Hive架构
Hive是一种以SQL风格进行任何大小数据分析的工具,其特点是采取类似关系数据库的SQL命令。其特点是通过 SQL处理Hadoop的大数据,数据规模可以伸缩扩展到100PB+,数据形式可以是结构或非结构数据。
Hive与传统关系数据库比较有如下几个特点:
- 侧重于分析,而非实时在线交易
- 无事务机制
- 不像关系数据库那样可以随机进行 insert或update.
- 通过Hadoop的map/reduce进行分布式处理,传统数据库则没有
- 传统关系数据库只能拓展最多20个服务器,而Hive可以拓展到上百个服务器。
Hive架构图如下:
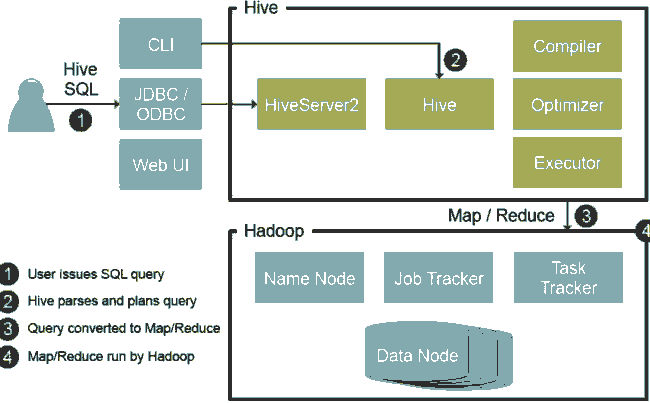
Hive目前支持的SQL数据类型和SQL语句如下:
INT
TINYINT/SMALLINT/BIGINT
BOOLEAN
FLOAT
DOUBLE
STRING
BINARY
TIMESTAMP
ARRAY,
MAP,
STRUCT,
UNION
DECIMAL
SQL语法:
SELECT,
LOAD,
INSERT
from
query
Expressions
in
WHERE
and
HAVING
GROUP
BY,
ORDER
BY,
SORT
BY
CLUSTER
BY,
DISTRIBUTE
BY
Sub-‐queries
in
FROM
clause
GROUP
BY,
ORDER
BY
ROLLUP
and
CUBE
UNION
LEFT,
RIGHT
and
FULL
INNER/OUTER
JOIN
在Hive中可使用Join语法,这是一般NoSQL的弱项,因为根据CAP定律,Join阻碍了分区,但是在Hive中Join的实现有其特殊性:
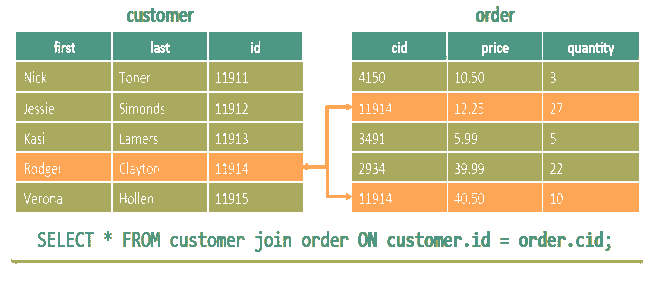
Hive的Join策略有三种,各有利弊:
- Shuffle Join洗牌式:这是一种最慢的Join策略,用Map/reduce将Join的key洗牌,然后在reduce时再连接,适合任何大小的数据集。
- Broadcast Join广播式:将所有服务器上的表数据加载到内存,Mapper通过一个大表扫描然后进行连接,优点很快,但是内存必须能容纳一个表的所有数据。
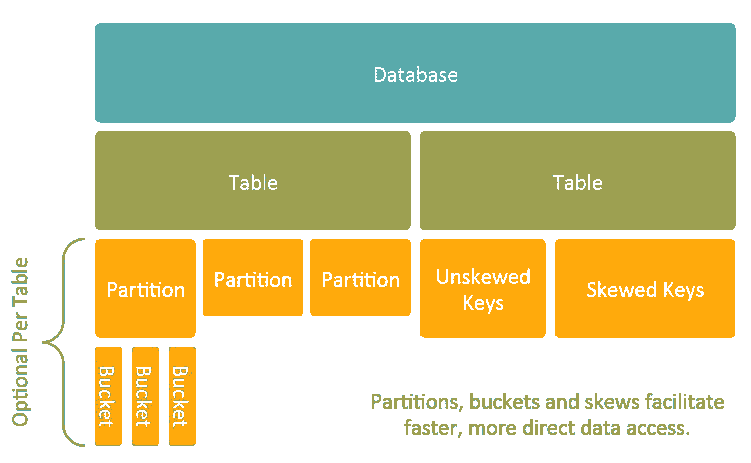
- Sort- Merge- Bucket Join:对于任何数据大小都很快,缺点是数据需要首先排序或Bucket。Bucket 只是hive 的一种hash partition 的实现,如下图,将表数据预先分区,排桶bucket,倾斜skew:
Hive文件形式:
–ORCFile
高压缩率
高性能
灵活的数据模型:maps, structs 和 unions.
Hive 0.11比0.10性能更高
– RCFile
– Avro
– Delimited Text
– Regular Expression
– S3 Logfile
– Typed Bytes
Stinger
Stinger不是一个项目或产品,而是一种提议,旨在将Hive性能提升100倍,包括Hive的改进和Tez项目两个部分。
Hive 0.11中的改变包括:
- 通过提高Hive的 map join (aka broadcast join) 激活Star join
- 尽可能折叠相邻的任务
- 提高Sort- Merge- Bucket Join(SMB)性能

Tez是一个可替换MapReduce的数据数据框架,着重于低延迟高性能,Stinger核心,Tez是可插拔的Input, Processor 和 Output,如下图。另外,YARN 的ApplicationMaster用来运行Tez 任务。
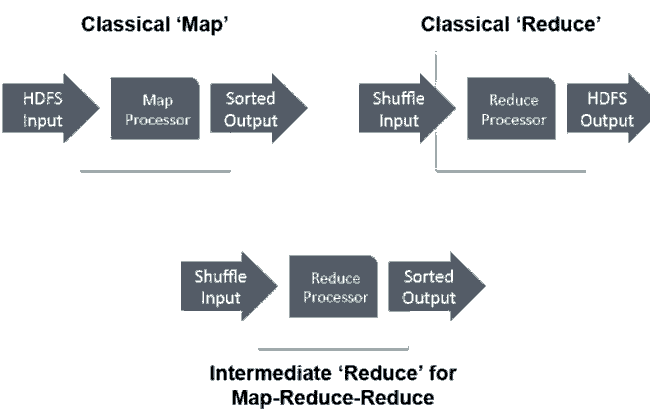
Hive/MR 和 Hive/Tez比较:执行同一个如下SQL Join语法:
SELECT a.state, COUNT(*), AVERAGE(c.price)
FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemId = c.itemId)
GROUP BY a.state
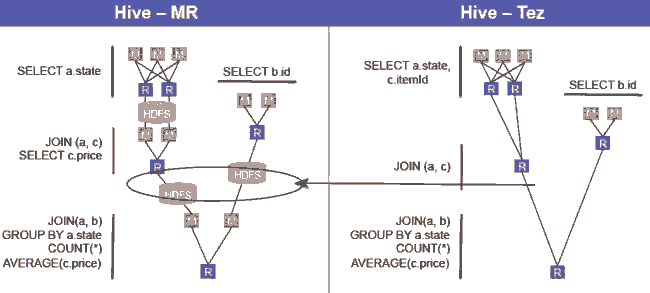
两者比较结果,Tez节约了HDFS磁盘写操作,因而性能提升。
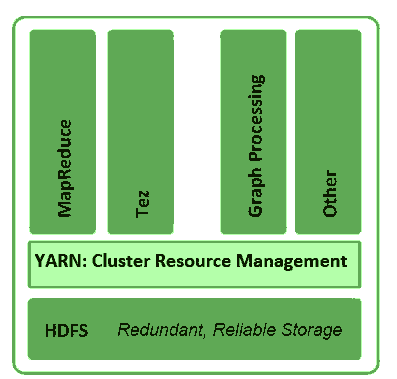
YARN类似Hadoop 2.0, 重新架构了集群资源管理,低延迟,支持流,可支持10,000+服务器。
如何使用Hive进行大数据分析
Hadoop原理和应用
大数据专题
Hadoop 中的两表join