数据网格
Avanza 银行数使用据网格案例
- Avanza银行是一家瑞典的银行,让投资者易于作出股权交易和基金交易。它通过自己的在线银行提供很好工具给投资者使用。
- 当前在线系统是典型的基于Java/Jsp和Spring的Web网站。
- 当前大部分操作是读取,主要可伸缩性的挑战是并发读操作,采取的是目前很多系统采取的架构LAMP + Memcached,第一次从数据库中获取,以后直接从缓存中获得。
Avanza 银行挑战
- 新的系统改造将设计目标为实时性和社会性领域,这就意味着很多内容将不是由网站管理者来产生,而是由用户自己来创造,由此带来新的大量的流量和活动。
- 系统将改变到以流量负载为主要目标。
Write scaling 写伸缩挑战
- 数据库之前缓存(side-cache)的问题是带来副作用:由于大量数据更新,导致缓存中的数据过时,同步缓存增加了开销。
- 使用Oracle RAC 并没有象它宣称那样,而且成本非常昂贵。
- 使用多年的关系数据库模型,将这些关系数控模型迁移到NoSQL架构,将耗费几年的努力。
实现读写伸缩扩展重构
- 不重写整个系统,圈定需要伸缩的范围。
- 保留数据库,在数据库之外进行读写伸缩,这样不必改变数据库表结构。
- 将数据网格In Memory Data Grid(IMDG)放在数据库之前。IMDG中包含所有热点表或数据表记录,在线Web应用将访问IMDG而不是数据库,IMDG可分布地将读写操作分散到集群服务器上。
何为数据网格
- 使用write-behind策略减少过多的同步负载。将IMDG中数据持久更新到下面的数据库中是使用异步的批操作。这是通过一种内部查询机制internal queuing mechanism (redo-log))实现的。
- 切分数据带来好可伸缩性,但是这不代表改变数据表结构,在IMDG数据网格中保存的是另外一种不同于数据库表格式的可切分数据格式应为一种领域对象模型格式。
- 使用O/R mapping等框架将IMDG中对象数据和关系数据库进行映射,例如Hibernate或OpenJPA。

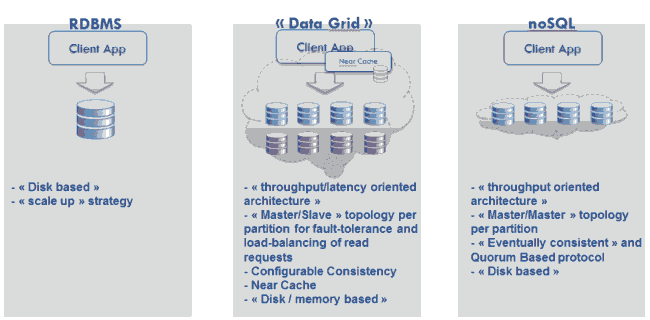
数据网格和NoSQL区别
面向延迟性latency架构,还是面向吞吐量throughput架构?
数据网格是采取内存作为主要存储,这样就带来很低的延迟;
NoSQL则是主要为web-scale工业也就是Web网站系统服务的,用户能够感受的延迟不是非常重要,比如几秒延迟,人是感觉不明显的,这时你不必相应快速,而是应该应付越来越多的请求,也就是解决吞吐量。
Data Grids / Clustering产品
Coherence
Terracotta
GigaSpaces
GemStone
Hazelcast
Infinispan
GigaSpace

IBM Extreme数据模型

数据模型的读和写操作:


为什么使用数据网格?
集群专题
更多伸缩性scalable讨论