Twitter架构
Twitter的特点
- Twitter一个最大特点就是用户产生大量数据,每天有7TB数据要保存。
- 使用apache Hadoop进行存储和分析数据,。如果依赖硬盘80MB/S,需要24小时才能写完7TB数。可以在62秒内对1TB数据排序,有分布式文件系统,基于Mapreduce算法。
传统方式
- 传统方式有三个:
1. MySQL的水平和垂直分区
2. 使用分布式缓存Memcached
3. 通过应用程序管理。
这些方式问题:
1.存在很多单点风险,一台服务器当机,整个应用崩溃
2.硬件密集型
3.人手密集型
4.紧耦合。
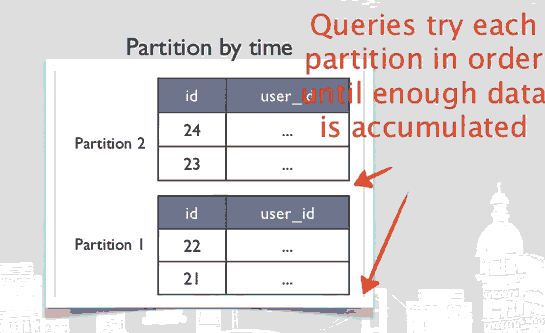
使用了memcached和MySQL的读延迟:

问题:
- 写吞吐量
- MYSQL经常死锁
- 创建一个新的分区需要手工脏活累活
使用HBase和Cassandra与MYSQL协同
- HBase容易实现输入 输出的批处理工作,Cassandra则不擅长;
- HBase在namenode中有SPOF,HBase用于数据分析,而Cassandra用于在线实时系统。
- 使用Cassandra保存所有tweets,可容错,有高的写通过率。
- 标准的读写操作用MySQL,而动态的读写用Cassandran。

Twiiter的大数据:收集数据
- scribe用于日志记录 包括监视写入HDFS的日志
- 主要用于收集数据,大数据来源。
- 前后端各种语言的操作都写入。有三十多种不同分类
- 持续与Facebook不断改进Scribe
- https://github.com/traviscrawford/scribe
- 多层次的日志记录
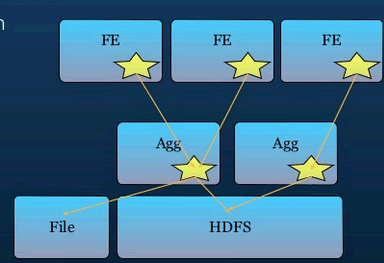
Twitter的大数据第二步:存储和分析数据
- 每天7TB数据存在Hadoop中
- 下图是对每个tweet数据进行总数统计的Map/Reduce示意:
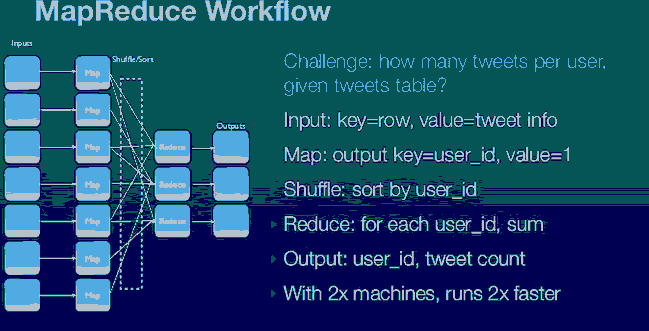
Hadoop可以解决下面两个分析挑战:
- 如何发现用户的朋友等社会关系统计?如果使用MySQL大概需要......
- 大量总数统计,类似Select count(*) from users和 select count(*) from tweets;
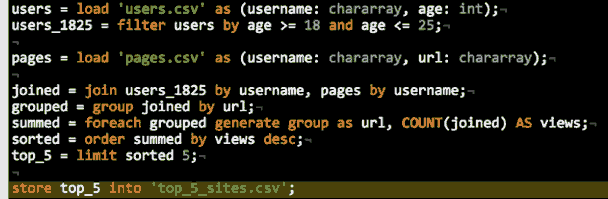
Twitter的大数据第三步:通过Pig机器学习
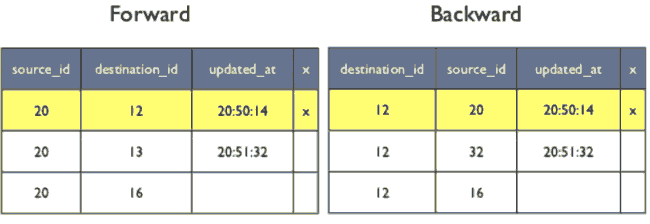
FlockDB
- https://github.com/twitter/flockdb
- 如何将一个tweet消息传递给其关注者和回复者的跟随者们?这两个人分别有大概4.7M个跟随者。
更多伸缩性scalable讨论
Facebook架构
LinkedIn架构
CAP原理和BASE思想
大数据
集群