大数据主题
Storm - 大数据Big Data实时处理框架
上页
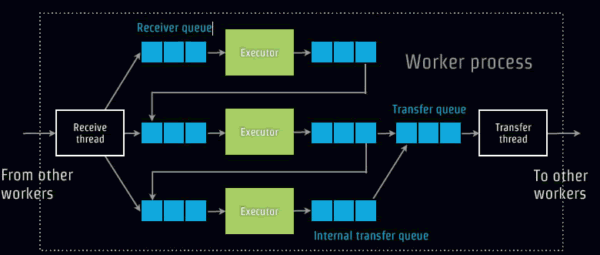
现在开始分析Storm内部架构,首先看看Work之间的消息传递,如下图,
Work之间的通讯是通过ZeroMQ,但是Yahoo后来发现使用异步的Netty能够提升Storm一倍性能,数据使用Kryo进行序列化,本地通讯使用Lmax的Disruptor ,内部无需序列化。
容错性
如下图,executor发送心跳到Zookeeper,Supervisor从本地文件读取所在服务器的worker心跳状态,然后同步分配发送到zooKeeper。Nimbus监控集群状态。这样能确保worker一直活着。
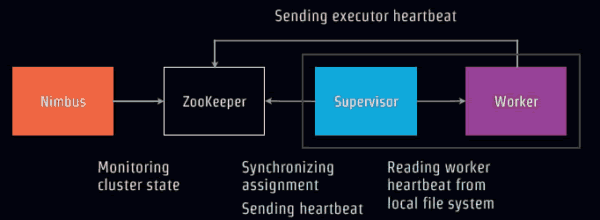
如果某个节点也就是服务器没有心跳,Nimbus将重新分配新的服务器上线工作。
如果某个节点服务器中work没有心跳,那么Supervisor将负责重启线程。
如果某个Supervisor完蛋,整个处理正常,但是分配的同步工作就无法进行了。
如果Nimbus崩溃,整个系统可以运行,但是拓扑分配工作无法进行了。
可靠性:确保消息被处理
public class RandomSentenceSpout extends BaseRichSpout {
public void nextTuple() {
UUID msgId = getMsgId();//用消息ID发送消息
collector.emit(new Values(tweet), msgId);
}
public void ack(Object msgId) {
// Do something with acked message id. 确认消息ID
}
public void fail(Object msgId) {
// Do something with failed message id. 消息ID失败了
}
}
public class SplitSentenceBolt extends BaseRichBolt {
public void execute(Tuple input) {
for (String s : input.getString(0).split("\\s")) {
collector.emit(input, new Values(s));
}
//当整个词语都被切分后,确认输入的事件已经被接受处理。
collector.ack(input);
}
}
下面是一个Ack确认流程,注意到Acker Implicit bolt。
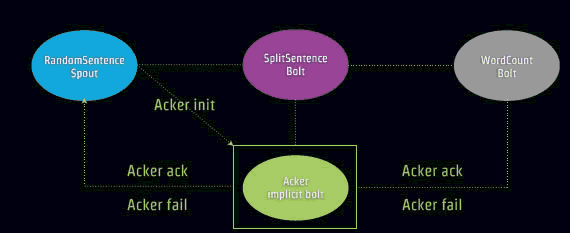
对于一个树形结构Tuple流,也就是Tuple里面嵌套Tuple。
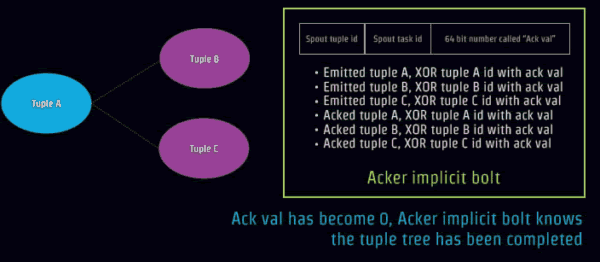
如果事件被下一个节点成功接受和处理,这个节点将更新相应初始事件的签名,通过异或操作,将输入事件的ID和所有基于该输入事件产生的所有事件的ID进行异或操作,如下图,事件 01111 产生子事件 01100, 10010, 和 00010, 这样事件 01111的签名是11100 (= 01111 (initial value) xor 01111 xor 01100 xor 10010 xor 00010).
当Ack值变成0,Acker implicit bolt就知道tuple树形数据集合全部被处理完成,一个事务确保可靠结束。例如语句分成一个个单词全部完成。
Storm的集群设置
设置ZooKeeper cluster
(1)安装Storm依赖的库包到服务器上:
- ZeroMQ 2.1.7 and JZMQ
- Java 6 and Python 2.6.6
- unzip
(2)下载解压Storm。
填写强制性配置到storm.yaml
用storm脚本启动守护流程的监督
通过Web界面能够观察管理拓扑网络情况和组件情况。
Hadoop打数据批处理架构
Storm专题
大数据专题