使用TensorFlow实现深度学习原理介绍
本文介绍如何使用TensorFlow实现深度学习的几个基本概念和原理。
神经网络是从数据中训练函数,它试图理解输入的数据,实现相应的输出,从而训练出一个学习的函数,举例来看,输入的是一个图片的原始像素,输出的是一个词语“cat”。

而深度学习则是在训练一个函数学习过程中包括自动产生许多抽象层,每个层有神经元,每个神经元实现简单的数学函数,而成百上千个这些函数的组合则会更加强大。
每个层里面的每个神经元是彼此的,它们形成模型中多个层次,这样能对发现的特征形成有趣的组合,机器学习模型中神经元将学会彼此协作完成一个复杂任务。
以上面案例来看,输入的是一系列像素集合数据,不同层的一些神经元会激活活跃,在最后层它也许会猜测是否是'cat'(猫),然后根据结果,我们会微调不同层中神经元的权重,这样最后模型会基本学会正确预测结果答案。
这些被训练的函数是简单的,类似矩阵乘法之类,这些函数的组合,成百上千组合会形成一个强大的深度学习模型,帮助识别输入中的一些亮点,这些输入或者是图片 或者是声音,或者是一段视频或者是简单文字,这些模型也就是数学函数有许多浮点操作,是计算密集型,所以会耗费CPU,一般使用图形处理器GPU来完成。
神经网络有一些重要特性,如果使用更多数据,更大模型或更多计算进行训练会变得更好,更好的算法和好的技术会对神经网络产生的结果有出奇的帮助,但是更重要是,因为工作于大型数据集,从CPU核数扩展到服务器的伸缩性非常重要。
如果某个领域训练出了机器学习模型,它也适用于其他领域,比如解决了图片处理问题的模型也能用于语音处理领域,只需要付出稍微一点训练即可。
TensorFlow
这是一个由Google推出的开源系统,创建了一种标准途径用于表达机器学习思想和计算,是一种可扩展的产品可部署的系统。
TensorFlow实际是一个图执行引擎,能够在不同各种设备运行这些图,能够在不同设备之间平滑移动,比如你能够使用许多GPU在数据中心训练模型,同样也可以在智能手机上运行同样的模型,tensorflow核心是使用C++编写。
使用C++或Python前端可以驱动TensorFlow进行计算。
mnist 是TensorFlow项目中hello world的机器学习演示项目,是一些图片和文字数字的数据集,你能够建立一个机器学习模型从中辨识出文字和数字。
TensorFlow有一个特性自动区分差别,比如我们有一个机器学习模型,使用一个loss函数来优化,首先我们要最小化loss函数,这样你区分图,就能知道模型中什么更新已经完成,这样,下次,模型能够预测出它是一个狗,比如你为了最小化entropy loss,你可以使用梯度降低优化器训练模型。
TensorFlow是一个图执行引擎,图中每个节点是一个操作,跨这些节点流动的edge其实就是一种多维数组,各种类型的多维数组,也就是tensor。
它的计算是一个数据流,可以在GPU和不同CPU之间分布运行:
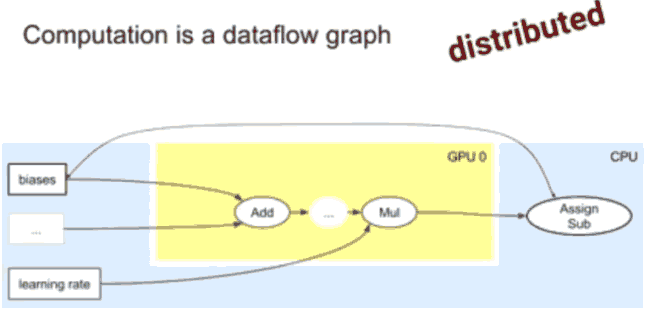
TensorFlow会将图计算中接受和发送节点发布到不同机器上,也能够在不同设备上接受,这些发送/接受 节点/操作使得tensorflow分布,这些发送/接受操作管理着所有通讯,实际是在内部自己完成的。