使用机器学习进行文本处理
文档的自动分类是机器学习(ML)和自然语言处理(NLP)的一个应用案例,使得机器能够更好地理解人类语言。 通过对文本进行分类,我们可以将文档或块文本分门别类。使得文档更容易管理和排序。 手工分类和分组文档是极其费力又费时的,特别是对于出版商、新闻网站、博客或任何需要处理大量的内容。
一般来说,有两种ML技术:监督和非监督。 在监督方法中,基于之前对文档观测和分类的训练集创建一个模型,类别是预定义,训练数据集是手工分类标识好的。 按照这创建的训练数据集,分类器在手动标记的数据集上进行训练。 也就是说,分类器从那时起将能够对任何给定文档进行预测分类。
无人监督的ML技术则不同,因为他们不需要训练数据集,文档的类别事先不知道。 无监督如聚类(Clustering)等技术和主题建模(Topic Mpdelling)是用来在一组文档集合中自动发现组织类似的文档。 在这里我们要专注于监督分类的方法。
分类器是做什么的?
分类器能够进行预测,这是它们的主要功能。当一个分类器对文档进行分类时,它会预测这个文档属于哪个特别的类别或目录,会返回给这个文档分配的目录标签,依赖于分类器算法或策略的使用,分类器还提供信心指标,表达对一个文档分类标签的正确有多少信心,下面以简单例子说明分类器如何工作。
分类器如何工作?
正如前面提到,分类器是有关预测,以预测一个足球比赛来模拟说明它是如何工作的,首先我们要创建一个数据集,我们需要跟踪外面的温度,以及根据一年中天气数据集判断当天是否会下雨,然后我们才能用这些天气数据判断这场比赛是否需要进一步进行预测。
在这个案例中,我们有两个特征,温度和下雨,它们来帮助我们预测比赛是否进行?模拟如下表,在任何一个新比赛夜晚,我们能参考这个表来帮助我们预测比赛是否进行,在这个简单情况下,如果温度低于零度并且下雨或下雪,那就有取消比赛的机会和可能。
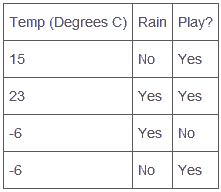
在上面这个表中,每一列称为特征feature,而Play?这一列是作为分类标签class或label,而每一行称为实例instance,这些实例被考虑作为数据点,能够使用向量代表,如下:
<feature1, feature2,…, featureN>
简单文档分类器模拟
如果使用同样类似的办法对文档进行处理,我们能使用文档中词语帮助我们对文档进行分类,举例如下:
在这个例子中,我们有三个短文档作为训练数据集合,如下:

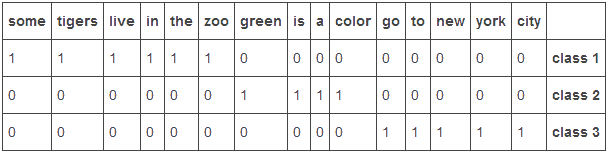
我们将这三个文档的所有单词作为我们的训练集,使用这些词语创建一个表或向量如下:
<some,tigers,live,in,the,zoo,green,is,a,color,go,to,new,york,city> class
然后对于这每个训练文档,我们创建一个向量,如果在这个文档中存在某个词语就分配1,否则分配0,如下进行标签分类,表中class1 class2 class3对应上面三个文档。
当一个新的文档包含"Orange is a color"出现时,我们将创建一个新的词语向量来表示哪个词语出现过:

我们比较这个unknown class文档的向量与前面代表三个文档class的向量,我们会看到这两个文档最相似的向量。
比较unknown class和class1,对比上下数字0和1,上下都是相同0或1的表示匹配,有6匹配:
< 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0 > class 1
< 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0> Unknown class
比较unknown class和class2有14匹配:
< 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0>class 2
< 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0> Unknown class
比较unknown class和class3有7匹配:
< 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1 > class 3
< 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0> Unknown class
这就有充足理由将新文档标记为和Class2归为同一类,这是非常简单静态自然语言处理方法。
真实世界的分类器
一个真实世界的分类器有三个组件,让我们彼此独立的了解他们。
1.数据集
正如前面静态自然语言处理方法一样,我们需要一个被收购标签为某个目录的文档集合作为数据集,数据集的治疗对于静态NLP分类器组件非常重要。
数据集需要足够大每个类别下有很多文档,举例,我们希望分类文档到500个可能目录,你也许需要每个目录100个文档,这样整个至少需要50,000文档。
数据库也需要高质量,这是使用文档之间的类别目录有非常清晰的区别。
1.预处理
在我们的简单示例中,在创建文档向量时我们给予每一个词同等重视,我们可以做些预处理来决定这些词语对于文档的权重的不同,一个通用办法是TF-IDF(term frequency - inverse document frequency:词频率-逆文档频率),TF-IDF权重是随着某个词语在该文档中粗线的次数而增加的,但是随着在整个多个文档中出现次数越多而逐渐减少,这有助于降低在整个多文档反复出现词语如"a"或"it"的权重。
1.分类算法和策略
在我们上面的案例中,我们使用分类文档的算法非常简单,我们是通过比较向量匹配的数量来看看两个文档是否相似,在真实世界中,我们也许将一个文档标识为多个目录,或者在一个给定的目录类型中,我们会给一个文档分配多个标签,我们也许需要一个分类taxonomy层次结构。
有很多分类器算法如Support Vector Machines (SVMs), Naive Bayes, Decision Trees决策树等。