大数据专题
使用MapReduce实现Join的原理
假设有两个表雇员和部门如下:

下面是使用reduce处的join实现:
SELECT Employees.Name, Employees.Age, Department.Name FROM Employees INNER JOIN Department ON Employees.Dept_Id=Department.Dept_Id
实现原理如下:
Map处是为每个表中有同样部门id的记录产生join谓词,然后在reducer处将实现同样部门id的Join。
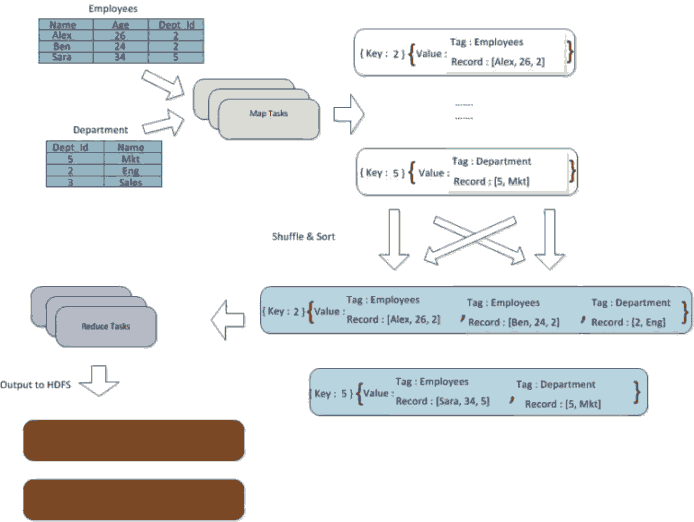
下面是Map函数的伪代码:
下面是reduce 的伪代码:
Map处的Join(Replicated Join)
在小表上使用分布式缓存,为了实现这个目标,一个关系大小必须正好合适放入内存,小表能够在每个节点复制,加载到内存中。发生在Map处的Join由于没有reducer加入性能很快,因为避免了所有数据跨网络进行交换。小表能够输出到哈希表,这样可以按照Dept_Id查询,伪代码如下:
在过滤后的表使用分布式缓存:
如果较小的表不适合的内存,有可能修剪它的内容,特别是过滤表达式已经在查询中指定。考虑下面的查询:
SELECT Employees.Name, Employees.Age, Department.Name FROM Employees INNER JOIN Department ON Employees.Dept_Id=Department.Dept_Id WHERE Department.Name="Eng"
在这里,从Department表筛选出一个较小的数据集,条件是具有部门名称中有Eng的记录。现在,它可能会在Map边Join做复制这个较小的数据集。
Replicated Semi-Join
使用 Map的过滤的Reduce处的Join
小表的过滤后还是不适合放入内存,但是我们能够只使用过滤后的Dept_Id记录,在map这边的缓存能过滤出数据,然后发到到reduce那边。
使用Bloom过滤器
一个bloom过滤器是用于测试一个集合中元素的容量,如果Dept_id这些值能被放入这个过滤器,那么这些id指就能够被传递,这个过滤器可以将id复制到每个节点。在map这边每个记录都是从小表中获取,bloom 过滤器来检查Dept_Id是否存在在bloom filter中,如果是就发射 emit到reducer那边,bloom 过滤器能够确保结果的精确性。