深度学习之卷积神经网络教程
本文我们介绍深度学习与神经网络中卷积算法如何应用在识别图片中?该文是假定你对神经网络和深度学习有一定认识,如果不熟悉,可见本站 “神经网络最基本形式感知器的入门教程”。
首先我们从一个简单任务开始,让机器能够识别数字“8”,我们需要大量手写体的“8”供机器学习和训练使用,那么神经网络将这些大量手写体"8"输入时,计算机是如何识别呢?它是识别每个像素有多黑:

为了将图片喂给神经网络训练。我们将上面像素18x18的图片看成是324个数字的数组,上图中代码8的有324个数字,与数字8轮流显示,我们输入神经网络的数据就是8这个表象后面的324个数字。
为了处理324个输入,我们需要让我们的神经网络有324个输入节点:
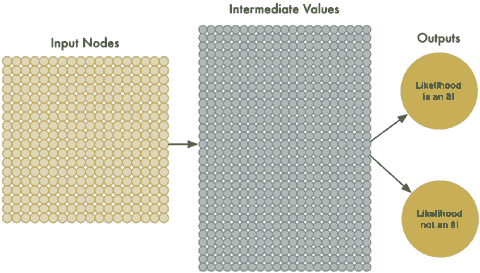
现在我们的神经网络有两个输出了,第一个输出是预测图片可能是“8”,而第二个输出是预测图片可能不是“8”,通过分离对象两个不同的类型,我们能使用神经网络来分类对象进入组。
到目前为止,我们已经训练了神经网络能够识别数字8了,好像不是很复杂?
问题现在来了,当数字8在图片中间时,神经网络容易识别,但是如果位置稍微偏离中间它就无法识别了。
为了了识别图片上任何一个位置上数字8,首先想到的办法是扫描整个图片,以找到数字8的位置。这种办法称为sliding窗口,但是效率不够高,你需要检查不同大小的图片很多次才能找到数字8。
现在我们还是回到训练神经网络的思路上,我们用8的位置不同的图片去训练它:

更多数据使得我们的神经网络解决问题难度增加,但是我们能够通过使得网络变得更大,学习更复杂的模式来解决。为了使得网络变得更大,我们堆积起多层如下:
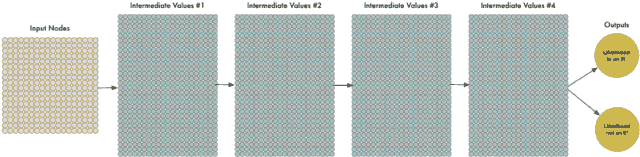
我们称为这是深度神经网络,因为它比传统的神经网络有更多层。
这个注意其实早就有了,但是只有最近才使得深度神经网络实现有可能,因为以前速度太慢了,而现在我们只要使用3维图像处理卡替代正常处理器来处理就可以了,比如NVIDIA GeForce GTX 1080就是的训练神经网络变得非常快。
但是即使我们增大了神经网络,并用3维图像卡来快速孙俪,问题还没有解决,我们需要神经网络变得更聪明。
神经网络会识别数字8在图片上部和数组8在图片下部,虽然能够识别出来,但是它不认为这两个数字8其实是同一个对象,也就是都是数字8,也就是因为8位置不同导致神经网络会误以为这是两个不同的数字。
应该让神经网络聪明地知道无论数字8在图片哪个位置,它们都是相同的数字8,现在卷积算法上场。