FACEBOOK架构
Facebook的web层因为历史原因:
- 使用PHP,简单易学
- 问题是消耗比较大
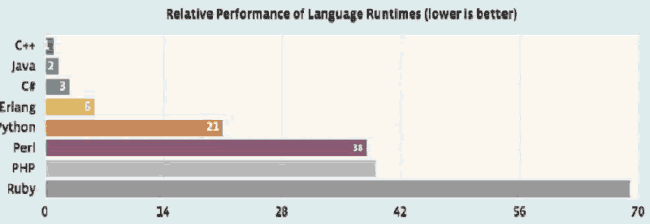
优化PHP
- APC提升:懒加载
- 引入缓存,memcache
- 异步化事件处理
- 记录 状态收集和监视
- 使用Hihop开源PHP库,降低百分之50 CPU=使用。
Tornado
- 是一个使用Python编写的非堵塞服务器

Facebook的开源架构

整体架构
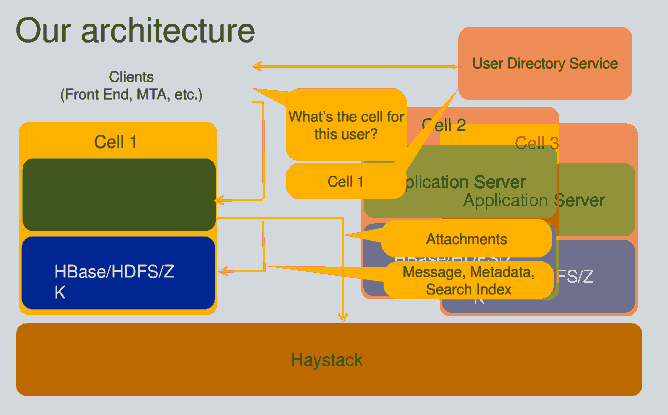
Facebook数据存储
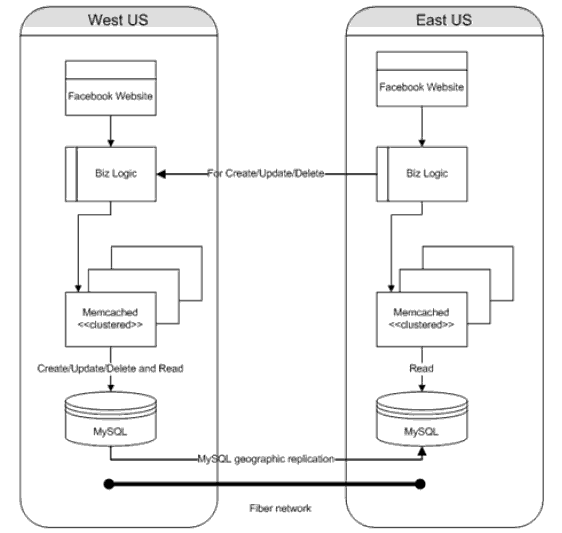
Memcache使用
- 每个线程分享TCP/UDP的连接池
- 使用UDP降低网络开销 Multi-get
1.UDP Socket锁 Linux kernel使用socket锁用于多线程
2.分离UDP sockets 传送回复 replies
- Memcached’s 状态使用全局锁
- 1.状态收集迁移到每个线程,on-demand聚合合并结果。
- 2.伸缩memcached 到8-core CPU的8 threads。
Facebook采取HBase+Hadoop方案
HBase存放消息

每月消息数据量

消息数据模型特点
- 中小型数据 使用HBase,如消息元数据 搜索索引 小消息内容
- 附件或大的消息数据,使用HayStack,如图片和视频等。
Facebook文件存储Haystack
- HTTP server : 使用开源libeventlibrary 提供简单的 evhttpserver。
- Photo Store Server : 负责接收HTTP请求,然后翻译成相应的 Haystack存储操作 (将所有元数据加载在内存中)
- Haystack Object Store : Index(meta data) + Data
- Filesystem(XFS) : Haystack object stores是运行在每个最大容量10TB的文件中
- •Storage(Blade server): 2 x quad-core CPUs, 16GB –32GB memory, hardware raid controller with 256MB –512MB of NVRAM cache, 12+ 1TB SATA drives
Facebook Haystack效率性能
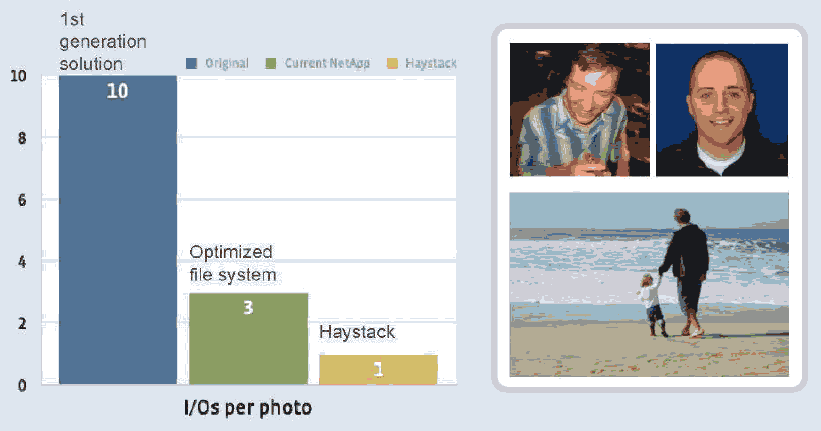
但是Haystack没有开源,参考的有:
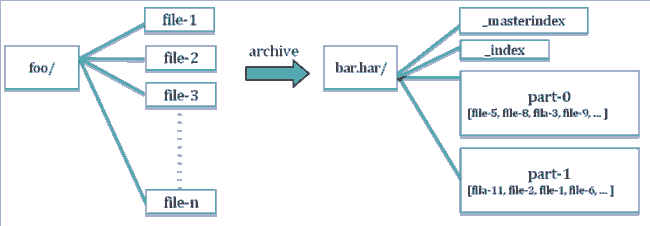
Hadoop Archive: File Compaction for HDFS
Hadoop Archive: File Compaction for HDFS
Hadoop Archive三个部分
- 定义文档格式的数据模型
- 允许透明访问的文件系统接口。
- 使用MapReduce作为job 创建文档的工具
- 文档名称为har
Facebook的数据挖掘 大数据分析 Scribe
- 一种分布式记录文件收集的服务。
- Scribe被设计运行在每一个数据中心节点作为守护流程。
- 将很多机器上运行处理的日志推到中央聚合池。
- 由于频繁运行,重要的设计点是让其消耗尽可能少的CPU。
- 收集日志数据提供给Hive进行分析。
- https://github.com/traviscrawford/scribe
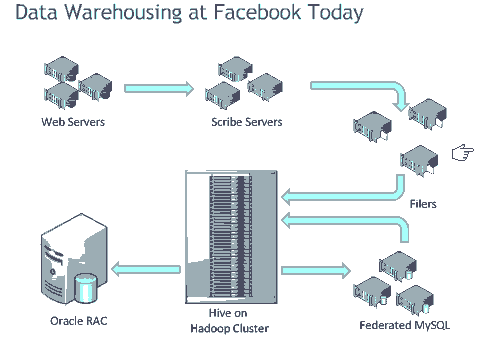
Facebook数据仓库架构图
Hive
- Facebook用来实现用户数据统计,如点击数 浏览数 广告展示等等,英文原文PPT。
- 使用Hive的背景:
- 1. 2008年5月每天200G,压缩后2+TGB行数据
- 2. Hadoop比ACID有更好的可用性和伸缩性。但难以使用。
- Hive通过脚本形式来使用Hadoop,如SQL/python.
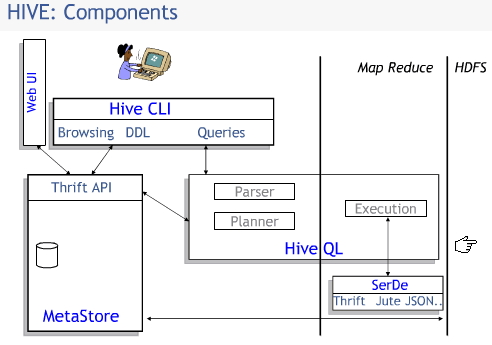
Hive组件结构图
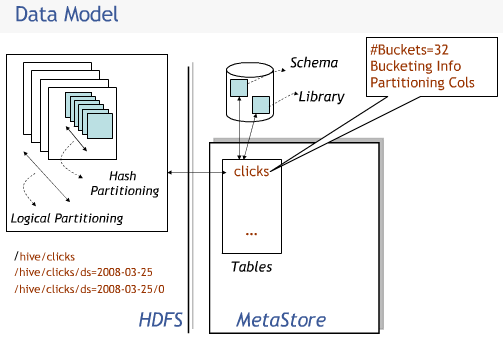
记录点击数的数据模型图
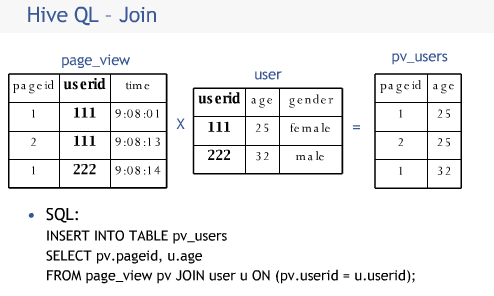
Hive使用Join处理数据关联关系
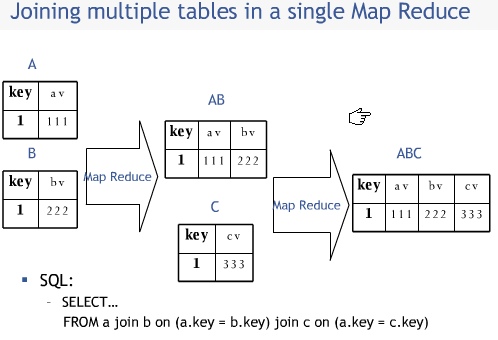
Join和Map/reduce之间关系
CAP原理和BASE思想
集群
伸缩性scalable
大数据
云计算
Netflix的亚马逊云计算平台使用
Twitter大数据
LinkedIn架构