优步Uber提供按需出租车服务,只需按一下按钮。在本文中,我们将探讨 Uber 背后特定功能的工程设计。
计算预计到达时间
当你拿出你的手机;打开优步应用并叫车,然后那些聪明的小算法会告诉你司机需要多长时间才能到达。预计到达时间在大多数情况下是相当准确的。那么优步是如何做到正确的呢?
Wandile 是约翰内斯堡南部的一名优步司机。我也住在约翰内斯堡南部。当我叫出租车时,我的设备和 Wandile 的设备上会显示一张地图,上面有我们的位置。
背景中的数学如下;
城市是边和节点;
节点代表交叉点,边是街道。在计算机科学中,我们称这些为图形问题。
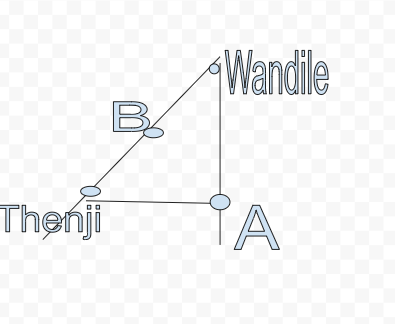
上图代表我的位置和我的司机 Wandile 的位置。点是节点(交点),线是边(街道)。我们在计算机科学中称这些图。现在,Wandile 到我所在位置的路线更快?
如果我们要使用 Dijkstra 算法,那么我们需要计算所有选项,同时积分速度。如果 Wandile 和 A 之间的限速是 80km/h。Wandile和B之间的限速是20km/h,B和Thenji之间的限速是10km/h。
80 公里/小时的边将比合并的 30 公里/小时的边更受青睐。
这是根据 Dijkstra 的算法。但速度不是我们唯一的问题,我们必须考虑交通。不要忘记是否,例如极端降雨或降雪。
这种方法对于向客户提供准确的实时 ETA 是不可行的。这已被计算机科学家创造为 NP 完全问题。
更好的方法是使用历史数据进行 ETA 计算。这些使用来自以前旅行的数据集并玩弄概率。
只有当优步在一个新城市推出他们的服务时,才需要图表和他们的算法。在一个新城市运营,我们没有足够的数据来训练算法来识别历史模式。在这种特殊情况下,我们将城市分割成更小的部分,创建更小的图形。这将减少我们的算法运行时间并提供更准确的 ETA。
一旦解决了映射和路由问题,就可以继续寻找客户并将其与司机进行匹配。
寻找和匹配客户与司机
一旦我提出请求,最近的驾驶就会被正确地ping通被呼叫?
错误!
Langa 是离我最近的司机,但 Wandile 被系统 ping 通了。这称为批量匹配。这是为了减少总等待时间而引入的。
起初,系统并不是很智能,它匹配了最近的司机,也就是我的 Langa。
但是这不是现实世界的反映,请求会同时发生。
这是一个更准确的反映:

Langa离我5分钟路程,接受请求,被派遣。但是我们还有来自城镇另一边的亲爱的朋友 Dee 要求搭便车。Wandile 距离 Dee 有 10 分钟路程。
这两个请求的总等待时间为 15 分钟。这就是我们所说的计算机科学中最坏的情况。让我们重新计算一下!
Langa 距离 Dee 仅 3 分钟路程,Wandile 距离 Thenji 7 分钟路程。这给了我们 10 分钟的总等待时间,比其他等待时间要好。
批处理算法的作用是尽可能减少等待时间。如果 Langa 与 Dee 匹配,Thenji 与 Wandile 匹配,则总时间减少 5 分钟。
处理大数据
- 贮存:
一个行程至少存储在2个数据中心,主数据中心尽可能靠近行程。如果旅行发生在约翰内斯堡,数据中心将在约翰内斯堡或开普敦。
备份数据中心将位于欧洲或亚洲。当我旅行时,来自我的设备和驱动程序设备的旅行信息将存储在南非的主要数据中心。
现在由于某种原因南非数据中心下线,那么行程信息/数据将被发送到欧洲的备份数据中心。一旦我们的南非数据中心重新上线,信息就会同步回南非数据中心。
最坏的情况是,如果两个数据中心都处于离线状态,那么您就会看到消息离线。
混合使用 SQL 和不使用 SQL,使用 Apache Cassandra 不使用 SQL 和 Uber 分叉 MySQL,它是无模式的。
对于大数据分析,hardoop 用作数据仓库。数据仓库与主系统解耦。如果是离线的,那么应该不会影响 Uber 的日常业务。
- 缓存
我认为这涵盖了 Uber 背后的工程基础知识。也许下次我们可以深入挖掘并讨论其他革命性的功能。