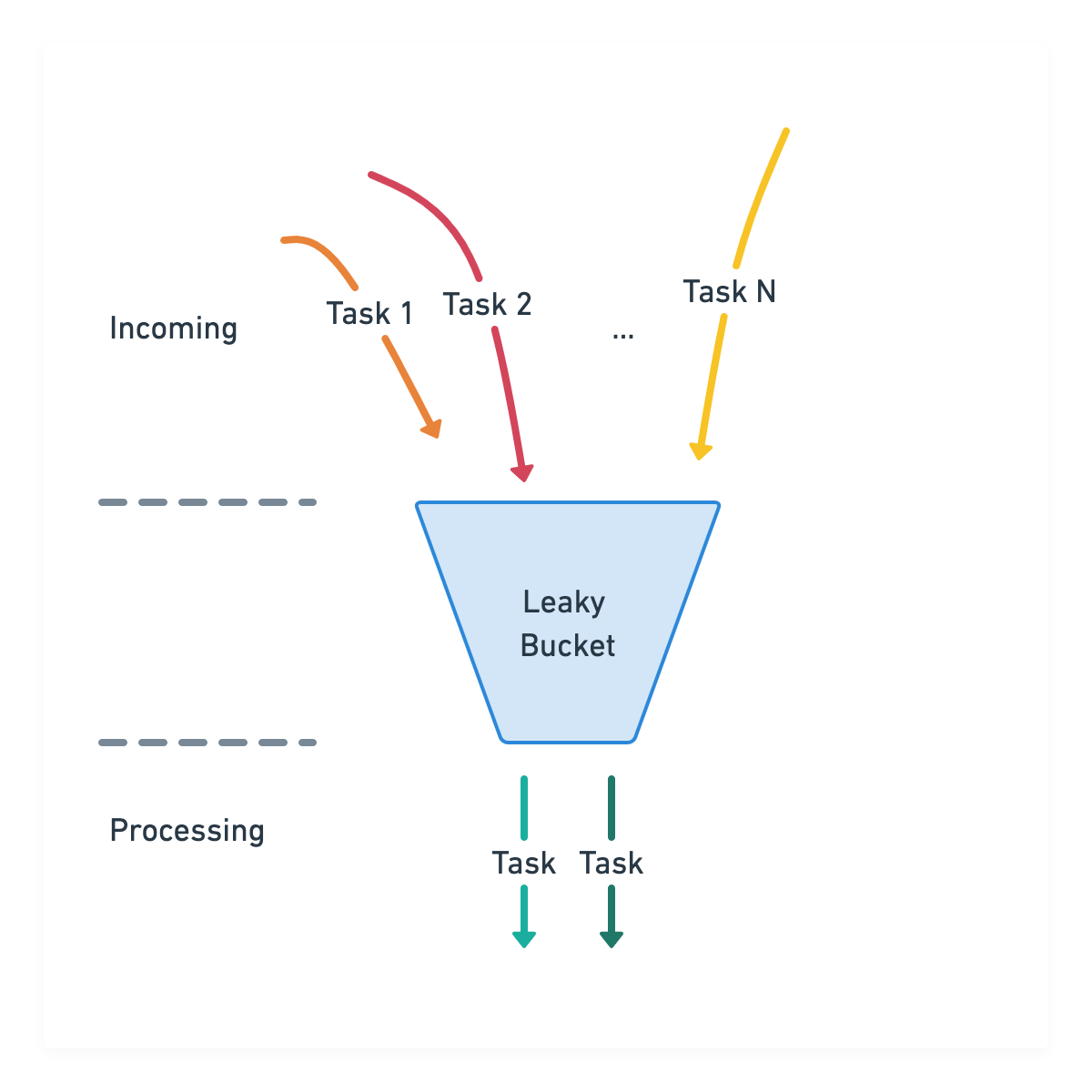
Golang漏桶算法限速 - ITNEXT
watermill:构建事件驱动的Go库
Watermill 是一个用于高效处理消息流的 Go 库。它旨在构建事件驱动的应用程序、启用事件溯源、基于消息的 RPC、sagas 以及基本上你想到的任何其他东西。您可以使用传统的 pub/sub .
Redpanda:用C++重写的Kafka

Redpanda 是对 Kafka 的 C++ 重写,提供与 Kafka API 的 100% 兼容性。Redpanda 不需要 Zookeeper 或 JVM,因此在生产中操作起来不太复杂。因此,更.
在Spring中优雅关闭Pulsar消息消费者?
这个github创建的示例应用程序以演示如何使用 Spring Boot 在 Java 中正确实现 Apache Pulsar 队列消费者的正常关闭。队列消费者实施强大的优雅关闭策略: 我们是立即停止.
消息队列与消息代理有什么区别?

在这篇文章中,我们将解释消息队列与消息代理之间的区别,它们的使用情况,以及我们是否可以把它们一起作为软件应用程序之间的通信手段。什么是消息队列?队列是一种数据结构,先进入队列的信息也先被传送。这个编程.
事件驱动架构EDA中的组件
最简单技术架构是面向批处理和集中式单体系统;金融等行业,尤其是贸易和证券交易所等这些细分市场需要由实时信息驱动,EDA由此诞生,然后是物联网 (IoT)、社交、开源、PaaS/devops 和大数.
treequeues: 为pytree对象提供高性能的队列

如果您使用 jax 并且需要在进程之间传递一些 pytree,我可能会为您提供一些东西:)我开发了一个“树队列”。它是为 pytree 的嵌套数组创建的队列。传输速度比普通队列快10倍。这是通过利用共.
使用OpenTelemetry和System.Diagnostics.Metrics构建NServiceBus指标

几个月前,System.Diagnostics.DiagnosticSource 6.0版的发布给这个库带来了全新的东西--对OpenTelemetry Metrics的支持。由于这个包是从.NET .
奈飞Netflix如何同步数以亿计的设备?
Netflix 是一种在线视频流媒体服务,以疯狂的规模运行,2.2 亿活跃用户从多个设备访问他们的 Netflix 帐户,因此 Netflix工程师必须确保用户登录的所有不同客户端都是同步的。为所有用.
bunny-rest-proxy: 基于RabbitMQ的微服务异步API
Bunny REST Proxy 是一个构建在 RabbitMQ 之上的 HTTP 消息代理。它允许服务通过 HTTP 轻松地将消息发布到 RabbitMQ 队列,并使用拉 (HTTP GET) 和推.
使用150行SQL创建PostgreSQL通用审计解决方案 - supabase
数据审计是一个跟踪表内容随时间变化的系统。PostgreSQL 具有一组强大的功能,我们可以利用这些功能在 150 行 SQL 中创建通用审计解决方案。审计对于历史分析特别有用。为了证明这一点,设想你.
分布式系统唯一主键标识符ID生成机制比较 - Encore

在构建任何分布式或非分布式系统时,您最终会处理许多数据ID标识符,从数据库行一直到生产系统版本的ID标识符。决定如何生成标识符有时非常简单;例如,您可能只是将一个自动递增ID的数字作为您的数据库中的主.
比较Apache Kafka与各大云计算的分布式日志技术 - scottlogic

Apache Kafka、Amazon Kinesis、Microsoft Event Hubs 和 Google Pub/Sub 等分布式日志技术在过去几年中已经成熟,并且在为某些用例移动数据时添加.
DB面试问题:单条记录的大量查询 - Reddit

有一个表存储了所有用户的余额信息。而很大一部分select和更新查询都与一条记录有关(例如,公司账户余额/一个机构用户经常进行交易),因此这些查询需要一个接一个地执行。你能做些什么来提高这些查询的性能.
Apache Pulsar分布式事务机制

Pulsar 事务 (txn) 使事件流应用程序能够在一个原子操作中消费、处理和生成消息。开发此功能的原因可以总结如下。随着流处理的兴起,对具有更强处理保障的流处理应用的需求也随之增长。例如,在金融行.
Rust中的后台作业 - kerkour
对于经常性工作(又名 CRON 工作),我个人使用lightspeed_scheduler: let job = Job::new("kernel", "dispatch_delete_old_dat.